
Judge-Time Compute:当 LLM 评测从「单次打分」变成可组合管线#
生产里的 RAG、Agent 与护栏,最终都要回答同一类问题:输出是否可信、可审计、可迭代。常见做法是跑静态 benchmark、挂一个 LLM-as-a-judge,或把 DSPy 的 metric 接到优化环里。Haize Labs 联合创始人 Leonard Tang 在公开访谈与开源项目 Verdict 中提出另一条轴:judge-time compute——在评判阶段堆叠结构化、可组合的弱模型调用,而不是默认「最贵模型评一次就够」。
这条轴与「把 eval 当成发布前 checklist」不同:它把 judge 本身当作可工程化的子系统——有 schema、有执行树、有一致性指标,并能嵌进 RL、red-team 或 guardrail 蒸馏链路。本文把可核对文档与仍属演讲者观点或未公开细节分开写;不同 benchmark 上的结论并不收敛为单一配方,读者应带着自己的 SLO(延迟、美元/千次评判、可解释性)做条件判断。


问题空间:评测、偏好与「Eval 公司」在争什么#
为什么静态榜单填不满企业落地#
行业习惯把「做 eval」等同于再做一个 SQuAD 式数据集或 LMSYS Chatbot Arena 式 Elo 榜。Leonard Tang 的立场(演讲者观点)是:多数企业没有接近 SQuAD 的标准答案集;真实需求是在极少偏好信号下,训练客户自有 judge,并尽量少问人。这与「for loop 跑分 → 表格」的 UX 并不矛盾——他认为表格类展示已相对成熟;缺口在领域专家如何标注当前 judge、以及如何把标注致密化成自动化 reward。
从工程分工看,静态集适合回归「模型版本是否退化」;偏好集适合对齐「哪一个回复更像我们品牌/合规」;fuzz 适合在尚无生产 trace 时模拟恶意或边界用户。三者预算不同:静态集一次性标注贵但运行便宜;偏好标注便宜单次但难规模化;fuzz 算力开销大却能发现单点 judge 漏掉的系统性漏洞。访谈并未声称替代 MLOps 可观测性,而是强调 eval 与 red-team 应共享同一套 judge 语义,避免线上指标与离线评委各说各话。
| 范式 | 常见做法 | 访谈中的张力 |
|---|---|---|
| 静态评测 | 有 GT 的数据集 + accuracy | 企业数据形态往往只有输入、无标准输出 |
| 偏好评测 | Pairwise / Arena Elo | 需要定制 judge + 主动选样标注 |
| 对抗测试 | Red-team、jailbreak 搜索 | Haize 强调 fuzz 用户交互,而非只做 leaderboard |
机制与约束#
Haize 自定位为定制 reward model(评委)与用户交互模拟(fuzz testing)(演讲者观点),DNA 来自对抗鲁棒性而非可观测性仪表盘。公开仓库侧:get-haized README 写明含 red-teaming, fuzzing, and optimization algorithms;访谈中提到的 VAE、reverse LM 等未在已查 README 中出现(证据边界:访谈列举 ⊃ 公开文档)。
怎么做(最小心智模型)#
先定三类对象,再选工具,而不是先选「eval 平台」:
- 被测系统(RAG / agent / 生成器)
- Judge 管线(单次 vs 多路 + 聚合)
- 人类信号入口(全量打分 vs 对比式 A/B + 质性理由)
常见误区#
- 把「评测公司」默认成 benchmark 厂商——访谈明确区分(演讲者观点)。
- 在几乎没有偏好数据时仍照搬学术静态集——与落地数据形态可能脱节(演讲者观点)。
- 只买「eval 平台」却不建设领域专家工作流——表格再漂亮,judge 仍可能与业务标准错位。
证据边界:客户名单(OpenAI、Anthropic、AI21 等)、融资与定价均为访谈口述;对比 Patronus Lynx/Glider 等行业产品时,应视为外部参照而非 Haize 能力证明。
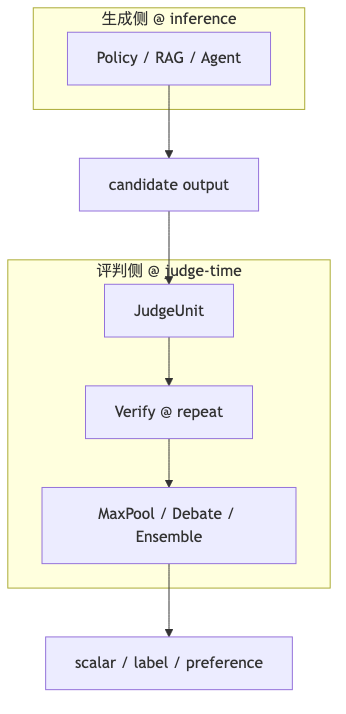
Judge-Time Compute 与 Test-Time Compute#
为什么命名值得较真#
Test-time compute 通常指生成侧在推理时加搜索、自洽或验证——例如让模型对同一 prompt 采样多条再选最优,或在代码任务上做 execution-based filtering。访谈中主持人曾口误为 test time;Leonard 坚持 judge-time compute:把额外算力花在评判路径上,且评判本身可以是并行探针 + 串行 verify + 聚合,而非单次 forward。开源 Verdict 论文 标题与 README 均使用 judge-time compute,并写明归纳偏置来自 scalable oversight(debate、ensembling 等)——已核实。
若你的系统已经在生成侧用了 o1 式长推理,再在 judge 侧堆同等规模的推理,成本会近似相乘。judge-time compute 的经济性来自:多次小模型 + 结构化输出 的方差降低,而不是简单把 judge 也换成 reasoning model。是否采用,应看 judge 错误是「随机噪声型」还是「系统性盲点型」——前者适合 ensemble,后者可能需要改 rubric 或引入领域工具(检索、计算器、规则引擎)。
机制:与 scalable oversight 的对应关系#
Weak-to-strong generalization 与 weak LLMs judging strong LLMs 讨论的是:弱监督者能否约束更强模型。Verdict 把 debate、ensemble、verify 等模式做成可组合原语(DebateUnit、ModelEnsembleJudge、MaxPoolUnit 等,见 仓库)——已核实类名与论文引用;访谈中的「wargaming」无名为 Wargame 的内置 primitive(术语为访谈用语)。
怎么做#
区分两条预算线:生成 token 与 评判 token。若 SLO 允许,优先在 judge 侧做 repeat、pairwise 与 pool,再考虑是否上 o1 类推理模型做单次评判——后文 P05 会说明这不总划算。
常见误区#
- 把 DSPy MIPRO 式「复合系统 + 元优化」与 judge-time compute 划等号——Verdict 可作 DSPy
metric,但归纳偏置不同(访谈观点 + cookbook 已核实集成)。 - 假设「验证一定比生成便宜」——RAG 下若 judge 还要判定 retrieval 是否正确,难度可逼近完整 agent 任务(演讲者观点)。
Verdict:声明式 Judge 管线#
为什么需要库而不是每次手写 debate#
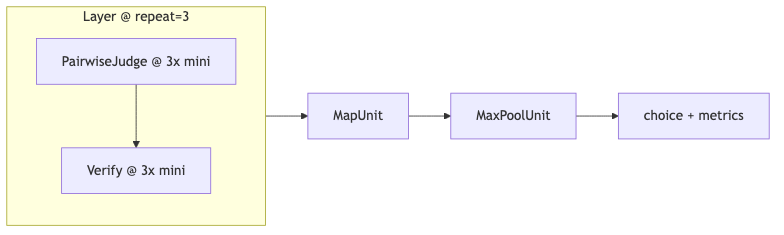
为客户重复搭 judge → verify → vote 流水线,被归纳为开源库 Verdict(演讲者观点与 README 动机一致)。核心是 Unit / Layer / Block / Pipeline 组合,以及 CategoricalJudgeUnit、PairwiseJudgeUnit、BestOfKJudgeUnit 等 judge 原语——已核实于 README Quickstart。Layer 的 repeat 语义是复制整段子图(例如 judge+verify 各一份),而不是只对最后一层采样;这与「同一 prompt 调三次 API 取众数」在实现上相关但抽象层级更高,便于在可视化执行树里对齐延迟与成功率。
访谈还列举多种 debate 变体:并行辩手 + meta judge、round-robin、打乱顺序、pros/cons 双 judge 等。公开代码提供 DebateUnit、ConversationalUnit 等积木,但没有一键「全自动选最优 debate 拓扑」——拓扑选择仍依赖任务与人工实验(演讲者观点 + 源码 已核实有 primitive、未核实自动搜索)。
机制:Judge → Verify → MaxPool#
演示帧与 README 一致(OCR 中 gpt-40、CategoricaljJudgeUnit 为识别误差):
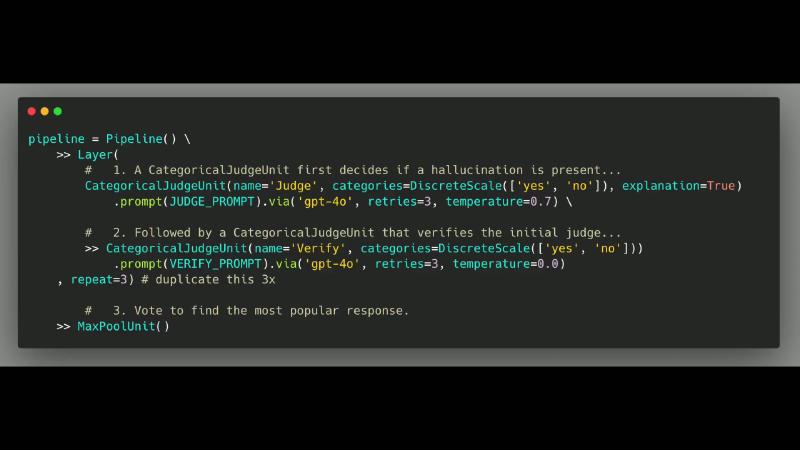
CategoricalJudgeUnit(name='Judge'...) → CategoricalJudgeUnit(name='Verify'...) → repeat=3 → MaxPoolUnit();via gpt-4o,temperature 0.7 / 0.0。
MaxPoolUnit 对 categorical 字段取众数;Layer(..., repeat=3) 复制整条子层——已核实。
怎么做(最小示例)#
pipeline = Pipeline() \
>> Layer(
CategoricalJudgeUnit(name='Judge', categories=DiscreteScale(['yes', 'no']), explanation=True)
.prompt(JUDGE_PROMPT).via('gpt-4o', retries=3, temperature=0.7) \
>> CategoricalJudgeUnit(name='Verify', categories=DiscreteScale(['yes', 'no']))
.prompt(VERIFY_PROMPT).via('gpt-4o', retries=3, temperature=0.0)
, repeat=3) \
>> MaxPoolUnit()
「Declarative」在开源侧主要指 schema 校验与 pipeline 拼接(演讲者观点:商业侧 prompt/pipeline 优化器未完全开源)。
常见误区#
- 以为开源包内含与 DSPy MIPRO 同级的自动 prompt 搜索——访谈称优化器为商业「核心 alpha」(演讲者观点)。
- 忽略
Verify与Judge可用不同 temperature——演示刻意用 0.7 生成解释、0.0 做核验(已核实于 README)。
Pairwise、一致性与执行树#
为什么单次 categorical judge 不够#
事实性、groundedness、内容审核等任务常需要 pairwise 比较与结构化输出:模型不仅输出 yes/no,还要给出可审计的 explanation,以便人类修正 judge 的推理链而非从头写 rubric(演讲者观点)。Verdict 提供 PairwiseJudgeUnit + StructuredOutputExtractor,实验面板展示 Agreement (N=10 samples) 及 Cohen κ、Kendall τ、Spearman ρ——已核实于 experiment.py 与 hierarchical notebook。
演示样本涉及新闻式声明(如运动员退赛、企业销售数据)与文档对照:Streaming 面板展示 judge 如何在「大体一致」与「细节不符」之间折中。这类 UI 的价值在于把失败样本定位到执行树节点(某次 verify 0/10),而不是只给一个总分——对工程迭代比 leaderboard 名次更直接。
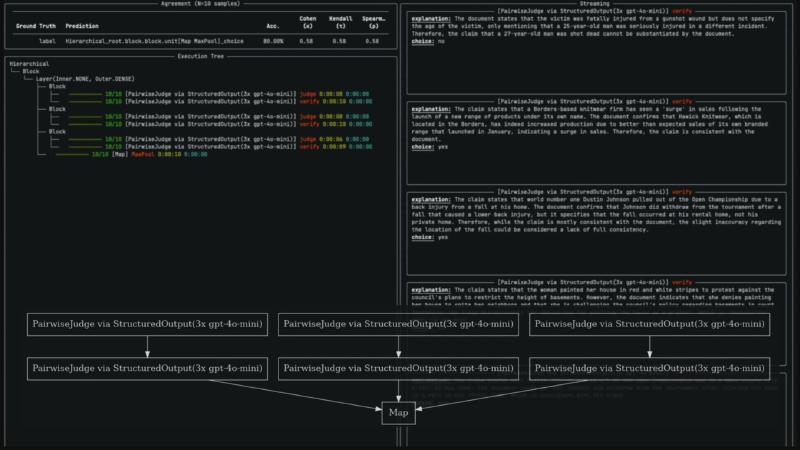
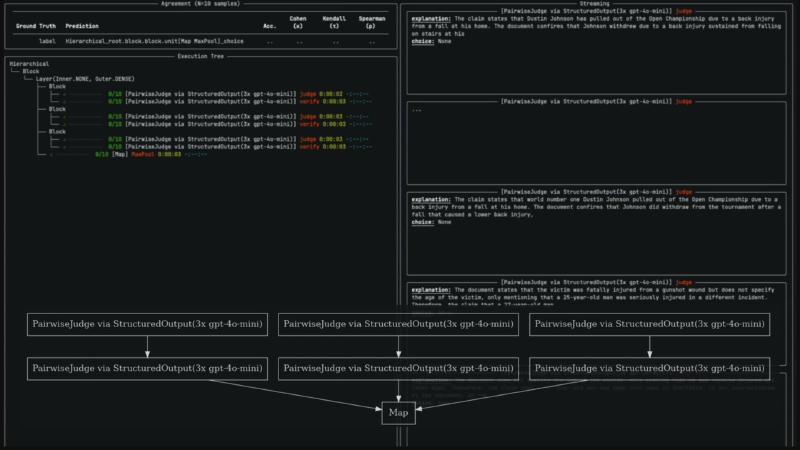
机制:Map + MaxPool 层级#
执行树标签 Hierarchical_root.block...unit[Map MaxPool]_choice 来自运行时可视化(非独立 DSL 关键字 Hierarchical_root)。MapUnit 并行多路 judge/verify,再 MaxPool 聚合——与 OCR 及源码一致(部分核实:OCR 中 3x gpt-4o-mini 与 notebook 默认 gpt-4o 配置未必相同)。
指标含义:Acc. 为 (ground_truth == prediction).mean();κ/τ/ρ 衡量评价者一致性,不是 pass@k 或 MRR(已核实)。
怎么做#
在上线前对 judge 管线跑小规模 Agreement 面板:若 κ 长期偏低,先修 prompt/schema,再加模型档位;勿把单次 demo 的 80% Acc. 外推到全量生产。建议同时记录 每节点延迟(执行树中的 0:00:08 类计时)与 verify 通过率,避免只优化 Acc. 导致 verify 步形同虚设。
对 pairwise 任务,明确「比较对象」是 两回复、回复与文档,还是 回复与检索片段;三者 rubric 不可混用。StructuredOutputExtractor 的价值在于把 explanation 与 choice 拆成可解析字段,便于下游规则(例如 choice=yes 但 explanation 含否定词则触发人工复核)。
常见误区#
- 把 Cohen κ=0.58 直接解释成「业务准确率 58%」——二者量纲不同。
- 认为 debate / round-robin / 打乱顺序等变体 Verdict 都已「一键开关」——多为可组合原语,需自建 pipeline(演讲者观点 + 源码 已核实有
DebateUnit)。
弱模型堆叠 vs 强单次模型:数字边界#
为什么「评测必须用最贵模型」值得怀疑#
访谈称多路 LLM judge 相对单次 judge 与前沿推理模型可有约 10–20% 绝对提升(演讲者观点)。论文 arXiv:2502.18018 报告的是分任务数值,例如幻觉检测情境下 Verdict(GPT-4o) 相对原 SOTA 约 +14.5 pp,换 GPT-4o-mini 仍 +3.05 pp;ExpertQA 上 Verdict(4o) 79.17% vs o1 69.91%(约 +9.28 pp);XSTest 上 Verdict 96.44% vs o1 96.00%(约 +0.44 pp)——已核实,且不能合并为统一 10–20% 常数。
读表时建议固定三个问题:(1)指标是 percentage points 还是相对提升?(2)基线 judge 是否与 Verdict 公平(同 prompt 预算、同温度)?(3)任务是否与你生产分布同域——内容审核接近饱和时,0.44 pp 与 14.5 pp 对业务含义完全不同。论文背景还引用 generative verifier / Best-of-N 文献中的「16–40% improvement」语境,那是另一套问题设定,不可直接贴到 Verdict 管线(证据边界)。
| Benchmark | Verdict (4o-mini) | o1 | 解读 |
|---|---|---|---|
| ExpertQA | 67.72% | 69.91% | mini 堆叠未超过 o1(已核实) |
| ExpertQA | 79.17% (4o) | 69.91% | 4o backbone 的 Verdict 高于 o1 |
| JudgeBench | mini 50.00% | 75.43% | 即使 Verdict(4o) 63.55% 仍低于 o1 |
成本方面 README/论文定性称「fraction of cost and latency」;访谈提到 prefix / KV cache 跨阶段复用(演讲者观点,skunkworks 未在公开表给出统一货币倍数)。
机制#
逻辑是:结构化冗余 + 聚合 用多次弱调用换单次强推理;是否划算取决于任务难度与 judge 方差。论文 Figure 3 的 Pareto 叙述支持「部分任务上更好且更便宜」,非全 benchmark 支配 o1/o3-mini。
访谈中的工程 skunkworks 包括:跨 Verdict 阶段复用 prefix / KV cache;必要时对 prefix 加 nonce 以换取多样性(演讲者观点)。这在 API 计费模型下可能显著改变「多次 mini 调用」的总成本,但具体节省比例未在公开论文中以统一货币标注(证据边界)。自建部署若掌控权重与缓存,judge-time compute 的经济账可能与纯 API 用户不同。
怎么做(成本粗算心智模型)#
记 (C) 为单次强 judge 成本,(c) 为单次 mini 调用成本,(k) 为 repeat 次数,(r) 为 verify 是否启用(2 倍链长)。粗略上 Verdict 单层成本 (\approx k \cdot r \cdot c)(再加 pool 的 negligible 开销)。仅当任务误差主要来自随机性而非 rubric 错误时,增大 (k) 才单调有益;否则应优先改 prompt / schema / 工具。
常见误区#
- 泛化「gpt-4o-mini 堆叠 beat o1」——ExpertQA / JudgeBench 上不成立(已核实)。
- 用营销句 beat reasoning models like o1 代替具体表号——应注明 backbone 与数据集。
对齐客户 Judge:标注 UX、RL 与 Meta Judge#
为什么「有标注就 SFT」在 judge 上可能被质疑#
Leonard 主张基本不做 judge 上的 SFT(易过拟合、损害隐式推理,演讲者观点),主推 RL + judge-time scaling;奖励来自 meta judge(用 Verdict 等堆叠 judge 评 judge,在少量客户数据上「方向正确」并由 reward 聚合抵消误差,演讲者观点)。公开文档无法核实三层框架 (实现 / 查询 / UI) 与 active labeling 算法细节。
三层设计在访谈中的表述是:(1)judge 实现与学习算法;(2)查询哪些样本让人标注;(3)UI 如何呈现——且只展示对「当前训练中的 judge」有显著影响的样本(演讲者观点)。这与传统 active learning 的 uncertainty sampling 类似 spirit,但目标函数是「提升 judge 而非提升生成器」。若你团队只有几十条标注,优先把预算花在边界对(模型最不确定的 A/B)上,比均匀撒点更能拉动 κ。
参数更新方面,访谈提到「超越 LoRA」的激进省参方案,细节未公开——落地时不应假设存在即插即用权重;更现实的起点是用 Verdict 作 离线金标准生成器,再蒸馏到小模型进在线路径。
机制:对比式信号与三层设计#
访谈强调 对比式回答(同输入两回复 A/B)收集「为何 A 优于 B」的质性梯度,优于不稳定的人类 1–10 分(演讲者观点)。这与 RLHF/DPO 的 pairwise 范式精神相近,但不能反向证明 Haize 产品实现(证据边界)。
Meta judge 与 DeepSeek 通用 RM 推理时扩展 方向一致:论文用 SPCT、推理时自适应 principles + critiques、Voting@k / MetaRM@k——已核实标题与方法;访谈的「instance-specific rubric」宜读作概念类比,论文正文用 principles / critiques(非逐字术语)。
LMUnit(Contextual AI,非 Stanford 主导项目)用自然语言 unit test + 打分模型做细粒度 eval——与「in-context LLM scoring」相近;访谈称「Stanford LM-Unit」易误导(已核实机构归属)。
怎么做#
若你要自建对齐环:优先设计 pairwise + 理由 的标注 UI,再决定 RL 还是 DPO;SFT judge 前先用 Verdict 管线测 Agreement 与任务 Acc. 的分离趋势。
常见误区#
- 把 meta judge 当成无误差 oracle——访谈明确需堆叠与聚合降噪(演讲者观点)。
- 忽略人类迭代的是 judge 的 reasoning 而非从头写 rubric——工作流主张,无公开 benchmark。
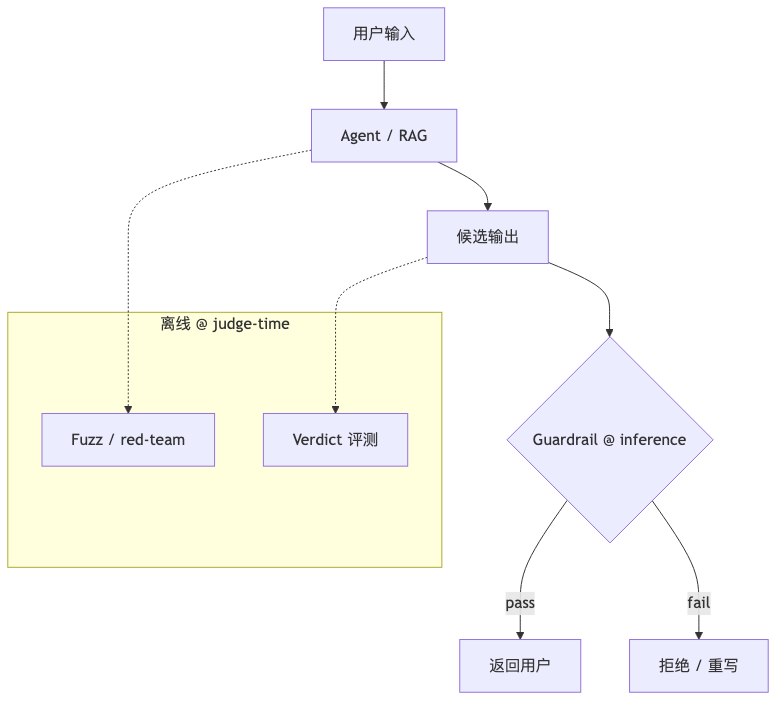
RAG、Fuzz 与生产护栏#
为什么 RAG 打破「验证比生成易」#
若 judge 只查 answer 是否 grounded in 已给 context,验证往往轻于生成;若还要判断 检索到的 context 是否正确,则等价于重做 retrieval(演讲者观点)。Parametric knowledge conflict(上下文与参数记忆冲突)可用有/无 context 的反事实 diff 定位,但无通用解(演讲者观点)。工程上可把 judge 拆成两级:一级只评 cite 是否支持句子;二级在抽样或高风险请求上才启动 retrieval 审计(额外索引查询、版本号、来源白名单),避免每条用户消息都付 agent 级代价。
生产案例在访谈中以定性方式出现:轻量 judge 进入 agent 推理环、Constitutional Classifiers 与幻觉检测蒸馏等(演讲者观点,无公开复现包)。这与「评测只在离线跑」不同——guardrail 本质是 judge-time compute 的在线子集,延迟预算更紧,通常必须蒸馏。
Fuzz 与 Agentic Eval#
公开侧:BEAST-implementation 为 beam search 对抗攻击(对应 arXiv:2402.15570),dspy-redteam 多层 attack/refine。Agents for evals 被描述为 judge-time compute 结构更松的形态:多 token、多步;部分任务 judge 需与生产系统同等的 agentic 能力(演讲者观点)。
Fuzz 与静态集互补:前者发现 输入分布尾部(越狱、诱导泄露、畸形 JSON),后者监控 已知业务问答 回归。若只有 fuzz 没有金标 judge 校准,容易陷入「攻击成功率下降但用户体验变差」的假象——仍需人类或高保真 Verdict 管线定义什么是「坏」。
通用 judge + 单 prompt 覆盖任意垂直场景,访谈认为「不合理且不可能」(演讲者观点)。落地默认路径应是:领域 rubric / unit test(可参考 LMUnit 思路)+ 少量偏好数据 + judge-time compute 降噪,而不是等待一个 70B 通用幻觉检测器解决所有行业。
护栏:安全 vs 合规#
云厂商(Azure、Bedrock 等)内置安全过滤对许多客户「够用」(演讲者观点);企业更常缺 行业 / 品牌 级 guardrail。路径主张:高保真 judge(Verdict + 训练)→ 蒸馏到小模型、压延迟(演讲者观点)。Patronus Lynx/Glider 等仅为行业对照,非 Haize 产品声明。
常见误区#
- 再叠一层通用 safety API 即等于业务合规——访谈认为需求常在定制(演讲者观点)。
- 把 mechanistic interpretability(SAE 等)当作短期可审计工具——嘉宾认为仍脆弱,可行动性有限(演讲者观点)。
Verdict × DSPy:metric 钩子,不是替代框架#
为什么两个框架常被打包讨论#
DSPy 被类比为「LLM 版 PyTorch」:用 program + teleprompter 优化 prompt 与模块图。Verdict 则提供 judge 侧的声明式原语 与 scalable oversight 偏置。二者交集在 评估函数:DSPy 文档中的 metric 接收 example、pred、可选 trace,返回标量或布尔信号,驱动 Evaluate 与 MIPRO 等优化器。
Verdict 可作为 program 的 metric(已核实:dspy.md cookbook、dspy-redteam 中 metric(..., use_verdict=True) → verdict_judge() → ModelEnsembleJudge)。这意味着:你可以在 同一套 DSPy 程序 上,用 Verdict 堆叠 judge 作为「更贵的 metric」,而不必把 debate 逻辑写进每个 signature。
机制与边界#
- 已核实:
dspy-redteam将 ensemble Verdict pipeline 接到dspy.evaluate.Evaluate。 - 演讲者观点:Verdict 也可作 guardrail / RL reward,DSPy 只是集成示例之一。
- 已核实:集成前建议
litellm.cache = None,避免 LiteLLM 与 Instructor 交互问题。
Omar Khattab (okhat) 在 contributors 中有提交(已核实关联账号;访谈「大量 feedback」无法用 commit 数完全印证)。
怎么做#
若你已在 DSPy 里用简单 answer_exact_match 或单次 LLM 打分,可渐进替换为 Verdict pipeline:先保持 优化目标不变,只替换 metric 实现,对比 pass rate 与优化迭代次数;再考虑是否把 judge-time compute 的开销纳入 teleprompter 预算。
常见误区#
- 以为接上 Verdict 就等于「DSPy 会自动帮你搜 debate 拓扑」——开源 Verdict 未包含与 MIPRO 同级的 pipeline 搜索器(演讲者观点:商业优化器未全开源)。
- 在 metric 内开启过多
repeat导致 MIPRO 每一步评估成本爆炸——应对开发集做子采样或分层评估。
理论缝隙与未来工作(不给出统一答案)#
访谈 closing 提到:DPO / PPO / GRPO / KTO 等为何能用 pairwise preference 拟合 reward,在理论上仍欠完整解释(演讲者观点)。这与工程现实并存——团队已经在用 preference 训练,但 reward model 设计(含 judge-time compute、meta judge、generative RM)仍大量依赖经验与 ablation。
另一条线索是 superintelligence 定义漂移:图灵测试、销售角色扮演、棋类 vs 日常任务(如 Slack 得体回复)标准不一(演讲者观点)。对从业者更实用的结论是:无论宏观叙事如何,verification、steering、evals 仍是可投资的工程主轴——只是要把「评什么」与「花多少 judge 算力」说清楚。
Haize 2024 年商业化、曾服务多家模型厂商发布前测试等陈述属 访谈口述,未独立核实;读者在采购或对标时应要求可复现 benchmark 与合同范围内的数据处理方式,而非仅依赖品牌叙事。
最后强调证据分级:标 已核实 的陈述可在 PR 评审中附 arXiv 表号或 GitHub 行链;标 演讲者观点 的陈述应进入「待 ablation」清单,而非写进对外 SLA。未标注处默认按工程常识理解,不视为 Haize 官方承诺。对架构师而言,可把本文读作三张叠图:(1)数据形态(静态 / 偏好 / 对抗)决定采集成本;(2)算力形态(test-time vs judge-time)决定错误从哪一侧被消化;(3)部署形态(离线评测 vs 在线 guardrail)决定能否蒸馏与缓存。任一层选错,都会在另一层以隐性债务出现——例如只用静态 Acc. 却在生产遭遇分布外越狱,或在线挡板过严导致可用性崩溃。没有一张图能单独给出「买哪家」的答案。
若你要落地#
- 先画清评判边界:只评 groundedness,还是要评 retrieval 正确性——后者预算应接近 agent 子任务,而非单次 LLM 打分。把 judge 输出 schema(label + explanation + cite spans)写进接口契约,便于与产品审计日志对齐。
- 用 Verdict 或等价原语搭 Judge→Verify→Pool,在 10–50 条金标上跑 Agreement(κ/τ/ρ)与 Acc.,再扩 benchmark;引用论文表号时写清 backbone(4o vs 4o-mini)与数据集。κ 低时先查标注指南是否含糊,再堆模型。
- 偏好数据稀缺时,优先对比式 A/B + 理由的标注 UX,再选 RL/DPO;勿默认 judge SFT(访谈反对点需你用自家 ablation 验证)。Meta judge 仅作方向信号时,保留人类抽检通道。
- 上线护栏:离线用 get-haized / dspy-redteam 类 fuzz + Verdict;在线蒸馏小 judge,并区分云厂商安全过滤与品牌合规规则。记录「拒绝/重写」触发节点,避免黑盒挡板。
- 与 DSPy 集成时把 Verdict 当
metric而非整个优化栈——生成优化与 judge-time scaling 分开预算与观测;优化迭代中固定 judge 版本,否则 teleprompter 在追移动靶。 - 对外沟通:避免用单一百分比概括多 benchmark;对内用执行树定位失败层(judge vs verify vs pool),对外用任务域 SLA 说话。
参考与延伸阅读#
- Verdict 论文(arXiv:2502.18018) — judge-time compute 与 benchmark 表
- Verdict GitHub 仓库 — API、Quickstart、Debate/Ensemble 原语
- Verdict 文档站 — 使用指南与结果页入口
- Haize Labs GitHub 组织 — 相关工具链索引
- Awesome LLM Judges 列表 — 论文与实现合集
- DSPy 官方文档:Metrics —
metric契约与评估环 - Verdict × DSPy Cookbook — 集成示例与缓存注意事项
- dspy-redteam 示例 — Verdict 作 red-team metric
- Weak-to-strong generalization(OpenAI PDF) — scalable oversight 背景
- Weak LLMs judging strong LLMs(arXiv:2407.04622) — 弱评委监督强模型
- Generative Verifiers(arXiv:2408.15240) — 生成式验证与 test-time 叙述
- DeepSeek:Inference-Time Scaling for Generalist Reward Modeling(arXiv:2504.02495) — 推理时扩展 generalist RM
- LMUnit(arXiv:2412.13091) — 自然语言 unit test 式细粒度评测
- LMSYS Chatbot Arena 技术报告(arXiv:2403.04132) — 偏好/Elo 范式
- Get Haized / fuzzing 套件 README — 自动化 red-team 与 fuzz 入口
- BEAST 对抗攻击论文(arXiv:2402.15570) — 离散搜索式 jailbreak(与访谈技术栈部分重叠)


