
AI 驱动搜索:当 RAG、Agent 与经典 IR 重新接线#
把 RAG 接到生产系统的人,迟早会撞上同一组张力:检索质量与 Agent 循环谁该背锅;长上下文与 可检索历史谁更便宜;MTEB 榜单模型与 本域 corpus 谁才算「上线答案」。Doug Turnbull(Relevant Search 合著者)与 Trey Grainger(Searchkernel;与 Doug 合授 AI-Powered Search)在一场约 54 分钟的对话里,从不同工程立场拆解这些张力——没有统一结论,只有可落地的分界与待验证边界。
本场画面以三人连麦为主,未见可 OCR 的架构幻灯片;下文技术论断绑定公开文献/产品文档,嘉宾原话标为演讲者观点。
问题空间:搜索仍在,只是接口变了#
电商、论坛类场景里,用户仍习惯「搜索框 + 快速点击」——precision 与低延迟优先。法律发现、医疗文献、招聘筛选等则要求 高 recall、可审计的多轮穷尽(演讲者观点)。同一套向量栈无法同时优化这两种目标函数;NDCG@k、Recall@k、MRR 等指标也随任务类型在 MTEB 中并非单一总分可比。
Agent 把「查索引」变成工具调用,把「拼上下文」变成 prompt 工程——Trey 将之与经典 relevance engineering 并置:内容、领域、用户三桶上下文,与 Agent 侧 prompt 管理同构(演讲者观点)。差别在于:搜索系统几十年沉淀的 索引接地(index grounding) 与 行为监督(revealed preferences) 是否被搬进 Agent 环。
Agent 能否替代强检索器?#
常见做法#
行业叙事常暗示:Agent 可多轮发 query、自纠错,弱 retriever 也能「够用」;编码 Agent 里 grep / keyword 的成功案例又被拿来类比搜索。
嘉宾分歧#
| 立场 | 要点 |
|---|---|
| 迭代可补偿弱检索(主持方追问) | 大量 query、自调整;是否不必继续卷 embedding benchmark? |
| 仍须强检索与可解释匹配(Doug) | 对「good enough 就不训嵌入」:「you absolutely have to」 继续改进(演讲者观点);grep/BM25 有效 partly 因为 输入—输出可预测,便于 Agent 推理。 |
| BM25 + Agent 曾可行(Doug,~08:47) | 给 Agent 简单 BM25 工具,靠 query expansion、多策略查索引、聚合,可能逼近语义检索——无一手 benchmark 证明等价于 dense retrieval(核实边界)。 |
机制/约束:Agent 环解决的是 策略搜索(试哪条查询、何时停);Okapi BM25 与 dense retriever 解决的是 单次检索的匹配函数。二者正交。Doug 同时强调 harness:可 start/stop、重置 context、避免重复探索已搜区域,有时 dumber model + good harness 足够(演讲者观点)——这与「百万 token 单窗」路线不同。
最小示例(概念):
loop:
q = agent.expand(previous_hits, user_goal)
hits = bm25(index, q, k=50)
if agent.should_stop(hits): break
# 评测:Recall@100 on legal discovery,而非单次 MRR@10
常见误区:用 coding-agent 的 lexical 成功 直接推出 产品搜索可停训 embedder;在 recall 优先 场景下,弱检索 + 多轮 Agent 仍可能漏掉关键文档(待任务评测)。
Doug 还提到:纯 similarity ranking 不做 filtering——向量近邻能找「像 Purple 的床垫」,却分不清用户要的是 品牌 Purple 还是 紫色;这类歧义要靠索引挖掘、facet 或分类器补齐(演讲者观点),不能指望单次 cosine 排序自愈。

上下文:压缩还是可搜索的历史?#
为什么#
长对话 Agent 为省 token 常做 compaction——删掉早期 tool 输出与用户澄清,只留摘要。
机制/约束#
Trey 与 Doug(~11:46)主张:不应把 context 扔掉;应 log 到侧,需要时再 scan,按当前 prompt 生成更好上下文;当前 compaction 浪费数据,本质是 search problem(演讲者观点)。这与 RAG 的非参数记忆思想一致:外部可检索存储 + 按需拉取,而非在窗口内硬删。
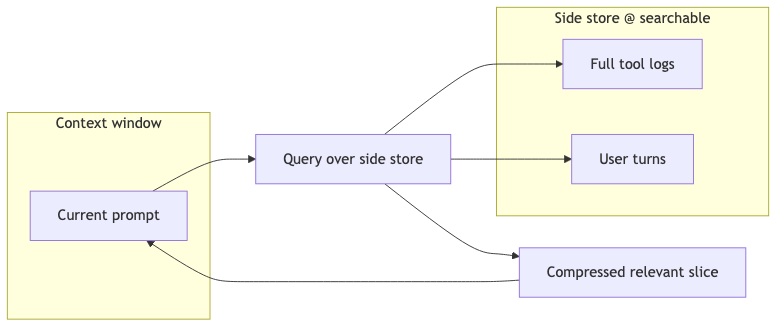
怎么做:为会话维护可全文检索的侧存储(同一 倒排索引 或向量索引均可);每步用 检索 + 摘要 填充窗口,而非单向丢弃。
常见误区:把 compaction 等同于「高效记忆」;丢失的 tool 轨迹往往是 免费监督信号(演讲者观点),后续无法做 LTR 或失败分析。
多阶段 RAG:先理解 query,再喂给生成#
为什么#
单阶段「embed query → top‑k → LLM」在实体稀疏、字段结构重的 catalog 上,常把 理解错误 与 检索错误 混在同一跳里,难以调试。
机制/约束#
Trey(~17:35)描述 multi-stage RAG:第一阶段 query interpretation——在索引里匹配 query 片段、实体、术语;第二阶段才把 已接地 的检索结果交给下游 RAG(演讲者观点)。这与 Lewis et al. 原文中「整段 conditioning vs per-token passages」的两种 formulation 不同——后者是论文内消融,前者是 索引挖掘式 工程模式(核实:RAG 定义有文献支持,阶段划分属访谈)。
怎么做#
stage1: spans, facets = interpret(query, index_stats)
stage2: hits = hybrid(spans, filters=facets)
stage3: answer = llm.generate(hits, query)
常见误区#
把 Weaviate Query Agent 的过滤能力当成「已解决 query understanding」——能力存在,但 业务域 taxonomy 与评测集 仍需自建;访谈中的 filter inspector 命名未在公开文档对齐。
Query 理解:LLM 分类 vs 索引接地#
常见做法#
用 LLM 直接做域分类(如 NAICS 产业码、商品 taxonomy),再写过滤条件或生成答案。
嘉宾主张#
Doug:LLM 可借助训练数据里的公开 taxonomy 快速分类,但易 hallucinate 错误码(演讲者观点)。Trey:Index-as-LM——从 query 抽片段 → 在 索引字段/术语/聚合 里核对 → 再 faceting、写检索 query;「almost like RAG for the LLM」 用于理解,而非仅生成最终段落(演讲者观点)。
机制/约束:NAICS 等码表有官方层级;LLM 输出必须在 corpus 统计 上可验证(某 facet 是否存在、共现是否支持)。Weaviate Query Agent 文档描述 semantic search with optional filters 与聚合;访谈中的 filter inspector node 命名 未在公开文档中出现(部分核实)。
最小示例:
spans = llm.extract_entities(query)
for s in spans:
assert index.term_stats(s) # 接地:术语必须出现在索引或可聚合字段
facets = index.top_facets(matched_field)
query = build_lexical_or_hybrid(spans, facets)
常见误区:跳过索引统计,直接让 LLM 写 filter JSON——在长尾实体、品牌/颜色歧义(如「Purple mattress」)上易错(演讲者举例)。
Hybrid 融合 vs Wormhole:两条正交路线#
Hybrid(经典工业路径)#
[Trey 归纳 ~31:42]:BM25 与 dense 各跑一路,再 merge/boost——Weaviate hybrid search 文档 已核实:“runs both search types in parallel and combines their scores”,支持 relativeScoreFusion / rankedFusion 与 alpha 权重。
为什么:lexical 擅 精确标识符(SKU、产品 ID);dense 擅 语义近邻;并行融合缓解单路盲区。
常见误区:把 fusion 当成 wormhole 的「更强版 merge」——二者目标不同(见下)。
Wormhole vectors(课程/访谈概念)#
Trey(~26:17–35:58):把 query 视为 文档集合的语义表示,在 sparse/lexical、dense、behavioral(如 矩阵分解推荐 隐因子)空间间 跳转,而非仅并排融合列表(演讲者观点)。
访谈机制示例:lexical 命中集 → aggregate(如平均) 文档向量 → 在 dense 空间找邻域;可反向 dense top‑k → 生成 lexical/SKG 查询。社区实现 wormhole-vectors README 写的是 significant_terms 聚合,未写「向量平均」——与字幕 “average” 表述 不一致(核实边界:平均向量算子标为访谈观点)。
向量 算术 直觉来自 Word2Vec 类比;Trey 的 Darth Vader + puppy → cosplay puppy 为口语例,强依赖嵌入模型与域(演讲者观点)。倒排索引可教学上视为极高维 稀疏 term 向量(IR 教科书 级表述,非严格 one-hot)。
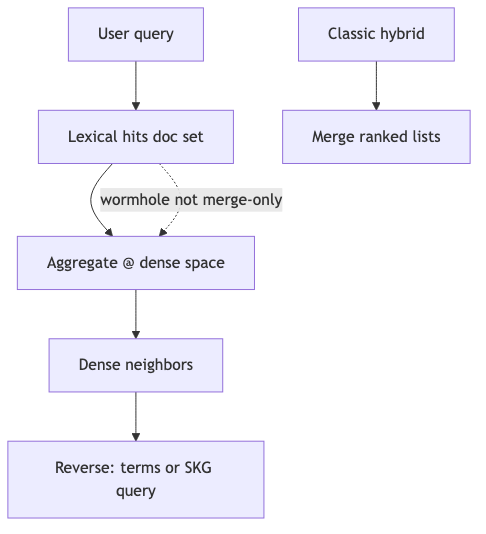
怎么做(伪代码,访谈版):
docs = bm25.search(q, k=100)
centroid = mean(embed(d) for d in docs)
neighbors = dense.knn(centroid, k=20)
常见误区:未建 behavioral/CF 空间却宣称三空间 wormhole;在未 A/B 的情况下用 MTEB 榜首 embedder 代替 域内微调。
榜单嵌入、域内因子与行为信号#
常见做法#
选 MTEB 榜首文本嵌入,接 Weaviate / Elasticsearch 即上线。
嘉宾主张#
Trey(~39:06):榜单模型是 起点;「secret unlock」 是把 query 接到 本 corpus、本 domain、本用户(演讲者观点)——与 MTEB 论文 “no particular text embedding method dominates across all tasks” 方向一致(文献支持)。Doug(~41:51):数十年 beat BM25 靠的是 domain ranking factors,非仅 hybrid;embedding 质量 必要但不充分(演讲者观点)。
行为 > 复杂重排(Trey,~44:17):head query 上对 用户已点击/购买 项做 pop-boost,常优于纠结 BM25 位次——与 Learning to Rank 从点击推断标签的工业实践 方向一致;「常优于」无本场定量 A/B(访谈观点)。
训练目标分裂(Doug,~25:15):为 ranking/embedding 优化 vs 为 点击/购买等 revealed preferences 优化,是不同 objective 的灰区——与 LLM 时代前的搜索/推荐一脉(演讲者观点)。
常见误区:用 Claude 等生成 ranking function 却不隔离评测集——Doug 警示可能 记忆训练集(演讲者观点,与一般 ML 泄漏常识一致)。
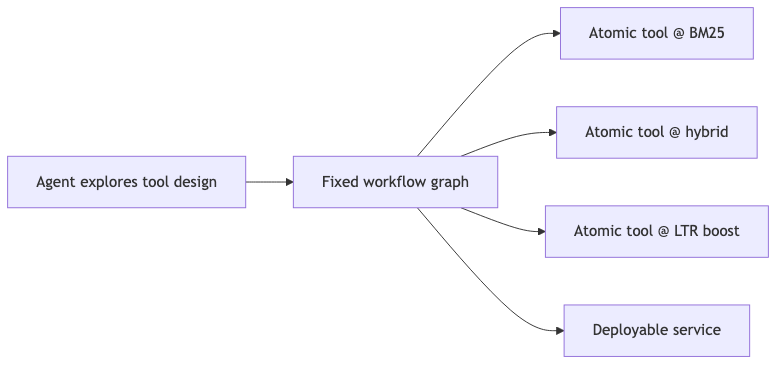
交付形态:Workflow 优先于工具堆#
常见做法#
给 Agent 一堆 tools,指望模型自行组合成产品。
嘉宾主张#
Trey(~53:46):用 Agent 设计 workflow 与 tools,再 wire 成可重复、可上线的 workflow;atomic agents 在范围极窄时可由 小模型确定性 输出(演讲者观点)。这与「开放式 tool 环」相对——生产搜索更偏向 编排 + 原语质量。
Doug 侧补充:搜索框在 高 recall 流程 中仍会存在,与大众 冲动点击 行为并存(演讲者观点)。片尾预告 ColBERT 等 late interaction 作为下阶段课程主题——已核实论文存在,与本场 wormhole/hybrid 讨论互补。
Trey 在开场还提到 Google 「Generative UIs」 方向:LLM 产出 HTML/JS/CSS 生成交互界面(演讲者观点)。本环境 未 锁定与字幕完全同名的一手论文或博客 URL(无法核实),不宜把该点写进架构决策的硬依赖——仅作「生成式 UI + 搜索」的联想边界。
若你要落地#
- 先定目标函数:precision@10 的导购搜索 vs recall@1000 的合规/法律发现——再决定是否上 Agent 外环,以及评测用 MRR 还是 Recall。
- 默认 hybrid,再评估 wormhole:用 官方 hybrid API 做 BM25+dense 并行基线;若跨空间跳转,对照 wormhole-vectors 的 significant_terms 实现与访谈中的向量平均是否一致,勿混为一谈。
- Query 理解必须 index-grounded:LLM 抽实体后,用 facet/term 统计过滤幻觉;taxonomy(NAICS)对照官方码表。
- 会话记忆用检索侧存储,避免不可逆 compaction;把历史 tool 输出当可搜 corpora。
- 行为信号接入 LTR 或浅层 boost,与嵌入训练分开看 objective;任何 LLM 生成的 ranker 特征要做 hold-out 泄漏检查。
参考与延伸阅读#
- Retrieval-Augmented Generation(Lewis et al., 2020) — RAG 参数/非参数记忆定义
- Massive Text Embedding Benchmark(Muennighoff et al., 2022) — 无单一嵌入统治全任务
- MTEB Leaderboard — 公开榜单与任务分解
- ColBERT: Efficient and Effective Retrieval via Late Interaction(Khattab & Zaharia, 2020) — 片尾预告主题
- Efficient Estimation of Word Representations(Mikolov et al., 2013) — 向量类比与组合性讨论起点
- Introduction to Information Retrieval(Manning, Raghavan & Schütze) — 倒排、BM25、评测基础
- Okapi BM25(Wikipedia + Robertson 综述链) — lexical 基线
- From RankNet to LambdaMART(Microsoft Research) — LTR 与点击监督
- Matrix Factorization Techniques for Recommender Systems(Koren et al. PDF) — behavioral 隐因子
- Weaviate Hybrid Search 概念文档 — 并行 BM25+vector 与 fusion
- Weaviate Query Agent 介绍 — 语义检索 + 可选过滤/聚合
- wormhole-vectors(社区 OpenSearch 概念实现) — dense↔sparse 桥接(机制与访谈需对照)
- AI-Powered Search(Grainger & Turnbull, Manning) — 课程配套教材
- Relevant Search(Turnbull 等, Manning) — 相关性工程背景
- U.S. Census Bureau — NAICS — 产业分类官方入口(本环境曾抓取失败,链接仍为标准入口)
证据说明:Weaviate hybrid、ColBERT、RAG、MTEB、BM25/LTR/Word2Vec 等见上链文档;wormhole 平均向量、BM25+agent≈语义、pop-boost 优于重排、workflow-first、compaction=搜索问题等标为演讲者观点或部分核实;Google「Generative UIs」论文题名本场未锁定一手出处(无法核实)。


