
当标量 reward 不够用时:GEPA 与 compound AI 的反思式文本进化#
Compound AI 系统把检索、工具调用、多步推理和验证器串成一条 language program(DSPy 术语),却在生产里反复撞上同一堵墙:你真正想调的是 prompt / instruction / 可编辑文本组件,而主流 RL 管线仍把学习信号压成轨迹末端的一个 标量。论文 GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning(arXiv:2507.19457;全称 Genetic-Pareto)提出另一条路——用 自然语言反馈 驱动 反思式变异 与 按实例的 Pareto 保留,在 LangProBe 六任务上相对 GRPO 报告平均约 +6%、最高约 +20%,且 rollout 至多 35× 更少(以论文摘要为准)。实现见 gepa-ai/gepa,并已集成进 DSPy 的 dspy.GEPA。
下文是面向有经验工程师的技术合成:把常见做法、论文/代码可核对机制、以及播客中 Lakshya A. Agrawal 的演讲者观点分开写;本集画面均为远程对谈,无论文架构幻灯片(配图仅作语境,不当作 Fig.3 替代品)。

问题空间:compound AI 优化在优化什么#
为什么:RAG、agent、PoT、ReAct 等形态在 LangProBe 里被统一成「带控制流的 LLM 程序」。架构选型与 optimizer(Bootstrap、OPRO、MIPRO、GRPO、GEPA)共同决定 cost–performance 前沿;换更大模型往往不如改 instruction 或可进化文本 划算。
机制/约束:论文将待进化对象记为程序参数 (\Pi_\Phi),冻结 权重 (\Theta_\Phi)。优化预算通常是 metric / rollout 调用次数(max_metric_calls),而非 GPU 训练步。适用前提是:你能对每个实例给出 可自动化的 (\mu)(标量)和 ideally (\mu_f)(文本反馈)——编译器报错、rubric 分项、profiler 输出、LLM-as-judge 评语等。
怎么做(最小接口):在 DSPy 侧,metric 可返回 Prediction(score=..., feedback=...);GEPA 的 EvaluationResult 同样承载 score 与 feedback。
# 概念示意:反馈不必塌缩成单一 float
def metric(example, pred, trace=None):
ok = pred.answer == example.answer
feedback = "" if ok else f"expected {example.answer}, got {pred.answer}"
return dspy.Prediction(score=float(ok), feedback=feedback)
常见误区:把 GEPA 当成「免标注的通用 RL 替代品」。论文对比的是 同一 language program 上的 prompt 进化;无可靠 verifier 的开放域任务,PUPA 以外 judge 优化仍属未系统验证边界(演讲者观点)。
标量轨迹 vs 文本反馈:学习信号密度#
为什么:GRPO 等 Group Relative Policy Optimization 在长轨迹末尾汇总 reward;慢 rollout(编译 + 上板执行)下,大量对比轨迹成本极高。嘉宾动机(与论文摘要一致):rubric 子项、符号名建议、长度约束 等 trace 信息密度高于单一标量。
机制/约束:论文引入 feedback function (\mu_f),与标量 (\mu) 并用。六任务之一的 PUPA 在 artifact 中实现为 PAPILLON(数据 Columbia-NLP/PUPA),由 LLM judge 产出质量分与自然语言 feedback。
怎么做:先定义「什么算失败、失败时给模型看什么」——再交给 reflective mutation 的 LLM 读 trace 改 instruction。
常见误区:认为「有 feedback 就不需要 score」。代码路径仍要 可比较的标量 做 Pareto 记分与接受/拒绝;文本是 提案方向,不是唯一度量。
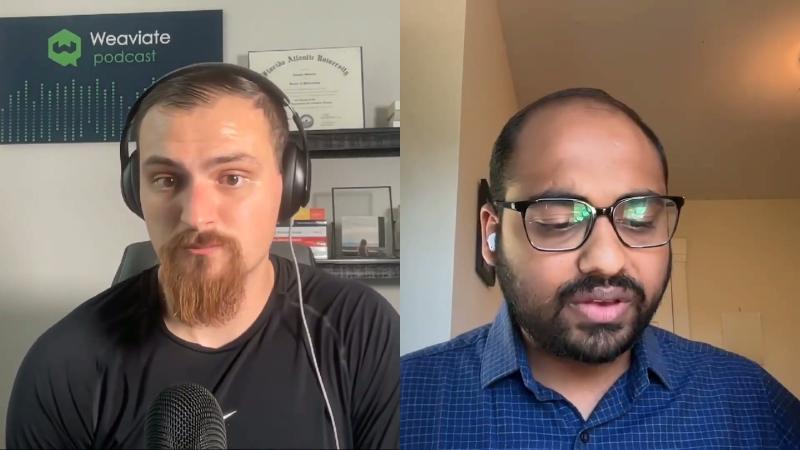
GEPA 主循环:候选池、minibatch 试探、全量记分#
为什么:全局贪心地只 mutate「当前总分最高」的 prompt,容易 局部最优;需要维护多样候选并在验证集上 按实例 跟踪谁最好。
机制/约束(论文 Fig.3–4、engine.py):
- 维护 candidate pool 与 Scores Matrix(每个 candidate × 每个 validation instance)。
- 每轮 Pareto 采样 → reflective mutation 或 merge 提出新候选。
- 先在 minibatch 上评估;有提升再 full eval 入库。

Reflective mutation(ReflectiveMutationProposer):在选中父代上跑带 trace 的执行,把 input/output 与用户定义的 metric 文本交给 反思 LLM,产出新 instruction;System-aware merge 则在进化树不同 lineage 之间合并文本洞察,再全量评估是否入库。
怎么做:gepa.optimize() 默认 reflection_minibatch_size=3 表示 3 个不同实例各 1 次带 trace 执行,而非同一实例重复 3–4 次采样(播客「3–4 次 rollout」与默认参数 弱一致,宜标为演讲者观点)。use_merge=True 时启用 merge 提案;长跑后 lineage 信息经 DspyGEPAResult.parents 等结构保留。
常见误区:把「候选池」理解成 k-best 单标量排序;核心是 per-instance 子分数(prog_candidate_val_subscores)。另一误区是忽略 minibatch 筛选:未在子集上改进的提案不会进入全量记分,这是控制 max_metric_calls 的关键阀门。

Genetic-Pareto:按实例保留,而非只追 aggregate 冠军#
为什么:可能存在「只在 Task 1 极好」的 instruction 片段;若每轮只改 aggregate 最高分,这些 非冠军 insight 会丢失。
机制/约束:论文 §3.1 的 Pareto-based candidate sampling;代码默认 frontier_type="instance"(ParetoCandidateSelector)。从「在每个 instance 上表现最好的候选集合」中 随机 选父代做 mutation;长跑后 system-aware merge(MergeProposer)尝试合并不同 lineage 的文本洞察。
嘉宾将此举类比 MAP-Elites 的 quality-diversity 思想——GEPA 论文未引用 MAP-Elites,机制上接近「按实例精英集」,不能写成「实现了 MAP-Elites」。
常见误区:test-time 模式下「每实例存 best prompt」与部署「单一 universal prompt」矛盾——论文 §5.1 的 inference-time 用法 允许 为一批 hard task 过拟合该批并共享 insight;是否上线单一 prompt 是产品决策,不是算法必输出。

相对 MIPROv2 与 GRPO:DSPy 谱系中的位置#
为什么:团队已在 DSPy 生态里做过 Bootstrap FewShot → OPRO(prompt + score)→ MIPROv2(instruction + examples,Optuna 搜索)→ GEPA。GEPA 论文报告相对 MIPROv2 平均 10%+(摘要),AIME-2025 例 +12%;相对 GRPO(实验配置见 gepa-artifact)为六任务平均 +6%、最高约 +20%、rollout 至多 35× 更少。
机制/约束:GEPA 用 遗传式提出 + Pareto 采样 替代 MIPRO 侧的 Bayesian/Optuna 程序搜索,并强调 单轨迹上的迭代反思(reflective mutation)。对比 GRPO 时,artifact 中 GRPO 常配 num_rollouts_per_grpo_step=12 等——对比的是 teleprompter 级 prompt 优化,非预训练 RL。
口述冲突(须标注):嘉宾曾称相对 GRPO 最高约 +25%;摘要写的是 up to 20%,正文另有任务级 19% 等表述。35× 与摘要一致;25% 无摘要支持。
常见误区:把标题「Outperform Reinforcement Learning」读成「淘汰所有 RL」。论文边界是 有丰富 (\mu_f) 的 compound LLM 系统;嘉宾亦认为未来 RL 会吸收 natural language reflection(演讲者观点,非 MMGRPO 已证结论)。


LangProBe 实验与 §5.1 的 kernel / 推理时搜索#
为什么:需要同时比较 架构(CoT、RAG、ReAct…)与 optimizer 的 Pareto;嘉宾称更好架构常 同时 提性能降成本,optimizer 再推前沿(演讲者观点 + LangProBe 设计目标)。
机制/约束(已验证):GEPA 主表六任务:HotpotQA、AIME、LiveBench-Math、IFBench、PUPA、HoVer(与 artifact get_benchmarks() 一致)。AppWorld 在 LangProBe 的 agent benchmark 集中,未列入 GEPA 论文六任务主表。播客提到的 Baleen 在 LangProBe 目录与 GEPA PDF 中 均未检出——疑为口述混淆,正文不依赖此名。
§5.1(初步实验,不与主表混谈):
- AMD XDNA2 / NPUEval 与 KernelBench + NVIDIA V100 CUDA;
- 论文表述:CUDA kernel 在 35 个代表任务中 >20% 快于 PyTorch-eager(非播客笼统「击败人工 PyTorch baseline」;须对照表格)。
Inference-time:将待解任务集同时作 (D_{\text{train}}) 与 (D_{\text{pareto}}),允许对该批任务「过拟合」并在相似子任务间迁移 insight(论文 §5.1;与嘉宾 test-time 叙述一致)。嘉宾举例:一批 PyTorch→CUDA 算子可共享同一进化中的 prompt 教训;也可 仅为单实例 优化后丢弃更新——与「训练一个从零泛化的 universal prompt」是不同产品模式(演讲者观点)。
反直觉但论文支持的一点:优化改的是 (\Pi_\Phi)(instruction 等文本),但 test-time 下每轮实际变化的是 在该 prompt 下生成的 code/输出;compiler/runtime 报错写回 prompt,更像 自举数据 而非一步梯度(§5.1 与演讲者「改 prompt = 改解」表述一致)。
样本效率主张的边界:摘要写 “even just a few rollouts” 可带来大幅提升;嘉宾称 as few as one 失败 rollout + 反馈即可——后者宜标演讲者观点。README 给出昂贵场景 100–500 次 metric 调用 vs GRPO 5,000–25,000+ 的量级对比,与 35× 同向,但是营销区间,落地应自建计数器。
常见误区:用 CITATION.cff 旧文案「四任务 / +10%」——与 v2 摘要 六任务 / +6% 冲突,以 arXiv 摘要与 PDF 为准。勿把 KernelBench 段落数字并入六任务主表做「全面 SOTA」表述。


超越 prompt 字符串:optimize_anything 与多目标 Pareto#
为什么:HNSW 循环、CUDA 片段、任何 可文本化 的系统组件都可能比权重微调更快迭代(README / optimize_anything 文档)。嘉宾称 GEPA 是 text evolution engine(演讲者观点);HNSW 具体实验未在 GEPA 论文 PDF 中检出。
机制/约束:objective_scores + frontier_type 取 "objective" / "hybrid" / "cartesian" 时做 多目标 Pareto tracking;reflection 可同时看到 recall↑ 与 runtime↑ 等分项,而非只看聚合标量。
常见误区:以为必须拆独立仓库「GEPA-as-a-text-evolution-engine」——能力已并入 gepa 主库与 PyPI gepa。

仍未收敛的分歧(勿强行统一结论)#
| 主题 | 常见做法 | 嘉宾论点 | 证据边界 |
|---|---|---|---|
| Agent vs 固定 workflow | 产品层二选一 | 对 系统构建者 同为 LLM+控制流;差别在控制流谁写 | 演讲者观点;LangProBe 兼收 AppWorld 与固定管道 |
| 领域知识进 prompt 还是权重 | 微调派 vs prompt 派 | 先提取进 prompt,再编码进权重更高效 | MMGRPO 未在 GEPA 论文出现;mmgrpo_runs 无公开 README |
| Train-then-generalize vs test-time | 单一部署 prompt | 前者反馈应可迁移;后者可超专用(如具体 compiler error) | §5.1 + 演讲者观点 |
| 一次失败 rollout 是否够用 | RL 需大量对比轨迹 | 「as few as one」 | 论文写 “few rollouts”;「一条就够」为演讲者观点 |
| GEPA vs JEPA 名称 | 对外 GEPA | 团队内部曾称 JEPA | 演讲者观点(Yann LeCun JEPA 命名冲突背景) |
| 小模型 + 搜索 vs 超大模型 | 堆参数 | 350M 经搜索可超 500B(主持人转述) | 本集无实验名;无法验证 |
| 多样性来源 | 高温 best-of-N | Pareto + reflective mutation 即可探索解空间 | 论文强调多样性;与 best-of-N 严格等价未证 |
DSPy 集成状态(截至 2026-05 检索):dspy.GEPA 已存在于 DSPy main,PyPI 包 gepa 可独立安装;播客录制时「数日内并入」的 具体日期无法反推,但当前工程上已可跟 官方教程 试用。嘉宾路线图 MMGRPO(先 prompt 再 RL 写权重)与 GEPA-like reflection for weight updates 在论文与 arXiv 检索中 均无对应条目,写作时勿与 README 提到的 BetterTogether 混为一谈。
若你要落地#
- 先写清 (\mu) 与 (\mu_f):失败时模型应看到什么文本(编译错误、judge rubric、泄漏检测说明),再选
dspy.GEPA或gepa.optimize();开放域仅 score、无 verifier 时预期应保守。 - 划清验证集角色:(D_{\text{pareto}}) 用于按实例记分与 Pareto 采样;不要把「训练集泄漏进选择」误当成 bug——inference-time 模式 故意 让 train=pareto(§5.1)。
- 预算按
max_metric_calls规划:相对 GRPO artifact 的数千 rollout,GEPA 营销/README 常提 100–500 次量级;与论文 35× 同向,但以你的 metric 成本为准。 - 别只 mutate aggregate 冠军:确认
frontier_type="instance"(默认)符合你的多任务/多技能 instruction 需求;有多目标时用objective_scores。 - 引用数字用论文:主表 +6% / +20% / 35×;kernel 与 NPU 写 §5.1 初步实验;嘉宾 25% 仅作口述差异脚注式说明,不作 SLA。
参考与延伸阅读#
- GEPA 论文(arXiv:2507.19457) — Genetic-Pareto、六任务与相对 GRPO/MIPROv2 指标
- GEPA 论文 PDF — Fig.3–4 算法与 §5.1 inference-time
- gepa-ai/gepa —
GEPAEngine、gepa.optimize()API - gepa-ai/gepa-artifact — 复现实验与 GRPO/MIPROv2 配置
- DSPy 仓库 — language program 与 teleprompter 生态
- DSPy GEPA 教程 — 集成用法
- DSPy GEPA 源码 —
GEPAFeedbackMetric、@experimental - LangProBe 论文(arXiv:2502.20315) — compound AI benchmark 定义
- LangProBe 仓库 — AppWorld、HoVer 等程序集
- PUPA 数据集 — 隐私改写 + judge 反馈
- optimize_anything 介绍 — 文本参数进化
- PyPI: gepa — 安装与版本
- MAP-Elites(QD 类比背景) — 非 GEPA 引用,仅供理解 Pareto-per-instance
- BetterTogether(arXiv:2407.10930) — GEPA README 提及的「GEPA + RL」互补方向,≠ MMGRPO
- MIPROv2 实现(Optuna) — 与 GEPA 对照的 Bayesian 搜索侧


