
金融研究语料上的企业 RAG:向量库、Agent 与 eval 的工程取舍#
金融机构把分析师笔记、基金/股票研究、社论等半结构化文本做成可查询的 GenAI 能力时,瓶颈往往不在「能不能接一个大模型」,而在 摄入吞吐、检索粒度、权限边界、以及 agent 引入后的延迟与可测性。Morningstar 内部平台 Morningstar Intelligence Engine(MIE) 的公开产品规格几乎查不到;下文把可核对的一手文档与 演讲者观点 分开写,供你在同类场景里做架构对照,而非当作 Morningstar 官方白皮书。
问题空间:API 平台,而不只是聊天窗#
为什么:内部产品团队与外部客户都需要同一套 RAG / agent 能力,但技能栈差异大;若每个应用自建管线,embedding、分块、eval 会重复且不可比。
机制/约束:演讲者将 MIE 描述为 API 驱动、偏低/无代码 的平台:可配置 RAG 管线、GenAI agent、自带工具,并在路线中扩展 text-to-SQL(演讲者观点;Morningstar Developer 门户存在,但未载明 MIE 能力清单)。首条生产语料域为 研究/社论/分析师笔记(演讲者观点),典型链路与 Weaviate 文档中的 RAG 叙述一致:嵌入 → 向量库语义检索 → 上下文送入 LLM。
怎么做(最小示意):
文档事件 → 队列 worker → chunk + embed → Weaviate upsert
用户问题 → filter(entitlement) → hybrid/semantic search → rerank → LLM
常见误区:把「平台」等同于单一 Chat UI;忽略 Deploy 后统一 API 与多租户 eval 的需求(工具市场、eval UI 为 演讲者观点,无公开文档)。
向量库选型:FAISS 验证,Weaviate 扛复制与运维边界#
为什么:FAISS 适合 POC 级稠密检索(“efficient similarity search … of dense vectors”),但 HA、复制、跨 AZ 扩缩若自建,团队时间会从 内容质量 漂移到基础设施(演讲者观点)。
机制/约束:Weaviate Replication 文档写明复制可 “improve availability” 并支持 replicationFactor;这与「用托管/成熟向量库换工程焦点」的叙述同向。演讲者观点:GPT 出现后先 FAISS,后在容器内 数日 试验开源 Weaviate 并进入合作——时间线无公开案例可核。
怎么做:POC 用本地/文件索引;生产前明确 RPO/RTO、只读副本读扩展、升级策略,再决定是否自建 FAISS 集群还是向量库。
常见误区:默认「FAISS 不能上生产」——FAISS README 未否定生产,缺的是 复制与多副本语义;选型是成本曲线,不是道德判断。
摄入:SNS/SQS/Celery 削峰,而非 Kafka 叙事#
为什么:分析师内容经 CMS 等多源涌入,embedding 调用(录制时点为 Azure 上的 text-embedding-ada-002,1536 维、8192 token 上限)在高峰会成为瓶颈。
机制/约束:Amazon SNS 做 topic fan-out,SQS 缓冲,Celery worker 在 K8s 上弹性伸缩——演讲者观点 明确 未采用 Kafka(与「大规模摄入必 Kafka」的默认剧本相反)。组件能力有一手文档;MIE 是否仅此组合 无法核实。
怎么做(示意):
# 伪代码:事件驱动摄入,与访谈栈对齐的方向性示例
sns.publish(TopicArn=DOC_TOPIC, Message=json.dumps({"doc_id": id}))
# SQS → Celery task: fetch → chunk → embed → weaviate batch import
常见误区:为「看起来更大数据」强上 Kafka,却缺少跨团队流处理运维;Python 栈下 队列 + worker 往往足够(演讲者观点)。
分块、合成问句与「小 embed、大 retrieve」#
为什么:页界/固定长度初版块常切断语义;用户问的是 问题,块却是 陈述,向量空间不对齐会降低召回。
机制/约束:
- 演讲者观点:块间重叠、多次 全量 re-ingest、检索后 rerank;CMS pub/sub 处理 PDF/文本/JSON,部分需外部映射。
- 合成问句嵌入:用 LLM 为块生成假设问题再 embed,因 question–question 相似度优于 question–document(演讲者观点,无 Morningstar 论文)。
- 文献侧:Anthropic Contextual Retrieval 用块附上下文再嵌入,宣称与 rerank 组合可降低失败检索(其内部评测,≠ MIE 数字);LlamaIndex Auto Merging Retriever 体现 小块检索、合并父块 的「小索引、大上下文」模式,与嘉宾口述同构,但 「embed small, retrieve big」字面口号未在 LlamaIndex 官方命中。
怎么做:
chunk → LLM(synthetic_questions[]) → embed each → store metadata: parent_doc_id, offsets
query → retrieve top-k synthetic hits → expand to parent span → rerank → prompt
常见误区:把摄入阶段合成问句 直接当 golden eval 或微调集——演讲者观点 称合成题主要用于检索,不默认进入 eval;若未来做合成 eval,需换模型/加噪声防 同源偏差。

生产 RAG 保留 ReAct:用延迟换答案质量#
为什么:单轮 retrieve-augment-generate 在复杂金融问题上易漏工具步骤或误选语料库。
机制/约束:ReAct(Yao et al., 2022)要求 “reasoning traces and task-specific actions in an interleaved manner”,每轮多一次 LLM 调用 → 延迟上升 可预期。演讲者观点:MIE 由无 agent 起步,为质量 在生产保留 ReAct;平台内 RAG 管线本身是 ReAct,而 function calling / programmatic action calling 主要服务 消费 MIE API 的下游——下游的一个 function 可再调平台 ReAct,形成嵌套。
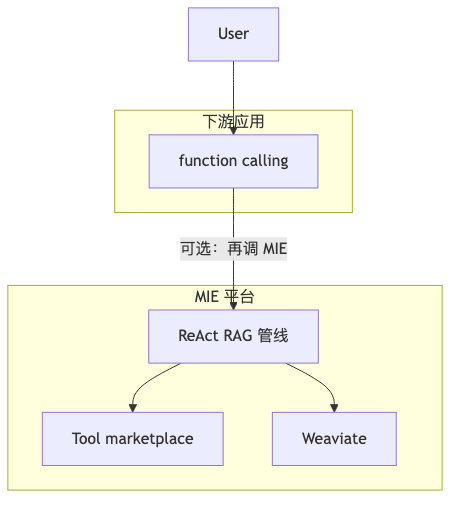
怎么做:为 ReAct 设 max_steps、超时、工具白名单;对延迟敏感路径保留 vanilla RAG 降级开关(访谈未称已实现,属工程建议)。
常见误区:因 benchmark 上 agent 更炫就全量 agent 化;忽视 逐步 eval 成本 随步骤数爆炸(嘉宾对比 LangGraph 式工作流的 StateGraph 可观测性,自身更偏 工具描述 + ReAct 选型,演讲者观点)。
延伸(未上线边界):Microsoft AutoGen 仅 POC,适合 后台多轮 + 缓存 insight;Reflexion 论文在 HumanEval 报 pass@1 提升——与嘉宾口述 SQL「约 80–83%」不同任务、不同指标,不可混用。
工具市场与「多 Agent」:路由优于组织隐喻#
为什么:金融场景工具多(RAG、SQL、自定义 API),需要 discoverability 与隔离,而非给 LLM 编「CEO/市场部」角色剧。
机制/约束:演讲者观点——Tool marketplace 发布容器内运行的自定义 API;ReAct 读 工具描述 + prompt 选工具;Deploy 后统一 API 暴露。上线形态更像 共享 Morningstar RAG tool + 按 agent 附加 SQL 等工具的路由,而非 multi-agent 组织隐喻(演讲者观点)。
常见误区:用 AutoGen 多角色直接扛终端用户请求——嘉宾称 延迟与 eval 难度 使其更适合批处理(演讲者观点)。
Eval:golden Q&A 与 meta-evaluation,而非摄入合成题#
为什么:换模型、temperature 或灌入大批量新文档时,需要可重复对比,否则无法向业务方证明「变好了」。
机制/约束:演讲者观点——内置 golden Q&A;指标含 accuracy、conciseness、groundedness 及 meta-evaluation;非工程师可用 UI 上传 eval。无法核实 MIE 指标公式与是否实现 pass@k。公开 RAG eval 常配合 LLM-as-judge,但 与 Spider/BIRD 等 SQL leaderboard 不是同一套度量。
怎么做:固定 问题集版本 + 检索快照 + 模型版本 三维;变更 embedding 模型时按 Azure 文档 对 ada-002 → text-embedding-3-* 全量重嵌。
常见误区:用摄入合成问句当 eval——易 过拟合检索器 且与真实用户问法分布脱节(演讲者观点)。
text-to-SQL:schema 工程与口述准确率的上限#
为什么:结构化持仓、评级、指标查询若全靠向量检索,成本高且难保证聚合正确。
机制/约束:演讲者观点——早期即有 text-to-SQL POC;在 少量表(<10)且列名自解释 时口述 约 80–83%(无 benchmark 名、无 pass@1/execution accuracy 定义,无法核实)。工程手段:为列提供 rating_id 整数 避免对文本 rating 误 AVG;用 数据库视图 减 join;只读 SQL 角色、LIMIT、聚合尽量下推 SQL;错误时 SQL agent 重试。公开对照仅能用 Spider 2.0 等社区套件说明行业基准存在,不能证实或反驳 80–83%。
怎么做:
-- 只读角色 + 行数上限(示意)
SET ROLE mie_readonly;
SELECT rating_id, AVG(metric) FROM v_fund_ratings GROUP BY 1 LIMIT 100;
常见误区:表一多、列名缩写就期待通用模型「接近可用」;或把 Reflexion 论文 91% pass@1 HumanEval 误读为 SQL 成绩。
权限与合规:源头不 ingest,检索前 filter#
为什么:生成后屏蔽单句无法挽回已泄露的向量;金融数据还有 domicile、entitlement 维度。
机制/约束:演讲者观点——非公开敏感内容 尽量不进入向量库;已入库对象带 metadata,在请求到达 Weaviate/LLM 之前 按 entitlement 收窄或拒绝。库侧能力:Weaviate Filters 支持属性过滤;Weaviate v1.28.0 引入 RBAC Preview(“roles and permissions … Isolation is at the collection level”,preview API 可能变更)——主持人提及,可与业务 entitlement 叠加强度未知。

常见误区:只靠 RAG 后处理 redact;忽视 Python 工具必须沙箱,否则退回 限定 function 集(演讲者观点:SQL 默认可用只读角色,Python 风险更高)。
Guardrails 与模型栈:外购 vs 自建、微调 vs prompt#
为什么:模板化合规(免责声明、禁止投资建议措辞)与输入输出双侧检查,外包服务在金融场景常不够用。
机制/约束:演讲者观点——试过多家 guardrails-as-a-service 后倾向 in-house;平台将支持客户 自带 guardrail(规则/小模型/LLM prompt)。文风上小规模 Llama 微调「response was okay」,短文章 GPT-4o + prompt 已够用(gpt-4o 在 Azure 模型表可查);大规模研报仍靠分析师。演讲者观点。
常见误区:认为金融文风必须微调;或 overnight 自动生成研报可无人值守——嘉宾称仍属 研究产物、需人工审阅,多模态图表风险更高(演讲者观点)。
若你要落地#
- 先画权限与数据分级:敏感未公开材料默认不进向量库;检索链路上 filter 早于 embed 查询,并对照向量库 复制/RBAC 能力做威胁建模。
- 摄入与 eval 解耦:合成问句服务召回;golden Q&A 单独维护,换 embedding 模型时计划 全量重嵌 + eval 重跑。
- Agent 分层:终端路径控制 ReAct 步数;批处理/insights 缓存可考虑 AutoGen 类框架,但别与前台抢同一 eval 矩阵。
- text-to-SQL 先缩 schema:视图 + 只读角色 + LIMIT;口述准确率区间需 自建 benchmark,勿引用无关论文指标。
- 录制时点模型已老化:ada-002 与 GPT-4 系列在 2025+ 部署前查 Azure/OpenAI deprecations,避免维度变化导致静默检索退化。
参考与延伸阅读#
- ReAct: Synergizing Reasoning and Acting in Language Models(arXiv:2210.03629)
- Reflexion: Language Agents with Verbal Reinforcement Learning(arXiv:2303.11366)
- FAISS — Facebook AI Similarity Search
- Weaviate 数据库与 RAG 工作流介绍
- Weaviate — Replication 配置
- Weaviate — Filters(属性过滤)
- Weaviate v1.28.0 Release — RBAC Preview
- Anthropic — Introducing Contextual Retrieval
- LlamaIndex — Auto Merging Retriever
- LangGraph overview — 状态图与工作流
- Microsoft AutoGen — agentic AI 框架
- Azure OpenAI — 模型与嵌入(text-embedding-ada-002、gpt-4o)
- Amazon SNS 与 SQS — AWS 异步消息组件
- Celery — 分布式任务队列入门
- Spider 2.0 — text-to-SQL 社区 benchmark(对照用)


