
多向量检索:在单向量、late interaction 与级联重排之间选型#
RAG 与 Agent 栈里,检索仍是成本与质量的分水岭:单向量 bi-encoder 快但压缩过度;cross-encoder 准但无法全库扫描;多向量 late interaction(以 ColBERT 为代表)试图在两者之间占一条可索引的缝。评测也在分裂——MTEB 上的 dense SOTA 在 BRIGHT 上可能大幅掉队,而 Agent 又把「查询」从关键词扩展成工具 trace 与推理链。
LightOn 的 Amélie Chatelain、Antoine Chaffin 从训练动力学、代码语义 grep、推理密集型基准,谈到 PLAID、Muvera 与 ColBERT-Zero。双方对命名(multi-vector / late interaction / ColBERT 家族)并不纠结,但对「该不该上近似索引」「RAG 是否已被 grep 取代」分歧明显。工程上更像按规模与预算选层,而非押注单一银弹。下文按机制拆解,并标明文献可核对处与演讲者观点。
问题从哪来:压缩、交互与 Agent 查询形态#
为什么:生产 RAG 要同时满足延迟、召回与可解释性。单向量把整段文本压成一个点,词法变体与细粒度对齐在压缩中丢失;cross-encoder 对 query–document 做全交互,只适合短列表重排。Agent 又把查询从关键词拉成长 reasoning trace、工具调用上下文,与经典「短 query + 长文档」假设进一步错位。
机制/约束:信息检索里长期存在 retrieve-then-rerank;多向量方案把「交互」推迟到检索阶段之后,用 MaxSim(对每个 query token 取与文档 token 的最大相似度再聚合)在独立编码的 query/document token 嵌入之间做软匹配。ColBERT 官方实现中,late interaction 即 query 与 document 分别编码后再做细粒度打分(score() 路径为 token 矩阵上的 max 再 sum)。
怎么做(概念):
# MaxSim 核心(与 ColBERT score 一致,示意)
# Q: [q_len, dim], D: [doc_len, dim]
scores = (Q @ D.T).max(dim=1).values.sum()
常见误区:把「多向量」等同于「多路 embedding 字段混搜」;或以为 MaxSim 的计算量级等于「全库 cross-encoder」——实际瓶颈往往在存储每个 token 的向量(演讲者观点:计算约为 query 长度 × 维度的矩阵乘,可接受;索引体积才是痛点)。视频级 token 数若全精度落盘,存储与 IO 会先于算力成为瓶颈(演讲者观点)。

Late interaction 相对 dense:结构换训练,而非单纯更大模型#
为什么:Amélie 将 dense 描述为对语义的有损压缩,late interaction 保留 token 粒度却在学习空间里做软匹配;Antoine 的博士动机则是 bi-encoder 速度 + cross-encoder 表达力——ColBERT 是路径之一,不是终点。
机制/约束:ColBERT-Zero 在公开 Nomic Embed 混合上,用同 backbone 对比 dense 与 multi-vector:BEIR 平均 nDCG@10 = 55.43(<150M 档,模型卡可核对)。演讲者观点:早期用约 2M 样本训练的 late interaction 对比「整网预训练」的 dense 并不公平;在可比数据上,文本侧 late interaction 仍常更强。另一组演讲者观点:维数足够时 dense 理论上可逼近 cross-encoder,但 bi-encoder 训练噪声大;MaxSim 的 max 只强化最佳 token 对齐,动力学更「干净」——Antoine 引用的具体论文未在对话中给出题名,无法独立核实。
怎么做:级联而非单跳——演讲者观点倾向 dense → late interaction → cross-encoder,逐层收窄候选;ColBERT 若只做 reranker,前级 recall 不足会浪费其能力(与两阶段 IR 常识一致)。
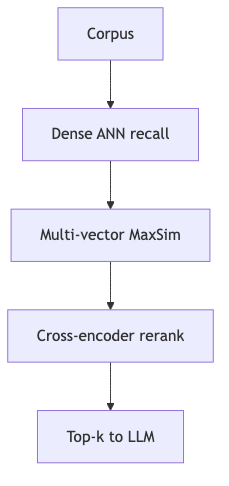

常见误区:用极小 dense 候选池直接接 ColBERT rerank,以为能「补救」召回;或忽视 PLAID 的 centroid pruning——候选来自聚类中心时,中心池本身必须先保证 recall(演讲者观点)。
规模分层:精确 MaxSim、PLAID、Muvera#
为什么:百万级语料无法对每篇文档做全精度 token–token 打分;千级代码库或客服 KB 则可能整机内存内暴力算。
机制/约束(文献侧):
| 组件 | 可核对要点 | 访谈补充 |
|---|---|---|
| ColBERTv2 | 残差压缩,索引约为 vanilla 的 6–10× 缩减 | — |
| PLAID | centroid interaction / pruning;相对 ColBERTv2 最高 7×(GPU)/ 45×(CPU);实验至 140M passages | 嘉宾口语「IVF-PQ」:PLAID 摘要未出现 IVF-PQ,PQ/残差更贴近 ColBERTv2;宜写 centroid + 压缩组合 |
| Muvera | FDE 将多向量压成固定维单向量,内积近似多向量相似度;摘要称 ε-approximation | Antoine:未自行验证证明;效果因模型而异 |
| MS MARCO | BEIR 载明 8.84M passages | 口语「880 万」为约数 |
演讲者观点(Antoine):语料很小(数千文档)时,精确 MaxSim 往往优于 Plaid 近似;小模型上 Plaid 甚至可能差于暴力搜索——「Occam’s razor,别优化不必优化的东西」。Connor 转述 Weaviate 产品方向:Muvera 单向量召回 + 全精度 MaxSim rerank;本次未能从可抓取的 Weaviate 开发者文档核实 Muvera 集成细节,以官方发布为准。
怎么做(选型):
- < ~10⁴ 文档:优先精确 MaxSim 或全量 token 存储;跳过近似索引。
- 10⁶+ 文档:PLAID 类 centroid 候选 + 全精度 MaxSim rerank;LightOn 提供 Fast Plaid(Rust)与 PyLate 的
indexes.PLAID。 - 候选生成:Muvera FDE 可作 Plaid centroid 的替代(论文 BEIR 上平均约 10% recall 提升、90% 更低延迟);是否银弹——演讲者观点:「when it works, it works very well」,跨模型不一致。
常见误区:百万级语料仍上 Plaid;或在 Muvera 近似后直接喂 LLM、跳过全精度 MaxSim rerank。
与向量库集成的边界:Connor 提到 Weaviate 侧探索 Muvera 与 IVF-PQ 类能力——产品事实应以 Weaviate 向量索引文档 当前版本为准;本场为录制时口头说法,且本次未能从可抓取页面核实 Muvera 段落。若你自建栈,逻辑上仍是:近似召回负责广度,MaxSim 负责 late interaction 精度。
代码检索:grep、语义扩展与「RAG 已死」#
为什么:编码 Agent 默认用 grep;多轮关键词试探延迟低但易漏语义相关实现。LightOn 产品线为 ColGrep + LateOn-Code(访谈口语「CodeGrep」),提供类 grep API 的语义检索。
机制/约束(产品文档可核对):LateOn-Code-edge(17M)、LateOn-Code(约 130–149M);预训练数据管线 CoRNStack 2412.01007,微调面向 MTEB Code v1。README 在 Code v1 子任务上对比 17M multi-vector 与更大 dense(如 GTE-ModernBERT)——非泛指所有 Gemini API。演讲者观点:千级文件仓库可 GPU 内精确 MaxSim;「RAG 死了」指 Agent 用 grep + 大上下文即可,但语义 grep 能一次命中需多轮 grep 的代码;人类感知延迟 grep ≈ ColGrep。
常见误区:把访谈中的「70M」当作官方型号(应为 17M edge);用 MTEB 通用榜替代 MTEB Code v1 子任务口径。
推理密集型检索:BRIGHT、ReasonIR 与超长 query#
为什么:BRIGHT 测的是推理密集型相似(如不同题面同一定理),MTEB 榜首类 dense 在 BRIGHT 上可从 59.0 nDCG@10(MTEB) 跌至 18.3 nDCG@10。Agent 把 chain-of-thought、工具 trace 当作 query,进一步拉长查询侧 token。
机制/约束:ReasonIR(Meta ReasonIR-8B)在 BRIGHT 上 29.9 nDCG@10(无 reranker)、36.9 nDCG@10(有 reranker)。演讲者观点:Antoine 用 PyLate 在 ReasonIR 公开数据上微调 130M ModernBERT-ColBERT,称优于至 7B、接近同数据 8B,而同 backbone dense 明显更差——未在 ReasonIR 官方仓库找到 130M 数字,需独立复现;BrowseComp+、API embedding 对比同为演讲者观点。
常见误区:用 MTEB 分数推断 BRIGHT 表现;把 agent trace 当 query 却不换训练分布(ReasonIR 路线是合成推理数据 + 专用微调)。
长文档与长 query:ColBERT 原文强调 document 可离线编码、query 在线交互,适合长文检索形态。演讲者观点:ColBERT 对长文档泛化优于 dense 是「已知事实」,但超长 query(人类问句 vs 拼接 LLM reasoning trace)Antoine 仍部分存疑;在其实验中,reasoning-tuned 模型加 trace 有提升——属实验判断,非 BRIGHT 论文定理。
训练与工具链:ColBERT-Zero、PyLate、prompt#
为什么:多向量预训练贵;产品化需要 Sentence-Transformers 式 API 与大 batch 对比学习。
机制/约束(可核对):ColBERT-Zero 三阶段(无监督对比 → 监督 hard negative → KD);跳过最贵无监督阶段:~40 vs ~408 GH200-hours(约 10×),保留 99.4% 性能(55.12 vs 55.43 nDCG@10)。HF 提供 ColBERT-Zero-noprompts 等变体;演讲者观点:简单 query/document prompt(非 LLM 指令)有提升,机制或未明(类似 query expansion 的猜测)。
PyLate:GradCache 2101.06983 的 CachedContrastiveLoss、gather_across_devices=True,降低多向量对比学习显存门槛。
常见误区:认为「dense + KD」即足够(ColBERT-Zero 论文主张明显欠训);把 prompt 当成 ChatGPT 式 system prompt。
微调产品化(演讲者观点):ColBERT 类模型「不易 collapse」,适合 embedding 微调产品线——与 P01 的 MaxSim 机制叙述一致,但「梯度只更新匹配 token」仍是训练直觉,需对照 PyLate 具体 loss 实现,非 ColBERT 原文定理。
多模态与混合信号#
为什么:图像/视频 token 密度远高于文本段落,单向量压缩损失更大(演讲者观点,信息论式论证,无定量定理)。
机制/约束:文本侧 ColBERT-Zero 已在可比训练下对齐 dense vs multi-vector;多模态公平对比仍受预训练规模失衡影响(演讲者观点)。
混合检索:双方同意保留 BM25 与 dense、ColBERT 的互补失败模式;调参重点是各阶段候选 M 与 rerank 深度。演讲者观点。

rerank 争议(未完全核对):Connor 提及 Databricks《Drowning in Documents》中增大候选 M 会出现 phantom hits——该 URL 2026-05-17 抓取为 404,无法核对正文。Antoine 提出另一叙事:reranker 在分布尾部差,因训练只用 hard negatives;修复需加 tail 样本——是否为同一研究,未核对。
常见误区:去掉 BM25 只留最强语义模型;或为降延迟把 dense 候选 M 压到过小再抱怨 ColBERT rerank 无效。
若你要落地#
- 先量纲再选索引:文档数、平均 token 数、QPS、能否全内存 MaxSim——小库直接精确算,大库再 PLAID / Muvera + 全精度 rerank。
- 固定指标口径:检索写 nDCG@10 / MRR@10;代码用 MTEB Code v1;推理密集型用 BRIGHT,勿与 MTEB 通用榜混读。
- 级联写进 SLA:dense recall → multi-vector MaxSim →(可选)cross-encoder;每一级记录 recall@M,避免 phantom hit 或 tail 崩塌时盲目增大 M。
- Agent 代码路径:保留 grep;语义层试 ColGrep / LateOn-Code,在自有仓库做 A/B(演讲者观点称延迟接近 grep)。
- 训练预算紧:参考 ColBERT-Zero 跳过最贵无监督阶段;用 PyLate + GradCache 复现,公开数据从 Nomic Embed 混合起步。
参考与延伸阅读#
- ColBERT:高效检索的 late interaction
- ColBERTv2:残差压缩与去噪监督
- PLAID:面向性能的 late interaction 驱动
- Muvera:固定维编码的多向量检索
- BRIGHT:推理密集型检索基准
- ReasonIR:Meta 推理检索器与合成数据
- ColBERT-Zero:多向量预训练配方与 BEIR 结果
- ColBERT-Zero 模型卡与训练成本说明
- Nomic Embed:公开训练数据混合
- GradCache:大 batch 对比学习
- PyLate:ColBERT 训练与检索库
- Fast Plaid:Rust 多向量索引引擎
- ColGrep 与 LateOn-Code 发布说明
- MTEB Leaderboard
- Weaviate 向量索引概念文档


