
有状态 Agent 与上下文编译:从 MemGPT 到 Letta 的工程分野#
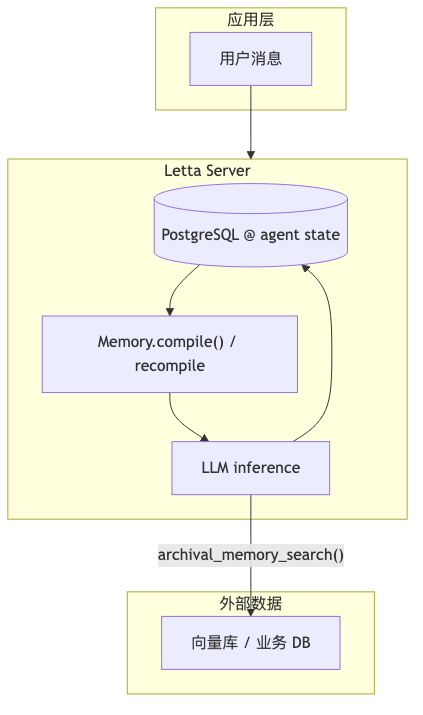
当团队把 LLM 应用从「单次 completion + 外挂向量库」推进到跨会话记忆、工具环、可回放调试时,争论往往不在「要不要 Agent」,而在三层张力:上下文谁编、记忆谁写、状态谁存。Letta(前身为 MemGPT)代表一条明确路线:把有限 context window 当作可编译的运行时视图,由框架做 Memory.compile() / recompile,由模型通过 tool 决定何时检索、何时改写 in-context 块。
这与工作流引擎(LangGraph、Temporal 等)的争论并存:后者强调可恢复、确定性步骤;Letta 侧更强调同一套 tool-call 原语既能做开放环 agent,也能用 tool_rules 搭显式 workflow(演讲者观点;节目中未给出与 Temporal 的可靠性 benchmark)。本文按可核对文档/源码与嘉宾架构观点分开叙述——不给出单一「正确答案」。
问题空间:RAG、有状态服务与「黑箱上下文」#
为什么要在 RAG 之外谈「Agent 框架」#
常见生产 RAG 把检索结果自动拼进 prompt(Simple RAG 由应用决定何时查、查什么)。有状态 Agent 路径则把「是否检索、写什么记忆」推迟到模型显式 tool call(Agentic RAG:All the RAG logic is handled by the agent)。二者不是非此即彼:同一业务里,批处理索引仍可能是应用责任;对话环上的读/写时机才是分野。
另一轴是状态持久化。无状态 API 每次带全量 history;Letta 文档将 agent 描述为 stateful agents——memory blocks、messages、tools 定义落在数据库,单步近似 读状态 → 编译上下文 → 推理 → 写回(嘉宾归纳为「agents as REST API」;实质为 REST/SDK 平台,表述宜与口号区分)。
机制:两层「数据库」#
| 角色 | 典型内容 | 谁触发读写 |
|---|---|---|
| 业务库(向量库/OLTP 等) | 文档、交易、用户数据 | Agent 经自定义 tool |
| Letta 托管库 | conversation、blocks、tool 定义 | 框架 + 内置 memory tools |
Context hierarchy 把 Memory Blocks(in-context)、Archival(out-of-context,on-demand tool)、Files、External RAG 分层——与「一切皆向量 top-k」的 naive 管线正交。
怎么做(最小闭环)#
Docker 起本地服务(官方指南):docker run -p 8283:8283 letta/letta:latest。创建 agent 时挂载 human / persona 块(Memory blocks),通过 agents.messages.create 驱动一步推理;观察 ADE 中编译后的 token 占用而非仅看最终回复。
常见误区#
- 把 Letta 当成「又一个向量库封装」——archival 需 tool 拉取,blocks 才是始终可见的 in-context 面(文档对比表已写明)。
- 假设换模型会丢 persona——Models 文档 写明换
model时 Agents keep their memory and tools(仍须自行回归 tool 兼容性)。
虚拟上下文与 Core Memory:论文脉络 vs 产品术语#
为什么 MemGPT 仍相关#
MemGPT 论文(arXiv 2310.08560)提出 virtual context management:在有限窗口内模拟更大上下文,并 intelligently manages different memory tiers(OS 式分层类比)。Letta 自述 Born from MemGPT(memgpt.ai / GitHub README)。
边界:论文摘要未出现嘉宾口中的 “self-managed / self-editing memory” 原话;Memory blocks 文档 使用 self-editing 描述块行为——宜写「产品/文档术语」,不宜写成论文定理。「第一篇」自管记忆 agent 论文(演讲者观点)未做系统性 prior-work 检索。
机制:human / persona 与工具写块#
典型 chat 场景用 human、persona 两标签(Memory blocks)。模型通过 core_memory_append / core_memory_replace 改写(base.py)。块有 limit(文档示例 chars_limit=5000;源码默认 CORE_MEMORY_BLOCK_CHAR_LIMIT 更大——创建时以配置为准)。
嘉宾观点:persona 不仅做人格,还可写入用户反馈,使后续每轮都带上可读「在线学习」,相对 fine-tune 更易审计。对立面来自生产 RAG 圈(如 Contextual AI 访谈 中把偏好写进权重的路线)——fine-tune 需要数据集、评测闭环与冲突解释(mechanistic interpretability 仅被点名,未展开)。
| 路径 | 优势(归纳) | 成本/风险 |
|---|---|---|
| In-context blocks | 人类可读、可手改、ADE 可见 | 占 token;模型可能写错 |
| Fine-tune 权重 | 推理时零额外 token | 数据与 eval 投入;与显式记忆冲突难 debug |
本文不裁决产品选型;若合规要求可审计记忆,文档支持的 self-editing blocks 更贴近证据链。
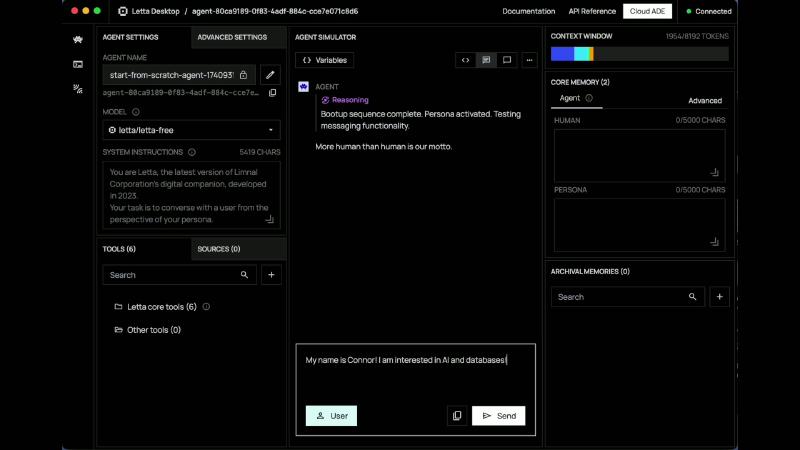
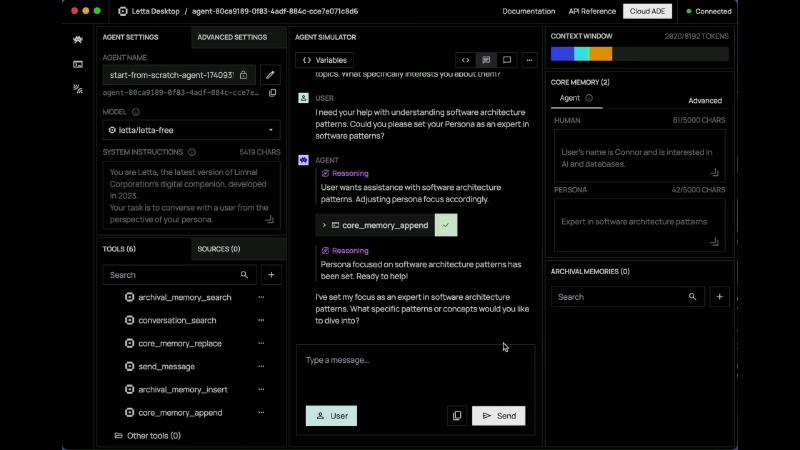
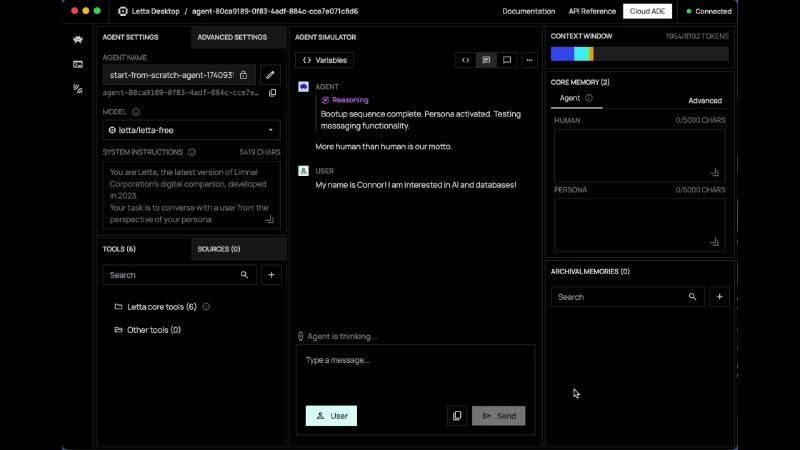
怎么做#
# 概念示意:创建带双块的 agent(字段名以 SDK 为准)
memory_blocks=[
{"label": "human", "value": "...", "limit": 5000},
{"label": "persona", "value": "...", "limit": 5000},
]
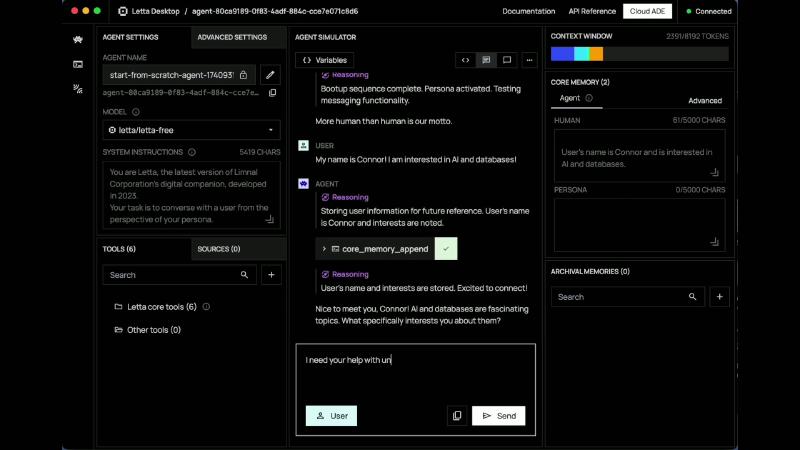
Bootup 后 Simulator 可见 token 从 ~1954 升至 ~2391(节目 OCR:ocr_pick_002 AGENT SIMULATOR CONTEXT WINDOW 2391/8192 TOKENS)——说明系统指令 + 块 + 消息共同吃掉预算,调试时要看编译结果而非单条 user message。
常见误区#
- 以为 core 块「自动同步全网事实」——块内容是 LLM 选择写入 的摘要,错误会固化(需 archival 纠错或人工改块)。
- 把 5000 字符当作全球统一上限——OCR 与文档示例一致,非源码默认上限的唯一真值。
上下文编译 vs 长窗口:预算工程,非「窗口越大越好」#
为什么 200k 模型仍可能只用 ~30k#
行业常见做法:上下文变长后,把历史、检索、system 一并塞进窗口。嘉宾观点(未点名可复现论文):痛点从「装不下」变为「装得下但难 debug、延迟/费用高、长窗推理质量未必优于受控短窗」。代码侧 LLM_MAX_CONTEXT_WINDOW["DEFAULT"] = 30000(letta/constants.py)是缺省回退,不宜直接等同「官方唯一推荐 30k」;ADE 文档 举例将 200k 能力模型 artificially limit 到 16k。
机制:编译管线里有什么#
ContextWindowOverview(源码 schema)统计项包括:core_memory、summary_memory、external_memory_summary(archival + recall 元数据)、system_prompt、functions_definitions、num_messages。Compaction 在过长时 summarizes older messages(默认 sliding_window 等)。嘉宾所称 「context compilation」 在文档中更多体现为 recompile、compiled system prompt、Memory.compile()——工程俚语与官方术语部分重叠(核验:部分验证)。
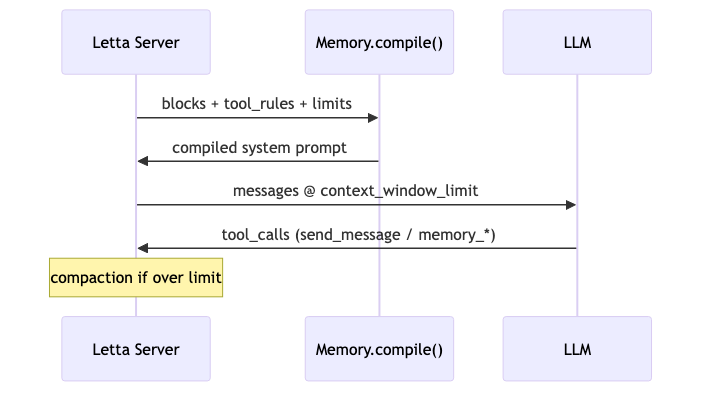
怎么做#
# 文档示例方向:人为压低可用窗(字段以当前 SDK 为准)
client.agents.update(agent_id, context_window_limit=30000)
用 Context window viewer 观察 Core memory blocks / message history / token usage 分项,再调 context_window_limit,而不是先换更大模型。
常见误区#
- 把「未用满 200k」当成浪费——受控预算是可观测性 + 成本 + 质量的折中(嘉宾观点 + 部分代码默认值)。
- 忽略
SYSTEMINSTRUCTIONS @ 5419 CHARS与六类 Lettacore tools 定义占用的固定开销(节目画面 OCR)。
Agentic RAG 与 Archival:何时进上下文#
为什么反对默认 top-k 灌 prompt#
Archival memory:must be queried on-demand via tools,不能像 memory blocks 一样 pin 进窗口。RAG 对比表 写明 Simple RAG 由应用控制检索,Agentic RAG 由 Agent 控制——与 Weaviate 侧 Agentic RAG 叙事 同构,但 Letta 把「检索」实现为 archival_memory_search 等一等公民 tool。
已验证边界:平台默认无「每条用户消息自动 top-k 插入」;开发者仍可在应用层预取后写入 blocks——属集成选择。
机制:分页 + 更新 core 的「Map-Reduce」叙事#
嘉宾观点:对超大数据集,可用 tool 分页扫外部库、把精炼结果写入 core memory,替代一次性 RAG top-k;主持人类比 LangChain Refine——无比 benchmark(类比)。
与 MCP 路径对比(主持人经验):Claude Desktop + Weaviate 经 MCP 写外部记忆;Letta 路径是 LLM 决定写 core / archival,框架编排持久化——非 Letta 官方 MCP 集成说明,仅架构对照。
怎么做#
仅当模型调用:
archival_memory_search(query="...", top_k=5)
才把片段纳入后续轮次上下文;在此之前,向量库里的内容对 LLM 不可见。
常见误区#
- 建了 archival 却从不给 search tool——记忆成为黑洞。
- 把 in-context blocks 与 archival 混用标签——blocks 始终占 token,archival 按次计费检索。
统一原语:一切皆 tool call(含对用户说话)#
为什么要把 send_message 也做成 tool#
嘉宾观点:若聊天走 chat completion、工具走 function calling 两套 API,workflow / multi-agent 会分裂;Letta 将 send_message 列入 BASE_TOOLS(constants.py),用户可见回复经 assistant_message 发出(base.py)。
Message types 另有 reasoning_message / hidden_reasoning_message;MemGPT v2 系统提示 要求 inner monologue … before taking any action——部分验证「先推理再行动」;非所有 API 路径硬编码校验顺序。
机制:tool rules 与 workflow#
tool_rules(tool_rule.py)可约束子工具集合——ADE 中可配(UI 细节未完整核验)。同一原语下可搭「必须先后调用某工具」的 workflow agent(演讲者观点:不必单独的工作流运行时)。
常见误区#
- 以为「tool 步数」等于「对用户回复次数」——
send_message也可能多轮内部 tool 后才一次输出。 - 把 reasoning token 是否进入后续 context 照抄 OpenAI 文档——嘉宾转述会随版本变;Letta 侧用独立 message 类型承载(需读者自行核对当前 OpenAI reasoning 文档)。
Multi-Agent:共享块与消息 tool#
为什么不用「多 Agent 专用运行时」#
嘉宾观点:multi-agent = 共享 memory blocks(update once, visible everywhere)+ inter-agent messaging tools。源码含 send_message_to_agent_and_wait_for_reply、send_message_to_agent_async、send_message_to_agents_matching_tags(multi_agent.py)——无单一名为 broadcast 的 tool(「广播」≈ tag 匹配发送,部分验证)。
常见误区#
- 共享块后不约定写权限——并发更新 persona 可能互相覆盖。
- 期待 ADE 内置 Chatbot Arena 式 pairwise 模型对比——嘉宾确认没有(演讲者观点)。
Tool 执行、沙箱与「Agent 就是普通应用」#
服务端执行 vs 客户端 tool#
Client tools:Server tools 在 Letta server 沙箱执行;Client tools 在客户端执行并经 approval 回传——相对 OpenAI Assistants「只返回 tool call、由客户端执行」的对比为访谈观点(本次未抓取 Assistants 当前文档)。
沙箱选择(源码):有 e2b_api_key 时走 E2B AsyncSandbox,否则 local dir sandbox——与「Cloud 默认 E2B、本地默认不 sandbox」的口述不完全一致(部分验证):本地并非「完全不隔离」,而是 LOCAL 路径。
状态存储:行记录 vs 整包 JSON#
嘉宾观点:不理解 Agent 领域流行「整应用状态一个 JSON blob」;Letta 用关系型持久化 conversation / blocks(Docker compose 含 letta_db pgvector)。竞品是否 JSON 未核验。
常见误区#
- 在 Cloud 跑不可信 Python tool 却未配置 E2B——可能落 LOCAL 路径,隔离级别需读部署配置。
- 把
letta/letta-free当成自研权重——嘉宾称尚无自有模型、端点为 model router(访谈观点;产品名在 OpenAPI 中未完整核验)。
可观测性、评测与「品味」#
开发期透明 vs Langfuse 类平台#
行业做法:上下文黑箱 → 依赖 Langfuse 等还原 prompt。嘉宾观点:若框架像 ADE 一样展示编译后 context window,设计阶段对专用 observability 的绝对依赖下降;上线后仍要 trace/metrics(演讲者观点,无 A/B 数据)。
Numeric eval vs vibe eval#
嘉宾观点:伴侣型、强个性化 agent 难以用 20 万题 benchmark 覆盖;「不是 eval,是 taste」;最佳评测常常是直接用 agent;大规模 numeric eval 易与真实行为脱节。Letta 侧机会:全状态落库便于回放「当时上下文」(evals 在规划,无承诺规模)。
未核实:主持人提及 Berkeley「structuring context window + reasoning」新论文——无 arXiv 条目核对。
对需要回归测试的团队,仍建议维护小规模黄金对话集(主持人提 50–100 条量级):即使认同 vibe eval,也应固定「给定 agent 状态 + 用户输入 → 是否调用某 tool / 块内容是否含关键字」类断言;Letta 全状态落库使这类回放比纯 trace 平台更直接(eval 产品化在规划,非现成功能承诺)。
与向量库协同:Weaviate 在画面中的位置#
节目 ADE 列表出现 weaviate-query-agent(OCR:agent-5b01e7ea-06ee-42b3-9da0-e26f7cc0ad4e),说明典型集成是:Weaviate 存嵌入与对象,Letta agent 经自定义 tool 或 archival 后端查询;并非 Letta 替代向量库。主持人亦对比 MCP 把记忆写入 Weaviate 的路径——差异在谁发起写入(MCP 会话 vs Letta memory tools),不是「要不要向量检索」本身。
若你要落地#
- 先画上下文预算表:system + blocks + tools 定义 + 消息/compaction 各占多少 token;用
context_window_limit人为压窗,再选模型,而不是反过来。 - 把 RAG 改成显式 tool 契约:archival/search 与 blocks 分工写进 agent 说明;集成测试覆盖「未调用 search 则不得引用库内事实」。
- 有状态部署按服务做:PostgreSQL 持久化 + Docker 或 Cloud;一步失败要能从 DB 回放 messages + 编译快照。
- 多 Agent 先共享块、后消息风暴:约定
persona/human写权限;tag 广播前限制匹配范围。 - 沙箱与 tool 路径写进 runbook:核对
e2b_api_key、区分 client vs server tools,不可信代码勿假设「本地=无隔离」。
参考与延伸阅读#
- MemGPT 论文(arXiv 2310.08560)
- Letta 文档首页
- Context hierarchy(blocks / archival / files)
- Memory blocks 与 self-editing
- Archival memory 与 on-demand tools
- Compaction(旧消息摘要)
- Message types(tool_call / reasoning)
- RAG 模式对比 Simple vs Agentic
- Agentic RAG 教程
- Stateful agents 与 DB 持久化
- ADE Context window viewer
- Models 与 context_window_limit
- Docker 部署 Letta Server
- Client tools vs server sandbox
- Letta GitHub(letta-ai/letta)
- E2B 沙箱产品页
- Weaviate:What is Agentic RAG


