
半结构化检索上的 Agent:STaRK 基准与 AvaTaR 优化#
当知识库同时承载自由文本与显式关系(商品属性、论文引用图、药物–蛋白–疾病边)时,「接好向量库 + function calling」并不自动等于会检索。Stanford 博士生 Shirley Wu 在 STaRK 与 AvaTaR 两条工作线上,把问题拆成可测的 benchmark 与可优化的工具策略;下文综合其公开论文与一线工程讨论,不强行收束为单一结论——访谈主张与已发表表格存在张力处会标明。
问题空间:为何需要「检索 Agent」专用基准#
为什么:企业知识库越来越像半结构化知识库(SKB)——节点带多段文本、多属性,边表达品牌、适应症、合著关系。传统做法把 textual retrieval(BM25 / dense VSS)与 relational retrieval(text-to-SQL、图遍历)分开评测,却回避了真实查询的并集需求:「Nike + cute design」既要结构过滤又要语义匹配(演讲者观点)。
机制/约束:STaRK 在三个 SKB 上统一检索任务:STaRK-Amazon(商品)、STaRK-MAG(学术图谱子图)、STaRK-Prime(基于 PrimeKG 的生物医学图)。指标沿用检索文献口径:Hit@k(正确答案是否出现在 top-k)、Recall@k(top-k 覆盖的相关项比例;合成集常用 k=20)、MRR(首个相关结果的平均倒数排名)——见 STaRK 论文 实验节。
怎么做:用官方 snap-stanford/stark 的 eval.py 在同一套查询上对比 BM25、ada-002 单向量 VSS、图神经网络基线与 agent 管线,避免各域各写一套脚本。
常见误区:把 STaRK 当成「又一个 RAG 问答集」。它是 entity-level retrieval(返回节点/商品/论文 ID),中间是否调用 SQL 或向量搜索由系统决定,最终仍按 Hit@1 / Recall@20 打分。
flowchart LR
Q[Query] --> A{Agent policy}
A --> T[Textual tools<br/>VSS / BM25]
A --> R[Relational tools<br/>filter / traverse]
T --> SKB[(Semi-structured KB)]
R --> SKB
SKB --> M[Hit@k / Recall@k / MRR]
Agent 的操作性定义与检索分工#
为什么:「Agent」一词被泛化到单次 completion。若优化对象模糊,prompt 搜索与架构搜索都无法归因。
机制/约束(演讲者观点):Agent ≈ LLM + 多步工具使用 + 对环境有可验证的改动;检索 agent 特指在 SKB 上选择 textual tool(语义搜索)与 relational tool(属性过滤、邻域扩展)的序列。与之对照的是手工 workflow(固定 DAG)与 compound multi-agent(多角色、多中间产物);后者在 STaRK 式端到端指标下,中间步失败可能被最终答案掩盖(演讲者观点)。
怎么做:为每个 tool 写清输入 schema 与失败语义——访谈中 zero-shot 常混淆「向量相似」与「metadata filter」,类似 Weaviate 上 nearText 与 where 的分工(主持人实践,非 STaRK 论文要求)。
常见误区:用「是否调用了 API」判定 agent 能力。关键在 action sequence 是否随查询模式变化,而非调用次数。
多向量检索:Recall 上去,Top-1 仍可能不够#
为什么:单段文本 embedding 会稀释标题、品牌、规格等不同粒度的信号;对节点多字段分别嵌入再聚合(multi-vector)是自然基线。
机制/约束:AvaTaR 论文 Table 2 对比 ada-002 与 multi-ada-002(多段文本分别嵌入后聚合):Amazon 上 Recall@20 从 53.29% 升至 55.12%,Hit@1 从 39.16% 升至 40.07%;Prime 上 Recall@20 +2.05pp、Hit@1 +2.47pp。但 MAG 子集 Hit@1 反而从 29.08% 降至 25.92%,说明「多向量单调改进」不成立。相对 AvaTaR 优化后 Amazon Hit@1 49.87%,multi-ada-002 的 40.07% 仍差约 10 个百分点——与「召回改善、首位仍不够」的表述方向一致(演讲者观点;数值来自论文,非访谈口述)。
怎么做:把 multi-vector 当作 召回层,上层仍需要查询分解(divide-and-conquer)与关系过滤;勿用 Recall@20 单独证明产品可用。
常见误区:增加 embedding 字段数 = 解决 relational 约束。结构条件(品牌、适应症)往往要先 定位锚点节点 再扩邻域。
工具齐全的 Agent 何时输给 Dense Retriever#
为什么:若 agent 劣于单向量检索,则 prompt 优化比堆工具更重要——这是 AvaTaR 的动机之一。
机制/约束:
- 演讲者观点(一手经历):团队在 STaRK 上实现的 zero-shot tool agent(含 prompt engineering / ICL)曾 明显差于 simple dense retriever(~29:01 段)。
- 论文部分冲突:同文 Table 2 中 ReAct(Claude 3 Opus)在 Amazon / MAG / Prime 的 Hit@1 均不低于 ada-002 VSS(例如 Amazon 42.14 vs 39.16)。因此「agent 一定输给 dense」不能从已发表 ReAct 行直接推出;更可能指向 早期自研 agent(工具描述、函数边界、未优化策略)与论文基线配置差异。
- 定性支持:AvaTaR 引言与 Figure 2 指出手工 mega-prompt 的 ReAct 在商品查询上易产生 trivial / misleading 答案,且难跳出 LLM 先验工具模式(论文)。
怎么做:先用 最强简单基线(单向量 + 必要 metadata filter)锁定下限,再引入工具链;优化阶段用验证集上的 Recall@20 划分正负查询批(论文默认 ℓ=h=0.5,batch b=20)。
常见误区:把 Table 2 的 ReAct 与访谈中的「失败 agent」混为同一实现。写作与复现时需写明 工具清单、模型版本、是否经过 AvaTaR 优化。
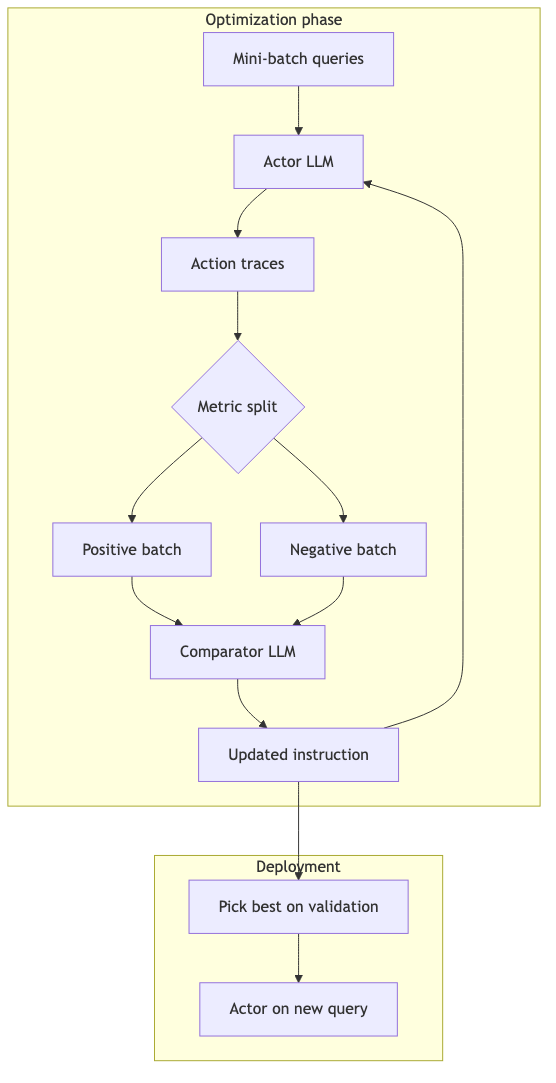
AvaTaR:Contrastive Prompt Optimization#
为什么:标注轨迹太少时,SFT / RL 不现实;需要利用 一批查询上同一 action sequence 的成功与失败 归纳模式(如复杂查询要分解、何时走 relational tool)。
机制/约束(AvaTaR 论文 §4,已验证):
- Actor LLM 对查询执行工具动作序列;
- 按 Recall@20(检索)或 Accuracy(部分 QA)将 mini-batch 分为 positive / negative;
- Comparator LLM 对两批做 contrastive reasoning,生成 holistic instruction,更新 actor 的策略与 tool description;
- 优化若干 epoch 后,取 验证集最优 action sequence / instruction 部署。
与 OPRO 的异同(演讲者观点;AvaTaR 正文未点名 OPRO):二者都可维护多份候选并在验证集选优;OPRO 把历史解及分数写入 meta-prompt 让 LLM 生成新 prompt 文本,而 AvaTaR 的进化轴是 跨查询模式的 contrastive 批,优化对象是 可复用的 action / instruction,而非纯自然语言 prompt 种群。注意:要点文档曾误引 OPRO 为 arXiv:2306.03427,正确编号为 2309.03409。
怎么做(概念最小闭环):
# 伪代码:单轮优化步
batch = sample_queries(train, b=20)
for q in batch:
trace[q] = actor.run(q, instruction=current_instr)
pos = [q for q in batch if metric(trace[q]) >= threshold_high]
neg = [q for q in batch if metric(trace[q]) < threshold_low]
current_instr = comparator.contrast(pos, neg, traces={**pos, **neg})
best_instr = select_best_on_validation(candidates)
消融 AVATAR-C(去掉 comparator)在 STaRK 上 Hit@1 明显下降(论文 Takeaway 2)——comparator 不是装饰模块。
图遍历、GraphRAG 与一跳消息传递#
为什么:对「Nike 鞋」查询,若只做 query–node 余弦相似度,可能命中无关 Nike 条目;先 锚定品牌节点 再沿边取邻域,精度通常更好(演讲者观点)。这与 GraphRAG「向量找种子 → 扩子图作 context」同构,可视为图上的 chain-of-thought(演讲者观点)。
机制/约束:一层 message passing 只聚合 直接邻居;k 层对应 k-hop。演讲者用「鞋节点—价格邻居—图像节点」说明 hop=1 时价格属性可更新鞋节点表示,但不会传到无直连边的图像节点——该例为教学类比,未在 STaRK / AvaTaR 正文出现;机制本身与 PyG 文档一致。
怎么做:把 relational tool 实现为 受限遍历(边类型、深度、节点类型过滤),而非让 LLM 自由生成 Cypher;agent 负责选「先 filter 后 expand」还是「先 semantic 后 filter」。
常见误区:把 LLM 当 embedding 模型用;在需要分解的查询上,应优先消耗推理 token 做 查询拆分,而非加长单向量。
Multi-agent、Workflow 与 Compound 系统的优化边界#
为什么:同一任务可有上百种 agent 分解(researcher → writer 等),结构效应与随机性纠缠(演讲者观点)。Compound AI 中间产物多,端到端指标难以归因到单个 agent。
机制/约束(演讲者观点):
- 反对 角色扮演式互聊;倾向 任务专精 agent(不同 prompt / 工具集)协作。
- 主持人路径:手工 workflow + DSPy / MIPRO 分步优化 + AvaTaR 精调 tool description——与「单 agent 自改 prompt」路线并存,无统一最优(访谈讨论)。
- 评测:仅看 input–output 会漏掉中间步错误;需对关键中间态加 metric 或 LLM-as-judge(AvaTaR 在部分 QA 子任务用 judge,见论文 §4)。
怎么做:compound 系统里 选择性优化 瓶颈 agent(通常是检索 / 规划),其余固定;避免同时搜索架构与 prompt。
常见误区:agent 数量 ∝ 性能。访谈强调 兼容性:部分 agent 组合互斥,搜索空间需约束。
记忆库、kNN 轨迹与 contrastive 批#
为什么:上下文变长是否淘汰 memory bank 尚无定论;演讲者仍保留「存成功 trajectory 的数据库式 memory」路线,因全塞进 context 成本高(演讲者观点)。
机制/约束:
- 演讲者观点:团队曾用 experience library,在测试时检索最相似轨迹做 few-shot,效果差——易学到
if Nike in query类实例规则(过拟合式硬编码)。 - 论文对照:AvaTaR 正文无 “experience library” 专名;优化阶段有 memory bank 存历史最优 instruction/actions(防 actor 重复错误),不是 测试时 kNN 轨迹检索。基线 ExpeL 更接近「推理时检索成功/失败轨迹写入 context」,在 STaRK-MAG 上与 ReAct 相近、远低于 AvaTaR(论文 Takeaway 1 附近)——支持「检索相似轨迹弱于 contrastive 批优化」,但未逐字复述 Nike 案例。
怎么做:优先让 comparator 从 跨查询正负批 归纳模式;若用 few-shot,检索 workflow 模板 通常比检索完整轨迹更稳(演讲者观点),但仍需验证域外泛化。
常见误区:把优化阶段 memory bank 与测试时 RAG 式轨迹库等同。
未收敛之处(刻意保留张力)#
| 主题 | 较一致 | 存在分歧或未核边界 |
|---|---|---|
| STaRK 三域统一评测 | 论文 + 代码 | 多模态延伸为方向性表述 |
| Multi-vector | Amazon/Prime Recall↑ | MAG Hit@1 反例 |
| Zero-shot agent vs dense | 引言 / 访谈定性 | Table 2 ReAct ≥ ada-002 |
| AvaTaR 机制 | 论文 Figure 1 / Table 2 | 各域提升幅度需查附录 |
| OPRO 对照 | 访谈 | AvaTaR 正文未点名 OPRO |
| GNN 鞋/图示例 | 机制可对照 PyG | 仅访谈类比 |
| Experience library | 访谈负向 ablation | 论文以 ExpeL + memory bank 间接对应 |
若你要落地#
- 先钉死基线:在同一 SKB 上跑通
ada-002VSS + 必要属性过滤,记录 Hit@1 / Recall@20,再叠工具 agent;避免无下限地调 prompt。 - 拆分 textual / relational 工具契约:向量搜索与 metadata filter 的输入输出、失败码写进 tool schema,减少 zero-shot 混用(工程上可参考向量库的 hybrid 查询文档)。
- 用 contrastive 批优化「策略」而非堆 few-shot 轨迹:小标注集下,用验证集 Recall@20 划分正负批,迭代 instruction;慎用过拟合的测试时 kNN 轨迹库。
- Compound 系统只优化检索/规划瓶颈:中间步加可观测 metric,避免端到端「看起来还行」掩盖检索失败。
- 公开复现:克隆 snap-stanford/stark 与 AvaTaR 附录配置,在 STaRK-Amazon 子集上复现 Table 2 一行再扩展到你自己的 SKB。
参考与延伸阅读#
- STaRK 论文(arXiv:2404.13207) — 半结构化检索基准定义与三域任务
- STaRK 项目站 — 数据集与 leaderboard 入口
- STaRK GitHub(snap-stanford/stark) — 评测脚本与数据键
amazon/mag/prime - STaRK Hugging Face 数据集 — 直接加载实验
- AvaTaR 论文(arXiv:2406.11200) — contrastive prompt optimization 与 Table 2 基线
- OPRO 论文(arXiv:2309.03409) — 进化式 prompt 优化对照
- OPRO 代码(google-deepmind/opro) — 官方实现参考
- PrimeKG 仓库 — STaRK-Prime 生物医学图源
- PrimeKG 项目页(Harvard Zitnik Lab) — 整合数据源说明
- PyTorch Geometric — Message Passing 教程 — k-hop 与层数约束
- Weaviate 开发者文档 — 向量 + 过滤混合检索(播客生态语境)
- DSPy 项目 — 声明式 prompt / 程序优化(主持人实践路径)
- Gorilla(Berkeley 工具调用 LLM) — 工具学习早期 benchmark 参照
- Dense Passage Retrieval(DPR, arXiv:2004.04906) — dense retriever 方法论背景
- ReAct 论文(arXiv:2210.03629) — AvaTaR Table 2 中的 agent 基线来源


