
Data Agent:当「会写代码的模型」撞上真实数据栈#
企业里最常见的数据问题,早已不是「模型会不会 SQL」。同一笔业务可能散落在 Snowflake 仓库、MySQL 应用库、Mongo 文档、Salesforce(SOQL)和 Slack 线程里;join key 可能是 bid_* 与 bref_* 的前缀游戏,而不是干净的 id = id。在这种栈上,Retrieval-Augmented Generation (RAG) 的「单一大索引」愿景与 Kaggle 式「千张表各自为政」之间,夹着一类更难评测的系统:data agent——跨源取数、清洗、推理并给出可核对答案的自主(或半自主)执行体。
下文把 UC Berkeley 方向研究者 Shreya Shankar 在公开 benchmark、声明式文档系统与「部落知识」记忆上的工作,与 Weaviate 侧对 query/transformation agent 的产品映射并置;不强行收束为单一结论。可核对处对齐论文与仓库;口述数字与机制转述处会标明边界。
「Data agent」到底指什么#
为什么争论定义本身很重要#
评测、产品路线图和招聘 JD 里的「data agent」若不对齐,团队会在 text-to-SQL leaderboard 高分与「跨库答不出题」之间产生虚假安全感。定义分裂会直接决定:你是优化单一 vector DB 上的 NL 检索,还是建设跨 DBMS 的工具链与失败模式库。
机制与约束#
常见有三层张力(演讲者观点与产品表述并存):
| 视角 | 核心主张 | 可核对边界 |
|---|---|---|
| 宽定义 | 跨库、跨文件、跨协作工具取齐信息,再计算与推理 | 难点在 data thinking 与工具熟练度,而非单点 NL→SQL(演讲者观点) |
| 产品映射 | 读路径(NL→检索/聚合)+ 写路径(分类、填属性)拼成完整 agent | Weaviate Query Agent / Transformation Agent 为演讲者观点下的读/写两半 |
| 评测定义 | 多 DBMS、畸形 join、SQL+Python 工具轨迹 | 以 Data Agent Benchmark (DAB) 的 workload 属性为准 |
怎么做(最小落地视角)#
先把「一题」拆成可观测子能力,再选执行形态,而不是先选「是否叫 agent」:
用户问题 → schema/样本探测 → 清洗与 join 计划 → 执行(SQL / Python / 声明式算子)→ 可自动对标的答案
常见误区#
- 把 pass@1 在单库 text-to-SQL 上的分数等同于 data agent 能力。
- 默认「上 RAG」就能替代跨库 join 与清洗;结构化可表达时,嘉宾倾向 能 SQL 就 SQL(演讲者观点),embedding 留给模糊语义。
公开 benchmark 说了什么、没说什么#
为什么需要新的 DAB#
Can AI Agents Answer Your Data Questions? 指出:既有工作多覆盖 text-to-SQL 片段、小表 in-context 或单管道能力,缺少对跨多 DBMS 完整流水线的系统评估。嘉宾称见过至少 25 个相关 benchmark(演讲者观点,未见可核对清单);「25+」不宜写成论文定理。
DAB 规模(论文):54 道查询、12 个数据集、9 个领域、4 种 DBMS;与 Hasura PromptQL 的行业访谈共同塑造 workload(含 ill-formatted key joins、多库集成)。
机制与约束#
指标(论文,2026-05 核实):
- 最佳前沿模型 Gemini-3-Pro:pass@1 ≈ 38%(播客口述约 37%,属同一量级)。
- 每题 50 次独立 trial;同一设置下 pass@50 最高约 69%——说明「多试几次」与「一次配对」差距极大。
- pass@k 沿用代码生成文献惯例:k 次独立运行中任一次正确即计该题成功。
刻意未覆盖(设计与演讲者观点一致):semantic-operator 系统(如 LOTUS、Palimpzest)的对照轨;逼真且可自动评的 写操作;可靠的多轮「模拟业务用户」。每题仍多为单一标答,与真实分析的多解性存在张力。
怎么做#
复现或对标 leaderboard 时,必须对齐:模型名、trials/query、是否 hints。DataAgentBench 仓库 与 leaderboard 行字段缺一不可。
常见误区#
- 把第三方提交的 5 trials/query、60%+ 与论文主实验的 50 trials、38% 直接比较。
- 认为 benchmark 高分等于生产可部署(写路径、权限、成本未测)。
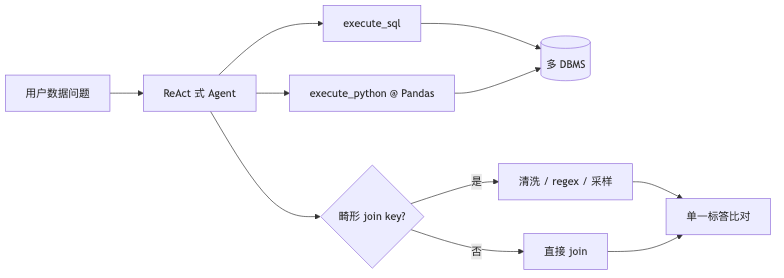
多库集成:schema 不够,必须「看数据」#
为什么#
DAB 将 multi-database integration 与 ill-formatted key joins 列为核心属性:例如 PostgreSQL 与 SQLite 并存时,id 与 bid_* / bref_* 前缀不一致,迫使 agent 解析而非假设等值 join。同一公司也可能同时跑多个 SQL 引擎(仓库 + 业务 MySQL),算子相似仍无法一条 SQL 联邦(演讲者观点)。
机制与约束#
metadata API 能列出 schema,但对 ill-formed join key(文本、字符串数组等)往往不够;轨迹级失败类型含 Incorrect Regular Expression (FM4) 等(论文附录)。嘉宾强调:需看数据再定清洗(如多正则 union 后再 join),不能只靠「脑中假设」(演讲者观点,与论文方向一致)。
怎么做#
-- 探测性采样(论文轨迹中常见;非生产最佳实践)
SELECT * FROM some_table LIMIT 5;
-- 随后:根据样本设计清洗,再 join(逻辑示意)
生产侧更宜:受控采样 API、列级 profiling、把清洗固化为可版本化的 transform,而非留给 agent 临场 regex。
常见误区#
- 以为 Spider 2.0(企业级 text-to-SQL workflow)与 DAB 测的是同一类「跨库 agent」能力——二者相关但 benchmark 不同。
- 仅增加 prompt 里的 schema 文本,而不给可重复的样本访问策略。
典型失败模式:会采样,但不会「像 DBA 一样想」#
为什么#
工具面允许「SQL 落盘 → Python」时,agent 会走阻力最小的路;论文明确提供 execute_python(Pandas/Pyarrow),因此 SELECT * → 平面文件 → Pandas 是合法路径,也是扩展性陷阱。
机制与约束#
论文可核对模式:SELECT * LIMIT 5 后即停;catalog 探测;普遍用 regex 做文本抽取;FM1–FM4 类错误(浅采样、错误计划、错列、错 regex)。
演讲者观点(论文未写死阈值):约 10 万行即抱怨「记录太多」;而 DBA 心理尺度常在千万、亿级——尺度错位会导致拒全扫与过度依赖 Pandas。
怎么做#
在 agent 外层加策略护栏(非替代模型):
# 示意:限制无脑 LIMIT 5 就结束
if step == "sample" and rows < min_profile_rows:
require("distribution_stats or explicit justification")
对语义过滤类题(例:sports article 描述最长),DAB 题面需要语义理解;评估对象仍是 ReAct+SQL/Python,不是 LOTUS 式 sem_filter(论文设计选择)。
常见误区#
- 把 regex 失败简单归因于「模型不够大」,而不改 工具反馈与中间结果校验。
- 禁止 Python 工具——论文表明 Python 有时是必要路径;关键是避免 本可单条 SQL 却全盘导出。

执行路径分裂:SQL、Python、语义算子与声明式重写#
为什么#
多库、多方言、非 SQL 源并存时,不存在单一「银弹」执行引擎。嘉宾与主持的分歧,本质是 自主探索 vs 声明式优化器 谁更适合数据工作负载。
机制与约束#
| 路径 | 优势 | 局限(节目与文献) |
|---|---|---|
| 多方言 SQL + skills | 语义清晰、可审计 | 无法单 SQL 联邦;Mongo 等方言 agent 常弱(演讲者观点) |
| Python/Pandas | agent 当前最会 | 高延迟、难扩展;嘉宾称整体仍「pretty bad」(演讲者观点) |
| Semantic operators | NL 版 map/filter/join;可 per-row LLM 或合成 regex | DAB 未测 该类系统;agent 仍偏爱 regex(论文 takeaway 支持倾向) |
| 声明式 + rewrite 搜索 | DocETL 的 rewrite directives + 计划评估 | 偏文档/非结构化管线;与端到端 Codex 式探索形成张力 |
DocETL(论文核实):用户写声明式 pipeline;系统用 agent 提出 rewrite strategies(chunking、多级聚合、gleaning 等),在 rewrite × prompt × model 空间搜索;四任务上较强 baseline 高约 25%–80%(任务依赖)。
Palimpzest(播客口误 Palimpsest):声明式 AI 负载优化,强调 cost optimization;嘉宾以 Cascades 式类比为方向性说法,不宜写成论文正式术语。
LOTUS:semantic operators + model cascade(小模型+置信度阈值再升 oracle)降成本。
怎么做#
CUAD 例(510 份合同、41 类条款;嘉宾口述 512 为四舍五入):朴素计划「每文档抽 41 属性」→ 可 rewrite 为 8×5 分组 等;由 DocETL agent 在样本上搜索 chunking/分组(使用示例,非 CUAD 论文强制设定)。
# 概念示意:声明式算子链(非真实 DocETL 语法)
pipeline:
- map: "extract clause types from chunk"
- reduce: "merge by contract_id"
常见误区#
- 用 DSPy 优化出的超长 BM25 字符串 代表「可维护 skill」(嘉宾批评性观点,未绑定期刊版本)。
- 认为 persistence 差异等于 read/write 语义差异——嘉宾澄清:DocETL 与 LOTUS/Palimpzest 均可持久化;差在 优化/rewrite 哲学(演讲者观点)。
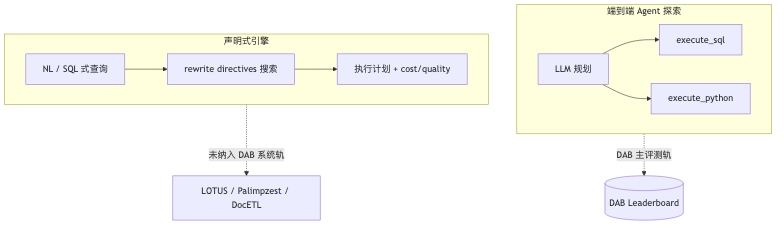
Agent-first 数据库:分支、推测与 pass@k#
为什么#
当 LLM agent 成为主要查询者,传统「一次提交、一次结果」的事务叙事不够:agent 需要并行试错、保留一次成功、丢弃失败探索(演讲者观点,与 Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First 主题一致——正式标题非字面 overlords)。
机制与约束#
CIDR 方向论文提出 agentic speculation、branched updates:在 Neon 等 copy-on-write branching 上 fork 状态、推测性写入、失败分支回滚。pass@50 与 Neon 的逐字绑定未见于已抓取论文 HTML;pass@k 来自 DAB 协议,与 CIDR 文为不同来源。嘉宾对 Neon 实现细节自认不熟(演讲者观点)。
怎么做#
将「评测时的 50 trials」与「生产分支策略」分开设计:评测要独立随机种子;生产用短生命周期 branch + 合并策略,避免 agent 写脏主库。
常见误区#
- 把 branching 当成唯一解法,而忽略 权限模型与成本(每次 fork 的存储与计算)。
- 假设所有探索都可自动 merge——业务约束常要求人工确认。
Tribal knowledge:不是「数据维基」,而是纠偏记忆#
为什么#
跨库失败后,团队常想建「知识库」让 agent 记住 Nike 拼写、列别名习惯;若离线洗入模型无关真理,可能错配执行器行为(regex vs LIKE vs 列名 brand)。
机制与约束#
Arming Data Agents with Tribal Knowledge(Tk-Boost;嘉宾转述同事工作,无 Shankar 署名)定义:tribal knowledge 是纠正 agent misconception 的可复用 NL 陈述,而非复述库表事实。存储为 TK Store,每条带 applicability conditions(SQL 结构特征:用到的列、clause 等);流程为 先 first-attempt SQL → 按适用性检索 → 子查询级修正。在 BIRD、Spider 2.0 上相对各 baseline 有约 +13.7% / +16.9% 量级提升(相对增幅,非绝对准确率)。
嘉宾口述的「按 SQL keyword 列 + table/column 列」与论文 schema 有出入;写作应以论文为准。核心精神一致:记忆常绑定特定模型的失败模式(演讲者转述),离线泛化可能是 premature optimization。
怎么做#
1. 记录失败轨迹中的「误解」而非仅记录事实
2. 为每条知识写 applicability(哪些查询形状会触发)
3. 评测时固定 agent 版本,再测记忆迁移
常见误区#
- 把 tribal knowledge 当成 RAG 文档库全文灌入。
- 不区分 database facts vs correction statements(论文明确区分)。
检索与 RAG:一个索引 vs 千张表#
为什么#
主持提出两极:互联网级单索引 vs 数据集搜索式的海量表;嘉宾更愿意说 retrieval 而非 RAG(对 generation 部分存疑,演讲者观点)。数据 agent 场景下,agentic grep、工具调用链难以嵌入经典 IR/DB 框架——需要混合检索策略。
机制与约束#
结构化可表达时优先 SQL(演讲者观点);embedding 用于模糊匹配。Weaviate 产品侧的 hybrid search 与 agent 编排是另一套工程路径,不与 DAB 分数自动等价。
怎么做#
为每类源选默认检索器:表/列 → SQL + 统计;文本 → 向量 + 关键词;日志 → 时间范围 + 正则(并审计)。
常见误区#
- 用单一 vector collection 假装覆盖了 warehouse 里的规范化表。
- 忽略 检索结果是否可执行(能否生成可运行 SQL/Python)。
程序、数据与「技能」边界变糊#
Claude Code skill 中,程序描述、个人习惯与上下文记忆难以用经典 CS 的 compute/data 二分(演讲者观点,未形式化验证)。Spawn sub-agents 类似动态创造 compute,资源边界变模糊——这与传统 DB 可预期资源模型冲突,也解释了为何嘉宾同时押注 声明式查询优化 与 公开 benchmark 两条线。
若你要落地#
- 用 DAB 或自建多库小题集做回归,报告 pass@1、pass@k、trials、hints;别只用单库 Spider 类分数说服自己。
- 把「采样 → 清洗 → join」做成可观测步骤,限制
LIMIT 5即停与无脑 regex;对语义过滤题单独设 rubric 或引入 LOTUS 等声明式算子作对照(非 DAB 官方轨)。 - 工具策略:允许 Python,但对
SELECT *全表导出设成本/行数护栏;结构化题默认 SQL-first。 - 记忆:按 Tk-Boost 思路存 misconception + applicability,并固定评测模型版本;避免一次性「洗知识库」。
- 基础设施:若 agent 高频试错,评估 Neon branching 或同类 COW 分支与 agent-first 架构是否匹配你的写入语义与合规要求。
参考与延伸阅读#
- Can AI Agents Answer Your Data Questions? (DAB 论文)
- DataAgentBench 代码与 Leaderboard
- Retrieval-Augmented Generation (Lewis et al., 2020)
- Spider 2.0:企业级 text-to-SQL workflow
- CUAD 合同理解数据集(510 合同 / 41 条款)
- Atticus Project CUAD 官方页
- DocETL:声明式文档处理与 agentic rewrite
- DocETL 项目站与文档
- LOTUS:Semantic Operators 与 model cascade
- Palimpzest:声明式 AI 负载优化
- SemBench:语义引擎横向评测(含 LOTUS、Palimpzest)
- Supporting Our AI Overlords(agent-first 数据系统)
- Arming Data Agents with Tribal Knowledge (Tk-Boost)
- Weaviate Query Agent 文档
- Weaviate Transformation Agent 文档
- Neon 数据库 branching 文档


