
多向量检索的索引悖论:MUVERA 如何用单向量 ANN 逼近 Chamfer#
ColBERT、ColPali 一类模型把文档表示成 token 级向量集,查询时用 late interaction(对每个 query token 在 document token 上取最大相似度再聚合,业界多称 MaxSim,论文常写 Chamfer)换取比单向量 bi-encoder 更细的语义对齐。代价也直接:索引条数从「每文档一条」膨胀到「每文档数百条」,查询侧还要做矩阵式交互。Google Research 的 MUVERA(Multi-vector Retrieval via Fixed Dimensional Encoding)提出 FDE(fixed dimensional encoding):用确定性、非学习的空间划分把多向量集压成 一条 高维单向量,在 HNSW / MIPS 上 一次 近似最近邻,再对 top-K 做真实 Chamfer 重排;Weaviate v1.31 已集成该编码路径。
下文是面向有经验工程师的独立技术综合:把 可核对论文/文档 与 访谈观点 分开,不把 BEIR 上的 nDCG 与论文里的 Recall@N 混读,也不暗示「单向量启发式」与 MUVERA 在所有数据集上已分出绝对胜负。

问题空间:三种检索范式与一条被忽视的相似度#
为什么 late interaction 会回到「索引条数」#
RAG 与 Agent 的检索层通常在三档之间取舍(演讲者观点,与 ColBERT 社区叙述一致):
| 范式 | 文档表示 | 查询成本 | 典型瓶颈 |
|---|---|---|---|
| Cross-encoder | 无 query 无关的独立 doc 向量 | 全对全 attention | 无法规模化 ANN |
| Single-vector dual encoder | 一条 embedding | 一次 ANN | 丢失 token 级交互 |
| Multi-vector | 固定 doc token 向量集 | 查询时 late interaction | 存储 + 多次检索/重排 |
MUVERA 论文 §1.1 将多向量相似度标准写为
[ \textsc{Chamfer}(Q,P)=\sum_{q\in Q}\max_{p\in P}\langle q,p\rangle ]
并说明其与 MaxSim 同义,distance 变体亦称 relaxed earth mover distance。Rajesh Jayaram(MUVERA 一作)在访谈中把多向量相似度与 Earthmover / 最优传输 类比,差别在于去掉 token 一对一匹配约束(演讲者观点;形式化同构未在播客中给出定理编号)。
机制与约束#
- ColBERTv2 实验设定:d=128,|Q|=32 个 query token(MUVERA §3)。
- Chamfer 对 document 侧重复 token 不敏感(max 对 P 中重复项),对 query 侧重复敏感——形式化上成立;Rajesh 将其类比集合包含的非对称性(演讲者观点)。
- 带 schema 约束(标题不得匹配正文等)的检索,Chamfer 不适用,需改损失或掩码(演讲者观点;ColBERT/MUVERA 正文未展开)。
怎么做(最小示例)#
概念上:索引阶段保存 P 的全部 token 向量;查询阶段算 Q,再算 Chamfer 或调用引擎的 MaxSim 算子(Weaviate 教程)。
常见误区#
- 默认「平均后再 max」与论文 求和 等价——实现可能除以 |Q|,不能默认与论文符号一致。
- 把 Chamfer 当作任意结构化字段检索的默认度量。

单向量启发式:工程上可行、理论上无保证#
为什么 ColBERTv2 / PLAID 仍把 token 摊进 ANN#
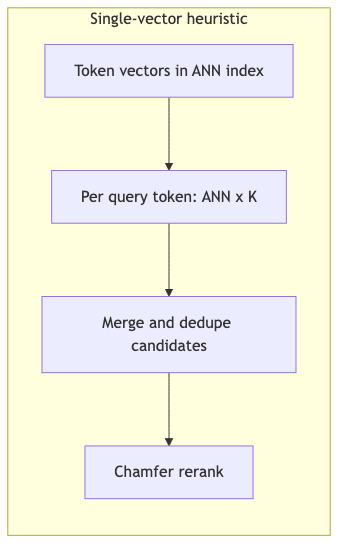
在 MUVERA 之前,社区主流 single-vector heuristic(论文用语):把每个 query/document token embedding 当作独立向量 编入 MIPS/ANN 索引;对每个 query token 检索,合并候选后用 Chamfer 重排。PLAID 在此基础上加 centroid interaction、剪枝等,相对 vanilla ColBERTv2 报告显著延迟下降(论文数据,非播客 QPS 表)。
访谈中的口述流程(与论文相容,K 因实现而异):约 32 次 ANN → 至多 32×K 候选 → 去重 → MaxSim 重排。Roberto Esposito(Weaviate Applied Research)强调候选规模与重排成本。
机制与失效模式#
MUVERA 明确指出:该启发式 可能找不到真实 Chamfer 近邻,且需对每个 query embedding 查询更大的索引(引言)。
演讲者观点 的反例:某文档仅在 一个 query token 上极高相似、其余 token 不对齐,仍可能被召回;全局 80% 对齐的文档反而输给「一词完全匹配」的文档——与「整体查询语义」的直觉相悖。论文从理论上强调 SV 代理 无 ε-近似保证,但未用播客式反例编号。
怎么做#
若已部署 PLAID/ColBERTv2 引擎,短期不必拆掉;评估时应记录 recall@K(Chamfer 真值) 与 延迟,而非只盯端到端 nDCG。
常见误区#
- 把 PLAID 的 centroid 剪枝等同于「裸 token 摊平 32 次 ANN」——实现细节以 PLAID 原文 为准。
- 认为「重排总能纠正召回错误」——重排只能重排 已进候选集 的文档。
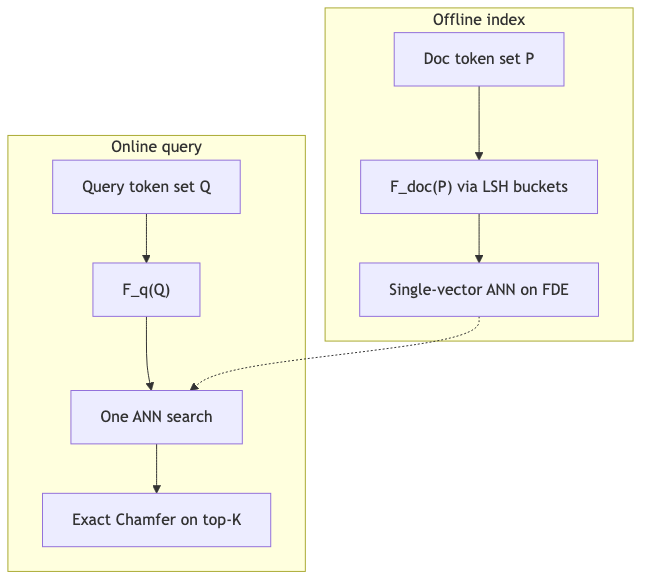
MUVERA / FDE:一次 ANN + 可证明代理#
为什么「回到单向量」不是另训 bi-encoder#
MUVERA 的核心是 非对称 确定性编码 (\mathbf{F}{\text{q}}(Q))、\mathbf{F}{\text{doc}}(P)),使内积 ε-近似 Chamfer(Theorem 2.1 / 2.2,§2)。这与「单独训练一个单向量模型 + ColBERT 重排」不同:后者 无 单向量分数与多向量分数之间的保证(访谈观点,与论文「首个有证明的单向量 Chamfer 代理」一致)。
离线:对文档(及查询)算 FDE → 单次 MIPS/ANN(可用现成求解器;产品侧多为 HNSW)→ 对 top 候选用 真实 Chamfer 重排。Roberto 将候选从「32×K」量级缩到「K」量级(方向一致;严格 K 仍取决于 over-retrieve 配置)。
论文相对 PLAID 的摘要级结论(BEIR 子集实验,非全库普适):平均 recall 高约 10%、延迟低约 90%;达到相同 recall 时 FDE 可比 SV heuristic 少检索约 2–5× 候选(摘要)。
机制:不能查询前拼接 token#
MaxSim 的匹配是 查询依赖 的:在查询到达前,document 侧「该与哪个 query token 对齐」未知(演讲者观点 + 算法必要性)。简单拼接 token 向量不能构成 FDE;穷举排列在 |Q|=32 时不可行。
怎么做(参数心智模型)#
Weaviate 文档给出编码维公式(已核实):
[ \text{dimension} = \texttt{repetitions} \times 2^{\texttt{ksim}} \times \texttt{dprojections} ]
示例 ksim: 4, dprojections: 16, repetitions: 20 → 5120 维。论文实验 d_FDE ∈ {2460, 5120, 10240};口述「5k–10k」宜理解为区间而非单点。配置入口见 Multi-vector encodings。
常见误区#
- 把 FDE 内积分数当作最终排序分——生产仍应 Chamfer 重排 top-K。
- 假设论文声称生产环境 K=1 足够——那是 FDE 理想极限的 访谈推论,论文讨论的是 recall–latency Pareto。

FDE 构造:分桶、非对称聚合与空桶#
为什么用 LSH 而不是「32 个 k-means 中心」#
空间划分 (\bm{\varphi}) 默认 SimHash(LSH);亦可用 k-means(§2)。对每个桶 (k):
- query 侧:桶内 token 向量 求和;
- document 侧:桶内 token 向量 取平均(避免 doc 重复 token 抬高分数;Rajesh 称对 average 或任取桶内一点证明均成立)。
fill_empty_clusters:仅 document FDE;query 侧 never for queries(论文原文)。若在 query 侧填充空桶,会人为抬高无对应 query token 的桶分数(访谈解释与算法一致)。
可 多次独立 SimHash 重复 后拼接降方差。论文对照:k-means 替代 SimHash 在 Pareto 上 通常无收益且常更差,且丧失 data-oblivious 性质。
Rajesh 的 演讲者观点:分区数宜与 query token 数同量级(约 32–64);在千万~亿级 token 上,极少中心的 k-means 欠拟合;LSH 的「对所有点有保证」在此 编码阶段 优于欠拟合聚类。这与「LSH 在一般 ANN benchmark 上不如 HNSW」 不矛盾——LSH 用于 桶划分,HNSW 用于 FDE 的 ANN(访谈 + 论文分工)。
怎么做#
调参时优先扫 ksim(桶数 (2^{ksim}))、repetitions、dprojections;Weaviate 默认示例 ksim: 4 → 16 桶,非 论文强制 32–64。
常见误区#
- 在 子空间 PQ 上破坏同桶语义——Roberto 警告在空间划分上做 PQ 式切分可能破坏保证(工程警告,未 在论文中逐条定理化)。
- 把 doc 侧平均简单等同于重排阶段的 ball carving——后者是另一阶段的 token 合并(见下节)。
维度、PQ 与重排:膨胀之后如何仍省内存#
为什么 FDE 维数暴涨仍可能更省#
索引 条数 从「每 doc 上百条 token 向量」变为 1 条 FDE。ColBERTv2 上平均每 doc 约 10,087 floats(≈ token×128,§3)。FDE 可达 10240 维,再经 product quantization 约 32× 压缩(例:10240 维 → 1280 bytes,摘要)。访谈称 PQ 为论文与产品路径的关键之一;Weaviate v1.31 可将 MUVERA 与 PQ/BQ/RQ/SQ 等叠加(compression 文档)。
FDE 越大 → Recall@N 越高 → 可减小 retrieval K;FDE 越小则需更大 K 与更重排(论文 Pareto + 访谈 trade-off)。
重排加速:论文 ball carving vs 播客数字#
附录 ball carving(§C.3):重排前对 query token 聚类,MS MARCO 上 query embedding 数减少约 5.4×(τ=0.7 等)。播客口述 「4× 剪枝、矩阵乘 16×」 —— 未在 MUVERA 原文找到字面表述;写作时应标为 访谈观点 或引用 ball carving 论文数据。
Weaviate v1.31 实验中 PQ 与 scalar quantization 均显著提升 QPS(产品实验/访谈);官方未给出 与播客对等的绝对 QPS 对照表。
常见误区#
- 把 Recall@N(FDE 检索) 与 nDCG@10(BEIR 端到端) 当作同一指标。
- float32→1bit 标量量化理论约 32× 上限,便认为一定优于 PQ——取决于实现与 recall 损失,需自测。

评测与产品边界:BEIR、CRISP 与不可比的 SOTA#
为什么多向量不宜直接「打榜」单向量 SOTA#
MUVERA 实验使用 BEIR 6 个子集(含 MS MARCO、HotpotQA、NQ、Quora、SciDocs、ArguAna)。Rajesh 的 方法论观点:应在同一 IR 数据上比,但分数 只应与多向量模型互比;不宜宣称击败多年 hill-climb 的单向量 SOTA。长查询、复杂文档需要 新 benchmark(访谈;MTEB 主榜以单向量任务为主,未找到 官方等价 multi-vector 榜)。
CRISP(Clustering Multi-Vector Representations for Denoising and Pruning,共同作者含 Rajesh Jayaram)在 BEIR 上报告向量削减与质量权衡;摘要示例 ArguAna 上 C4×8 相对未剪枝 +5.5% 等。「播客推动 CRISP 发布」 —— 无法核验(论文提交日期 2025-05-16)。
工程集成(已核实)#
| 能力 | 版本 |
|---|---|
| Multi-vector + late interaction | v1.29+ |
| Multi-vector GA | v1.30(博客) |
| MUVERA 编码 | v1.31 |
教程模型示例:ColBERT、ColPali、ColQwen;配置 Encoding.muvera(...) 见 官方文档。
常见误区#
- 在 ArguAna 等敏感子集上不调 剪枝/聚类(CRISP 方向)便断定「多向量不行」。
- 混读 v1.29 多向量与 v1.31 MUVERA 要求。

学科文化:NN 理论与向量数据库为何长期各说各话#
Rajesh 提出:近邻搜索理论(sketching、LSH、ε-近似)与 向量数据库实践(HNSW、IVF、DiskANN、产品量化)二十年来交流有限(演讲者观点)。MUVERA 可视为一次把 可证明代理 嵌进 MIPS 索引链路的尝试;是否成为主流,取决于多向量模型在 RAG/Agent 中的占比、以及 FDE+PQ 在你数据上的 Pareto 是否优于 PLAID 工程栈。
未统一结论:PLAID 仍是强基线;MUVERA 在论文子集上报告更高 recall 与更低延迟,但是否覆盖你的语料、schema 约束与 SLO,只能自测。高维 FDE 是否可被 学习压缩表示 直接替代,Rajesh 承认是开放问题(访谈)。
若你要落地#
- 先定度量:确认业务是否真需要 Chamfer/MaxSim;有字段级匹配约束时,先改损失或掩码,再选索引结构。
- 建立双指标:FDE 阶段的 Recall@N(对 Chamfer 真近邻) 与端到端 nDCG/MRR 分开报告;勿与单向量 MTEB 榜直接比。
- 对比两条召回链:在同一 ColBERTv2 索引上跑 SV heuristic/PLAID 与 MUVERA FDE(Weaviate ≥1.31 或论文参考实现),扫
d_FDE与 retrieval K 的 Pareto。 - 编码参数:从论文附近的 5120/10240 与 Weaviate 公式出发扫
ksim、repetitions;启用 PQ 时单独测 recall 损失;空桶填充仅 doc 侧。 - 重排预算:在 top-K Chamfer 上叠加 ball carving(论文 ~5.4× query token 削减)而非盲信播客 4×/16×;对 ArguAna 类任务评估 CRISP 式剪枝 是否必要。
参考与延伸阅读#
- MUVERA 论文(arXiv:2405.19504)
- MUVERA HTML 全文(§1 Chamfer / §2 FDE)
- ColBERT(SIGIR'20)
- ColBERT 官方 README(MaxSim 图示)
- ColBERTv2
- PLAID:Performance-optimized Late Interaction Driver
- BEIR 基准论文
- BEIR GitHub 套件
- CRISP:多向量聚类剪枝与去噪
- Weaviate 教程:Multi-vector embeddings
- Weaviate:Multi-vector encodings / MUVERA 配置
- Weaviate 1.31 发布说明(MUVERA)
- Weaviate GitHub Release v1.31.0
- ColPali:视觉文档 late interaction
- RAG 原始论文(检索增强生成框架)


