
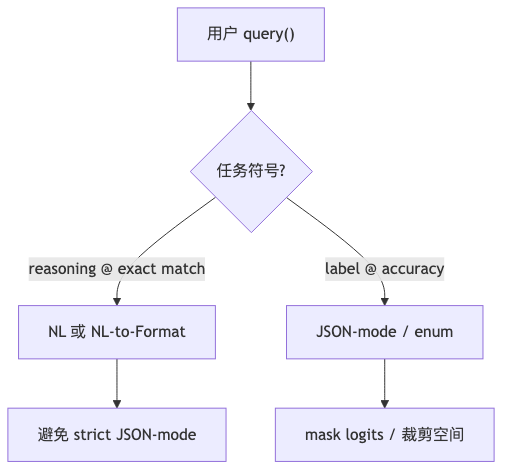
格式约束何时伤害 LLM:从 Agent 流水线到基准评测的分叉#
向量检索、工具调用与多步 Agent 把 LLM 嵌进 Compound AI 流水线:中间态要可解析、可路由、可重试。工程上于是广泛采用 JSON 在步骤间传参;公开榜单与学术基准却仍以自然语言(NL)终答案为主,用 exact match 或 accuracy 打分。Appier AI Research 的 Zhi Rui Tam 在论文 Let Me Speak Freely? 中把这一分裂做成可复现实验:同一套「结构化输出」技术,在推理任务上常降分,在离散分类上常涨分。下文按机制拆解,不给出单一结论——任务符号、API 代际(JSON-mode vs JSON-schema)与 schema 深度会改写符号。
生产与评测为何脱节#
为什么:编排框架(LangGraph、CrewAI 等)需要可解析的中间态;运维与 eval harness 却习惯用 exact match / accuracy 对 NL 终答案打分。若线上全程 JSON mode 或 Structured Outputs,而榜单只报 NL 分数,部署表现与公开排名可能系统性错位(论文 Introduction 与 Compound AI Systems 动机一致)。
机制:格式限制改变 decoding 的 token 空间——不仅是后处理,而是生成轨迹本身被裁剪或偏置。
怎么做:在自家 dev set 上并行报告 NL、FRI、JSON-mode 三条曲线;若使用 OpenAI Structured Outputs,单独成第四条——其与 JSON-mode 在 GSM8K 上可差近 5 pp(Table 2: 91.71 vs 86.95)。Agent 基准应显式包含「步骤间 JSON」条件(论文呼吁;PlanBench 可作为规划类补充,主实验未使用)。RAG 场景同理:检索片段可结构化,但 答案推理链 是否应受 JSON 约束,需与任务符号一起 A/B,而非默认全程 schema。
误区:把「榜单 SOTA」直接等同于「JSON 流水线 SOTA」,未做格式对齐对照。
po Dilamllr My, y te,)。
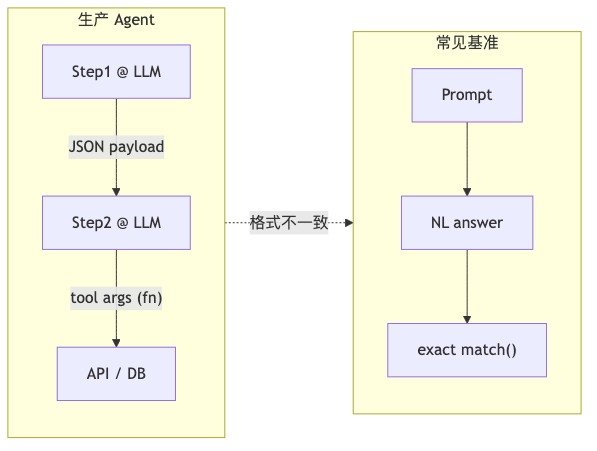
约束生成谱系:FRI、JSON mode、两阶段、Function calling#
| 路径 | 约束位置 | 典型保证 |
|---|---|---|
| FRI(Format-Restricting Instructions) | Prompt 内嵌 schema | 无硬解码保证;易出现格式违规 |
| JSON-mode | 提供商约束解码 | Valid JSON;论文称 OpenAI/Gemini 侧与 function calling API 实现相关 |
| NL-to-Format | 两次调用 | 先 NL 推理,再转 JSON/XML/YAML |
| JSON-schema / Structured Outputs | Schema + strict | 强于旧 JSON-mode;不自动解决 reasoning 语义顺序 |
为什么:工程师常把上述名词混为「结构化输出」,但 合法语法 ≠ 正确推理 ≠ 正确字段顺序。
机制(论文):越 strict,推理集上 performance degradation 越大(摘要);分类集上 JSON-mode 因 answer space 裁剪 常优于纯文本(§5.2)。从解码视角看,约束等价于在每一步缩小 logits 支撑集:对 49 选 1 的诊断标签这是助力;对需要多步算术符号展开的 GSM8K 则可能在早期就剪掉正确推理路径。论文 Figure 1 给出典型案例:GPT-3.5-turbo 在 GSM8K 上 NL 正确,加格式限制后失败——说明损伤发生在 生成过程,而非单纯解析失败。
怎么做(最小 pipeline):
# 推理向:保留 NL 中间态(示意,非论文超参)
reasoning = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": problem}]
)
structured = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"将下列推理转为 JSON schema:\n{reasoning}"}],
response_format={"type": "json_schema", "json_schema": SCHEMA},
)
误区:
- 单次 prompt「请只输出 JSON」下结论——论文用 9 组 prompt 组合(3 任务描述 × 3 格式变体)取平均,并报告加 schema 后 敏感性上升(附录 G.2)。
- 认为 XML/YAML 在 Table 1 中偶发优于 JSON 即应全面替换——论文将波动归因 prompt variance,非格式本质。
if Ahh = 2 = = q 3 4)。
po Nilamtl Mays, Cs ra,)。
任务类型分叉:推理 ↓,分类 ↑#
为什么:推理需要长链中间符号(算术、字母拼接);分类答案往往已在预训练分布的 离散支撑 上。
机制(已核实,论文 HTML v3):
- 推理:GSM8K、Last Letter、Shuffled Objects;指标 exact match。gpt-4o-mini 上 GSM8K:NL 94.57 → FRI 87.17 → JSON-Mode 86.95(Table 2)。
- 分类:DDXPlus(49 种疾病诊断)、Sports Understanding、NI Task 280、MultiFin;指标 accuracy。Gemini-1.5-Flash / DDXPlus:Text 41.6 vs JSON 60.3(Table 10)。
怎么做:上线前用 任务符号 分流——数学/多跳 agent 慎用全程 JSON-mode;医疗/金融式 有限标签集 可试 constrained decoding(Outlines 等同系)。
误区:
- 将播客口语「输出 1–49」泛化为任意 49 类——论文对象是 DDXPlus 的 49 diseases。
- 认为 JSON-schema 必然挽回推理分——同表 GSM8K JSON-Schema 91.71 仍低于 NL 94.57。
- 主持曾假设 JSON 分布强烈拉高分类;论文与讨论均承认 分类侧机理解释仍不完整(演讲者观点 @ 分类直觉段)。
goo Milaatte May, ta,)。
Lily Hiro / fal al ii Ahh 3)。
合法 JSON 与任务成功脱钩#
为什么:工程 KPI 常先盯解析成功率。
机制:JSON-mode 保证 valid JSON(产品叙述);论文另设 Perfect Text Parser 等,区分 format errors 与 final metrics。
证据边界:嘉宾口述 约 99% 场景下 5–10 次采样 可得合法 JSON,但 final result 另论——演讲者经验,论文未给 99% 统计(P06 无法核实定量)。
怎么做:监控 parse_ok 与 task_correct 两条 SLO;重采样优先换更强模型,其次 3–10 次同 prompt(嘉宾优先级;未验证 同温 10 次 vs 9 种 prompt 何者更优)。
误区:json.loads 成功即宣告 Agent 成功。
= any Milani 7, 1 ? ~ a)。
两阶段与「先自由说,再格式化」#
为什么:Strict JSON 在生成阶段即绑定 schema,可能压缩推理所需的 中间 token 分布(嘉宾假设:解码域在 JSON / NL / LaTeX 风格间切换带来混乱——演讲者假设,非定理)。
机制(部分核实):论文 NL-to-Format 相对 NL 在多数模型上 nearly identical;相对 JSON-mode / FRI 在推理集上明显更优。播客中「much better」的对比对象是 strict JSON,不是相对纯 NL 的巨幅提升——勿过度解读。
怎么做:复杂 agent 将 规划 / CoT 留在 NL,末端单次 format_to_json();嵌套 schema 按层拆分(见下节)。
误区:把所有步骤都塞进一个巨型 JSON——嘉宾口述 ~10 层嵌套 单步质量 明显退化(访谈观点,论文无 10 层对照实验)。
) — ———_ xxii ¥ 2 —_—)。
Nilunt go Muni Nar, a ,)。
Function calling、字段顺序与 RFC 语义#
为什么:Tool call 被 marketed 为「现代 structured output」,但 JSON 对象无序(RFC 8259);OpenAPI 中 function.arguments 为字符串,properties 无顺序语义。
机制(部分核实):论文 §5.4 将 OpenAI JSON-mode 与 function calling API 关联,并记录推理任务中 reasoning 应先于 answer 的违背;结论强调 key order 与 reasoning–format decoupling。嘉宾建议:仅需 enum 级工具名 时 function calling 足够;顺序敏感 时改用可控 JSON-mode / schema——条件性建议,播客未做跨厂商 API 实测。
怎么做:若业务逻辑依赖 reasoning → answer 的呈现顺序,在协议层用 数组或分字段两次调用,勿假设 object key 顺序。
误区:把 function calling 与 JSON-schema 混为一谈——后者强化合法性,不自动 保证语义顺序(GSM8K JSON-Schema 91.71 仍低于 NL)。
iti JHE erry rai <)。
HHEIIT Hy RAEN TIER TD)。
RAG、工作流步骤顺序与 test-time compute#
为什么:检索增强与多步 workflow 常在步骤间传递结构化载荷;与「Let me speak freely」形成张力——中间步是否需要 strict JSON?
机制:论文未专门评测 RAG;讨论延伸至 步骤顺序(先检索后生成 vs 颠倒)与 test-time compute(o1 类模型更多 internal reasoning)。嘉宾自认公开 benchmark 「a bit limited」,难找「既需要 structured output 又能靠结构提分」的数据集(演讲者观点)。
怎么做:RAG 管道对 检索结果 用结构化、对 模型推理链 用 NL 的混合策略值得 A/B;规划类任务可跟踪 PlanBench。
误区:因 o1 内部链不可见,便认为外部 JSON 约束「无关紧要」——外部格式仍影响 可观测步骤 的解析与工具链接。
1 { Hl alt \. an —— ad)。
rip il if Hi hth)。
waite Ei? "7 ‘gn)。
开源约束解码:Outlines、TGI、Llama 3 8B#
为什么:数据不能出域时需要自建 mask logits 式解码,而非仅依赖黑盒 API flag。
机制:论文引用 Willard & Louf (2023) 与 Text Generation Inference 的 Guidance;Outlines 提供 Guaranteed valid structure。TGI 文档描述 grammar 在 /chat/completions 与 tools 上的映射。
证据边界:嘉宾称 Llama 3 8B + TGI JSON mode 已「pretty good」——主观访谈;AI Engineer Summit 上 SQL 语法 100% 为 会场转述,播客未复现,Python/C++ 嘉宾持保留。
怎么做:隐私场景优先评估 Outlines / TGI Guidance;与 API JSON-mode 结果交叉验证。
误区:微调单一 DSL(如 GraphQL)后模型 只会 该 DSL,与多工具 Agent 接口不兼容(主持经验,嘉宾未系统反驳)。
Nilenth ae * Hayy, We te,)。
Prompt 优化、微调与评测外推#
短期: DSPy、OPRO、TextGrad 等可缓解 prompt 敏感性(嘉宾点名,未与本文实验对比)。在资源有限、尚未决定微调前,先用九套 prompt 方差估计(论文附录 G.2 方法论)可避免被单次 FRI 误导。
规模:百万用户级仍可能需要 fine-tune 压长尾(嘉宾);与格式约束正交。主持提到微调 GraphQL 后模型生成面变窄,与多工具 Agent 的开放接口存在张力——若你走微调路线,需单独验证 格式遵守 与 工具泛化 是否同时成立。
格式多样性:论文在部分 模型 × 数据集 × prompt 上 XML/YAML 优于 JSON/NL——归因于 prompt 敏感性,非格式本质优越(Table 1/9)。实验模型含 gemini-1.5-flash、claude-3-haiku、gpt-3.5-turbo、LLaMA-3-8B-Instruct(§3.3),与播客录制时口述的「最新 frontier」清单 不完全一致,外推需重跑。
XML/YAML 条件性结论已核实;勿写成「永远换 XML」。
a dat th H BS ' i ok)。
证据边界(读完全文前可先扫一眼)#
| 主张 | 状态 |
|---|---|
| 推理 strict 降分 / 分类 JSON 涨分 | 论文 Table 2、10 已核实 |
| NL-to-Format 相对 strict JSON 更优 | 部分核实;相对纯 NL「几乎相同」 |
| 99% 五次采样合法 JSON | 访谈观点,论文无此定量 |
| ~10 层嵌套单步退化 | 访谈观点,论文无对照实验 |
| Function calling 键序 | RFC 无序已核实;推理顺序见论文 JSON-mode 段 |
若你要落地#
- 按任务符号选格式:推理/数学/agent 多跳 → NL 或 NL-to-Format;离散分类(如 DDXPlus 式标签集)→ JSON-mode / enum 约束。用自家数据复现 Table 2 方向,勿照搬单点分数。
- 报告格式条件下的 eval:线上若步骤间 JSON,基准应含同条件分数,否则与 Compound AI 部署脱节。
- 拆分 KPI:
valid_json_rate与task_accuracy分开告警;重采样修语法不替代模型升级。 - 顺序敏感 schema:勿依赖 object key 顺序;考虑分步调用或数组字段(RFC 8259 + 论文 reasoning-order 观察)。
- 深嵌套 schema 分步生成:单 API 吐出「十层嵌套」成功率与表象能力分裂(访谈 ~10 层为量级比喻);先 NL 计划再逐层填表。
参考与延伸阅读#
- Let Me Speak Freely? — arXiv:2408.02442 — 格式限制对 LLM 影响的系统研究(Tam et al., 2024)
- 论文 HTML v3(含 Table 2 / DDXPlus)
- OpenAI Structured outputs 指南 — JSON-schema 与 strict 模式产品语义
- OpenAI OpenAPI 规范仓库 —
json_schema、ChatCompletionMessageToolCall字段定义 - RFC 8259 — JSON 数据格式 — 对象无序集合的 normative 定义
- GSM8K — grade-school-math — 推理类 exact match 基准
- Compound AI Systems — Berkeley BAIR — 多组件 AI 系统架构语境
- PlanBench — gpt-plan-benchmark — 规划与 agentic 评测扩展方向
- Hugging Face TGI — Guidance 概念 — grammar / JSON 约束解码
- Text Generation Inference GitHub — 自托管推理与 guided generation
- Outlines(dottxt-ai/outlines) — 约束解码与 guaranteed structure
- Willard & Louf — Efficient Guided Generation(Outlines 论文系) — 约束解码理论基础(论文引用链)
- DSPy — stanfordnlp/dspy — 声明式 prompt / 权重优化框架
- Weaviate Podcast #108 视频检索 — 官方 YouTube 发布页(检索入口,具体 watch URL 以频道为准)
- DDXPlus 数据集背景(论文引用 StreamBench 子集) — 49 类医学诊断实验设定


