
企业级 RAG 与 Agent:从拼接管线到可优化的整机#
ChatGPT 之后,大量团队把「检索 + 大模型」推上生产,却很快撞上同一堵墙:prompt 在场景漂移时脆,修 A 坏 B;向量库、reranker、生成器各自调参,没有人对最终用户是否满意负责。Contextual AI 联合创始人兼 CTO Amanpreet Singh 的论述(下文未单独标注处为演讲者观点)把问题框在 RAG 2.0、主动检索、偏好学习(KTO/APO) 与 LMUnit 式评估 四条轴上——与 Weaviate 向量基础设施形成生态互补,但本文只讨论可迁移的工程判断,不复述对谈时间线。
公开材料与播客表述并不总一致:例如官方评测产品名为 LMUnit(字幕常误听为「LLLLM Unit」),开源 checkpoint 为 70B 级专用打分模型,与口语里的「小模型」有出入;BIRD text-to-SQL 在 官方博客 中写为曾 overall #1、当前 top 5(dev 完整配方约 73% execution accuracy),不宜笼统写成「现行 SOTA」。下文在冲突处会标明证据边界。
问题空间:为什么「能 demo」不等于「能扛流量」#
为什么:企业知识往往远在 context 窗口之外(嘉宾举例约 40 亿 token 量级、生产约 10k queries/min——无法从公开文档核实,仅作规模直觉)。在此量级下,5–10 条 few-shot 的 agentic RAG 演示可以工作,但 QPS 与偏好分布一拉开,失败模式无法全部写进 prompt。
机制/约束:系统瓶颈常在 分布漂移(新文档、新术语、新合规规则)与 反馈稀疏(生产 thumbs 往往极度偏负——嘉宾称约 90% 负 / 10% 正,亦为演讲者经验,无公开统计)。纯 test-time 多轮检索不更新权重,每次请求仍是 cold start,域内缩写(如企业内 SAT 非 Scholastic Aptitude Test)难以靠 in-context 纠正持久生效(演讲者观点)。
怎么做:把优化目标从「单次回答像不像训练集」改为「轨迹 + 终局反馈」——简单 RAG 也可视为 query → retrieval → generation → feedback 四元组;复杂 Agent 则是工具调用链上的同一闭环。
常见误区:把「能调用检索工具」等同于生产就绪;把 latency 优化理解成「少检索几轮就好」——多轮时错误会在长上下文中复合(演讲者观点),与 DeepSeek-R1 所强调的可验证奖励 + 轨迹筛选是不同杠杆。
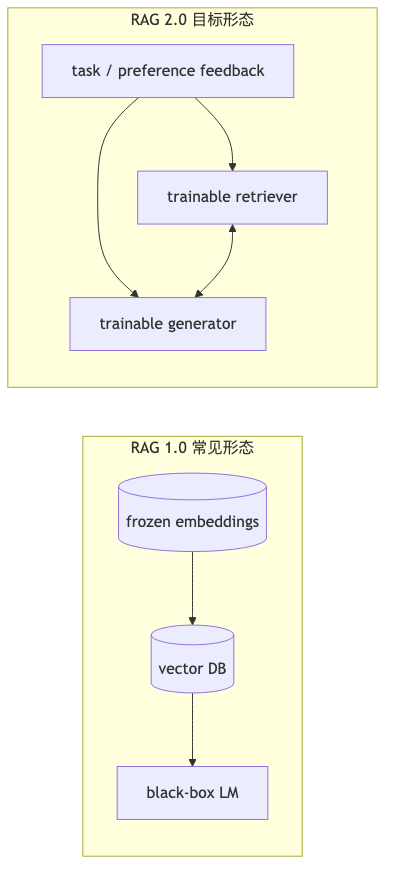
RAG 1.0 与 RAG 2.0:拼接 Frankenstein 还是联合优化#
为什么:原始 RAG 论文(Lewis et al., 2020)已用 differentiable access 与可微调神经检索器做知识密集型任务;工业界常见做法却是 frozen embedding + 向量库 + 黑盒 LM,检索器收不到生成错误的梯度——嘉宾称之为 RAG 1.0 的「Frankenstein」拼接(与 Contextual AI 对 RAG 2.0 的定义 一致:pretrain / fine-tune / align 全组件,并对 LM 与 retriever backprop)。
机制/约束:端到端不等于处处反传:可用领域 proxy 任务 或环境奖励近似终局目标(演讲者观点)。与只改 generator system prompt 相比,联合优化让 retriever 从「答错题」中学习该拉哪段语料——但需可扩展的数据与算力,且 discrete 超参(chunk size、top-k)组合空间巨大,嘉宾称内部 R&D 有应对,本期未公开方法。
怎么做(概念层):
# 反馈闭环(示意,非 Contextual 专有 API)
for (query, user_label) in production_logs:
trace = rag_pipeline.run(query) # retrieval + generation (+ tools)
loss = alignment_objective(trace, desirable=(user_label == "up"))
update(retriever, generator, optional_reranker_head)
常见误区:把 2020 论文直接贴上「RAG 2.0」商标;把「用户 thumbs」与 RAG 2.0 官方叙事混为一谈——文档强调 benchmark 级联合训练,生产 thumbs 闭环更多靠 KTO 等平台能力(见后文)。
检索范式:retrieve-then-read、multi-hop 与主动检索#
为什么:静态「查一次、读一次」在财年/日历歧义、工具返回后再改查询等场景会失败——嘉宾以金融文档为例:需先看语料再决定下一轮 query(演讲者观点)。
机制/约束(文献可核对部分):
| 范式 | 代表工作 | 行为摘要 |
|---|---|---|
| retrieve-then-read | RETRO、Fusion-in-Decoder (FiD) | 检索 chunks / 多 passage 后一次条件生成;FiD 增加 passage 数可提分,但非 agentic 多轮工具调用 |
| condensed multi-hop | Baleen | 潜在 hop 排序 + condensed retrieval,仍不同于「见文档后改 query」 |
| active / orchestrated | 平台 GA 文案 | agent 按对话上下文编排检索与生成——产品表述,无统一论文定义 |
怎么做:在置信度低或冲突检测触发时发起第二轮检索/SQL;把 tool 输出写入 trace 供后续优化。structured 数据路径上,Contextual 宣称 text-to-SQL 在 BIRD 上为 best fully-local,完整 dev 配方约 73% EX(execution accuracy,见 BIRD 论文)——与嘉宾口语「sort of state-of-the-art」相比,写作应加 时间戳与 local/API 区分。
常见误区:认为 multi-hop 并行拆 query 就够;忽视非参数工具上限(如 Notion API 只搜 title)——系统只能在工具能力内学「更少犯错地使用」,不能魔法超越 API(演讲者观点)。
Agentic RAG、test-time 计算与权重专精#
为什么:Agentic 卖点(多轮检索+推理)在演示中靠 few-shot 即可惊艳;生产则要面对异构用户偏好,无法把海量失败案例全部塞进 prompt(演讲者观点)。
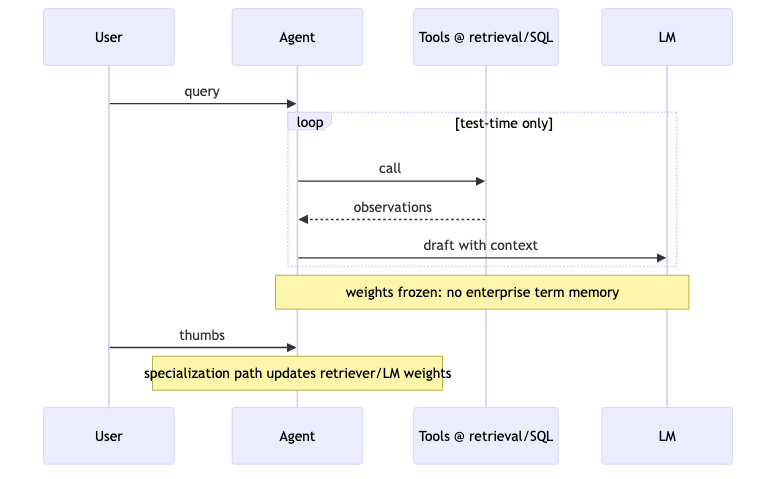
机制/约束:test-time 增加 compute(更多检索/反思)不改变权重;企业术语无法沉淀进参数,则每次仍是通用先验 + 临时 context。嘉宾主张更稳妥路径是先把语料知识蒸馏进权重,再服务(演讲者观点),与 DeepSeek-R1-Zero「可跳过 SFT、用 RL 激励推理」的叙事形成对照——R1 侧强调 verifiable tasks 与强基座,嘉宾归纳的长文本 ~50k vocab 动作空间与 rejection sampling 非 R1 摘要逐句结论。
怎么做:记录完整 trajectory(工具调用、检索片段、中间草稿),用验证信号(见下节 LMUnit)筛轨迹再更新;16 条人工偏好 → unroll 大量轨迹的方向,与 OpenAI RL fine-tuning API 类能力同构(演讲者对未来样本效率的判断)。
常见误区:为降延迟盲目减少检索轮次,或为覆盖盲目增加轮次而不做轨迹级 eval;完全去掉 parametric knowledge 使模型退成「只复读检索片段的壳」——仍需 in-house groundedness / conflict resolution 微调(演讲者观点)。
评估:从字符串相等、LLM 评委到 LMUnit#
为什么:生产若达千级 QPM,用 GPT-4 级评委评每条回答,成本可与生成相当(演讲者观点)。非 ML 客户更需要「全局单元测试」:风格、离题、guardrails、groundedness、attribution——而非单一 BLEU 式字符串相等。
机制/约束:LMUnit 论文 提出 natural language unit tests:输入 prompt + response + unit_test(自然语言准则),由 LMUnit scoring model 输出 1–5 连续分(官方表述),可阈值化为 pass/fail,但主接口非二元。研究页称相对 GPT-4o / Claude 3.5 Sonnet 在 unit-test scoring 上高约 9%,RewardBench 93.5%;开源 ContextualAI/LMUnit 提供 Llama 3.1-70B 等 checkpoint——与「小模型、低延迟」口语冲突,写作宜用「专用评测模型」。
怎么做:
# 概念示例:LMUnit 范式(见官方 pip install lmunit)
score = lmunit.evaluate(
prompt=user_query,
response=answer,
unit_test="回答必须引用文档 ID;不得编造未检索到的政策条款。",
)
pass_ = score >= threshold # 阈值由业务校准
多维「信用报告」:groundedness、attribution、style 等轴分别挂 rubric。主持人提及 Who Validates the Validators?(Shreya Shankar 等)——嘉宾立场是修 broken metric,而非无限叠评委(对话引用,原文本期未核对)。
常见误区:把 LMUnit 分数当作通用「人类偏好」代理;忽视评测器自身 70B 部署成本;合成 QA 在极偏域连合理问句都写不出(嘉宾 SAT 域术语例,演讲者观点)——但上线 真实 user query 分布 仍可作为 query 侧 proxy。

偏好学习:KTO、APO 与「改 prompt 的上限」#
为什么:RLHF 把句子级偏好压成标量 reward,信息损失大,却「居然有效」(演讲者观点)。企业生产常见只有 thumbs,且极度不平衡;KTO(Ethayarajh et al.)明确可从 desirable / undesirable 二元信号 学习,无需 pairwise「A 优于 B」。
机制/约束:APO 论文(Anchored Preference Optimization and Contrastive Revisions,作者含 Amanpreet Singh)提出更可控的对齐目标;锚定与 KL / 参考模型 相关——嘉宾口语 「anchor gap 归一化间距」非论文标准术语,且 CLAIR 实验仍用 preference pairs。与 DSPy/MIPRO 等「用 LLM 改 prompt」相比,嘉宾认为多用户分布难以用自然语言概括,迟早要动权重,且单独 fine-tune 某模块不够,要调「整机旋钮」(演讲者观点)。
怎么做:将 LMUnit 二元/阈值信号或用户 thumbs 接入 KTO/APO 目标;对非参数工具(Python 沙箱、只读 API)学习「在约束内更少犯错」而非幻想反传进 Postgres。
常见误区:在 90/10 负样本下仍按平衡集采样;把 APO 当成纯 unpaired thumbs 算法——论文实验与 CLAIR_and_APO 代码 仍以 pairs 为主;只优化 generator 而让 retriever 永远 frozen。
可信、冲突与管线离散参数#
为什么:企业场景要 audit trail / citations(嘉宾类比 Perplexity 式 enterprise 需求,演讲者观点)、uncertainty 触发人工升级,以及文档间冲突(recency、内网 vs 外搜、分析师偏好规则)。
机制/约束:reranker 被描述为降低生成器难度的约束——与深度学习史上「先加结构再放松」同构(演讲者观点)。向量库侧可加 recency 表达式,与端到端学习并存,但受组件 API 限制。Chunk size、top-k、抽取策略可 A/B,但组合爆炸时需 分布匹配 + 限缩 action space(演讲者观点)。
怎么做:声明冲突解析策略(显式规则 + 可选学习);保留适度 parametric 推理能力,避免模型只会拼接 snippets;对 Llama 3.1 等基座采用 prompt + fine-tune + 整机优化 混合(演讲者观点;平台 benchmark 将其作基线见 2025 benchmarks 博客)。
常见误区:认为加一个 GPT-4 评委就完成治理;在 Notion 只搜 title 的 API 上期待全文级召回;把 black-box DB 完全绕开优化——省事但能力封顶。

两种工程信条(不必强行统一)#
| 信条 | 常见实践 | 嘉宾/官方强化 | 证据强度 |
|---|---|---|---|
| System over models | 单 foundation model 包办 | 检索、生成、验证、冲突解析分工 | 演讲者观点 + 产品叙事 |
| Enterprise specialization | 通用模型 + RAG | 轨迹 + 偏好 + 可验证信号更新权重 | KTO/APO/RAG2 部分有论文;规模数字 不可核实 |
| 约束先于端到端 | 端到端黑盒一切 | reranker、专用模块降优化难度 | 演讲者观点 |
| 评测驱动训练 | 离线 benchmark 至上 | LMUnit 信号作 reward | LMUnit 文档 部分支持 |
Test-time compute 今日主流实现不改权重;若未来推理时亦更新参数,问题又回到 training 栈(演讲者观点)。与向量数据库(如 Weaviate)的分工是:存储与检索基础设施 vs 端到端 RAG/Agent 优化层——互补,非替代。
若你要落地#
- 先画轨迹,再选优化杠杆:记录
query → retrieval/tool → generation → feedback;区分「多轮 test-time」与「把失败蒸馏进权重」两条路径,别只用 latency 砍轮次。 - 评测产品化早于堆评委:用 LMUnit 式自然语言 rubric + 阈值校准,承认 1–5 分 + 专用 70B 评测器 的成本模型,勿假设「小模型免费」。
- 偏好信号按生产分布设计:优先 KTO 类 unpaired thumbs;若用 APO,阅读论文中的 paired / KL anchor 设定,勿照搬口语「anchor gap」。
- 检索范式与工具 API 对齐:核对是否为 retrieve-then-read;财年/术语类问题预留 语料反馈后再查询;BIRD 类 SQL 目标写明 local vs API、EX vs pass@k、dev 榜单时间。
- 保留 parametric 推理 + 显式冲突规则:reranker/recency/人工升级是约束,不是落后设计;在工具能力上限内做端到端「更好用法」学习。
参考与延伸阅读#
- Contextual AI 官网
- Introducing RAG 2.0 — 端到端联合优化
- Retrieval-Augmented Generation for Knowledge-Intensive NLP (Lewis et al., 2020)
- RETRO: Improving language models by retrieving trillions of tokens
- Fusion-in-Decoder (Izacard & Grave, 2020)
- Baleen: Robust Multi-Hop Reasoning at Scale
- LMUnit 研究页与论文 arXiv:2412.13091
- LMUnit 开源仓库 GitHub
- KTO: Model Alignment as Prospect Theoretic Optimization
- APO: Anchored Preference Optimization arXiv:2408.06266
- BIRD Text-to-SQL Benchmark
- Contextual-SQL 与 BIRD 成绩说明(2025 博客)
- Platform GA 新闻稿(2025-01-15)
- DeepSeek-R1 技术报告
- Weaviate 开发者文档


