
Agent 监督栈:从静态评测到轨迹级可观测性#
多 Agent 系统把工程重心从「单次生成质量」推向「长轨迹是否可信」。固定 benchmark 仍有用,但开放任务里路径空间爆炸,让人工逐条读 trace 的成本与模型能力增长不同步。Patronus AI 联合创始人 Anand Kannappan 在围绕 Percival 的公开叙事里,把问题框成:评估(evaluation)→ 可观测性(observability)→ 监督(oversight) 的递进;本文按机制拆解该链条,并标明文献、官方文档与「演讲者观点」的边界——不假装各方已达成单一结论。
问题空间:四段技术栈与三类张力#
常见演进路径(演讲者观点)可概括为:孤立 LLM → 含 RAG 的复合系统 → 单 Agent 工具循环 → 多 Agent 互调。第三段之后,访谈里反复出现三类结构性张力,其中定量说法(如「数千万 token 级上下文」)未给出可复现 benchmark,宜作方向判断而非规模事实:
| 张力 | 工程后果 |
|---|---|
| 上下文爆炸 | 长轨迹超出单次窗口,动作顺序依赖强 |
| 领域自适应 | 通用 rubric 难以覆盖垂直合规 |
| 多 Agent 编排 | 静态用例难以枚举联合失败模式 |

静态评估并未作废,但边界在变窄#
为什么#
订票、固定写博客、schema 校验等步骤少、目标清晰的流程,仍适合固定数据集与 outcome 检查(演讲者观点)。行业实践也长期用 HaluBench 一类基准做回归。
机制与约束#
开放营销类 Agent、路径不可预知的自治体,预设用例覆盖率会快速衰减;此时「过程奖励」若要用于优化,往往需运行时评判每一步是否合规,而非仅靠离线标签(演讲者观点)。这与 LMUnit 强调的 per-instance 自然语言单元测试在理念上相邻:准则可在运行时生成,但 Percival 与 LMUnit 无公开实现对比。
怎么做(最小示例)#
对固定 RAG 流水线,保留三元组 (context, question, answer) 的回归集,并用专用 judge 做二元幻觉检测:
# 概念示意:Lynx 类 judge 输出 grounded / not grounded
verdict = lynx_judge(context=ctx, answer=ans) # 见 HaluBench 协议
assert verdict.label in {"grounded", "hallucination"}
常见误区#
- 因 Agent 流行而废弃全部静态集;高确定性子任务仍应保留快照测试。
- 把访谈中的「静态 eval 不可能」推广到所有系统——该说法针对高开放度多 Agent,无法核实为普适定律。
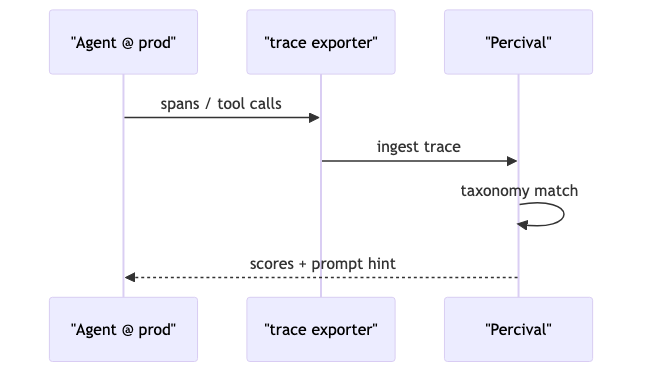
生产 trace 优先:Percival 与失败分类学#
为什么#
Patronus 调试文档 将 Percival 定位为分析 agentic traces、检测错误并给出优化建议;首版叙事强调解读已运行 trace(开发/测试/生产均可),而非替代整条静态 eval 流水线(演讲者观点)。客户轶事称:人工读懂少量 trace 可耗「数小时」,再抽一条变成 eval 案例约「+1 小时/trace」——无样本量与统计协议,仅作成本量级参考。
机制与约束#
公开 Error Taxonomy 写明 20+ failure modes,分 Reasoning / System Execution / Planning and Coordination 等大类;支持 Custom error taxonomies 扩展。访谈曾称 60 类——与官网 20+ 不一致,可能含子类型或内测枚举;截至公开文档,无完整 60 项列表。
演示个案(不可当作产品平均性能)对单次运行打出 1–5 分多维分数:文档明确 security、reliability 及 other dimensions;UI 中可见 Plan Optimality、Instruction Adherence 等扩展维。
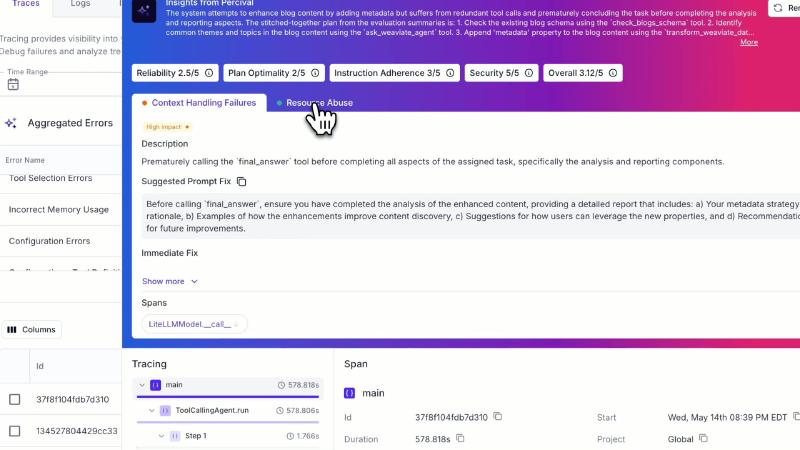
OCR 与文档一致片段包括 Context Handling Failures、Tool Selection Errors;Prematurely calling the ‘final_answer’ tool 出现在演示 UI,未在公开 base taxonomy 表中找到同名条目。Trace 树显示 ToolCallingAgent.run、span 约 578.818s,说明监督对象已是长时、多步工具调用链,而非单次 completion。
怎么做#
- 将现有 OpenTelemetry / 框架 trace 导入 Patronus 或同类平台。
- 从高频 failure mode 反推 rubric,再决定是否写入自定义 taxonomy。
- 采用 Suggested Prompt Fix(文档:
Suggests concrete prompt improvements)作人工评审输入,避免未验证的一键自动改 prompt(产品策略,演讲者观点)。
常见误区#
- 用单次演示 Overall 3.12/5 代表 SLA。
- 假设 taxonomy 已覆盖「过早 final_answer」——需自定义或等待产品收录。
- 忽视 建议性 修复与自动补丁的界限,引发错误自动修补循环(演讲者观点)。
LLM-as-a-judge:开发期评测与实时护栏的两条轨#
为什么#
同一「模型评模型」范式,在不同延迟预算下服务不同目标:离线对比 prompt/权重 vs 在线拦截高风险输出。
机制与约束#
Lynx(PatronusAI/Llama-3-Lynx-70B-Instruct)面向 RAG reference-free 幻觉检测;在 HaluBench(约 15k 样本,含 finance、medicine 等)上报告 Accuracy,论文称优于 GPT-4o、Claude-3-Sonnet 等同设定模型。训练使用 GPT-4o 生成的 CoT 推理轨迹做 instruction tuning——文献支持该做法;访谈「首次用 CoT 训练 evaluation model」过度宣称,不宜写死「全球首次」。
Glider(GLIDER 3.8B,基于 Phi-3.5-mini-instruct)支持 0–1 / 1–3 / 1–5 Likert、rubric、multi-metric;论文在 FLASK 等设置用 Pearson correlation 对标人类评分,在 LiveBench 部分子任务报告 F1(例如 GLIDER 0.654 vs GPT-4o-mini 0.481)。访谈「首个 SLM 对标 GPT-4o-mini」应限定为特定 benchmark,非全任务 SOTA。
| 产品 | 典型场景 | 主指标(论文) |
|---|---|---|
| Lynx | RAG groundedness、离线回归 | HaluBench Accuracy |
| Glider | Guardrails、低延迟多指标 | Pearson / F1(任务相关) |
辩论式 judge(多模型互辩)在访谈中被判为几乎无生产落地;同预训练分布的 foundation model 互辩会产生同向偏置,需分布不重叠的专用 judge(演讲者观点,无普查数据)。
怎么做#
# Glider:按 rubric 返回多指标(0–1 或 Likert)
scores = glider.score(
interaction=log,
rubric={"helpfulness": "...", "safety": "..."},
)
if scores["safety"] < threshold:
block_or_escalate()
常见误区#
- 用 Lynx 的 Accuracy 类比搜索场景的 NDCG——主持人曾作类比,属访谈类比,非论文指标。
- 在生产默认路径堆叠高延迟辩论式 judge。
- 忽略 Glider 与 Lynx 基准不同(FLASK vs HaluBench),直接横向比「谁更强」。

动态评估与可扩展监督(scalable oversight)#
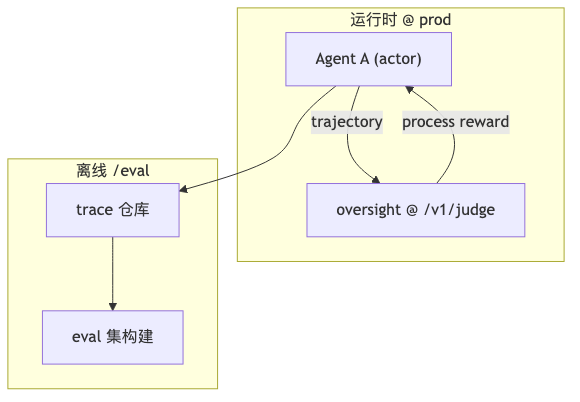
为什么#
当人类无法在规模上审完 AI 产出时,需要「能力相当的系统」在运行时评判被测 Agent(演讲者观点)。这与 Bowman et al., 2022 提出的 scalable oversight 在概念层相邻——该文不证明 Percival 有效,不可将文献结论直接嫁接为产品实证。
机制与约束#
动态评估 ≠ 放弃基准,而是对不可预知轨迹补充过程级裁判。Percival 被定位为 agentic supervision 的产品化路径之一;与 OpenTelemetry 等行业「supervision」术语访谈未精确定义一一对应,写作时应分域使用。
反直觉一点(演讲者观点,无定量调研):用户更在意工作流是否完成,而非秒级响应;为监督增加额外推理延迟在部分场景可接受。这与「测试面扩大必然拖垮 UX」的直觉并不完全一致——压力更多在算力与人力解读 trace,而非单纯 latency。
怎么做#
常见误区#
- 把「AI oversee AI」理解为取代 human-in-the-loop;访谈强调的是协作接口(如 Chat、inbox 式提问),非全自动放行。
- 将 scalable oversight 论文结果当作 Percival 的 A/B 测试结论。
记忆层:episodic 与 semantic 的分工#
为什么#
长轨迹监督需要跨 run 积累:「上次同类失败如何修」与「领域基线事实」是不同信息类型。
机制与约束#
调试文档 区分 episodic(历史 trace 中的工具调用等)与 semantic(人类对 agent 的反馈类语义记忆),用于持续改进分析。访谈观点称 Percival 核心依赖 Weaviate、collection、text2vec 向量化、按 run 近邻检索;在 Patronus 公开 docs 的 Percival 章节 检索未见 Weaviate 字样(核实日 2026-05)。Weaviate 的 multi-tenancy、hybrid search 仅说明向量库能力,不能反向证明 Percival schema。
怎么做(概念)#
- episodic:按
trace_id/run_id存 span 摘要,检索「相似失败修复史」。 - semantic:存稳定领域约束(合规条款、API 契约),与 episodic 分 collection,避免噪声污染基线。
常见误区#
- 把 Podcast 合作关系等同于已公开的 Percival 存储实现。
- 用单一向量库混合所有记忆类型,导致检索混淆工具错误与领域事实。

过程奖励、结果奖励与 Prompt / 权重编辑#
为什么#
复合 AI 系统常被拆成多步 inference,每步可有静态 eval;开放自治体更依赖 outcome + 环境反馈(主持与嘉宾共识,细节因系统而异)。
机制与约束#
- Process rewards:逐步检查轨迹内行为(工具选择、是否过早
final_answer)。 - Outcome rewards:最终是否达成业务目标(如订票成功)。
Prompt 仍是多数客户「改一处、全局抖动」的主战场(演讲者观点)。Model editing 与 sparse autoencoder、mechanistic interpretability 相邻,嘉宾称对 guardrail / eval 模型(如 Lynx)做 SAE 几乎空白——未验证「行业无人做过」。
下一代 eval 数据将更多由 Agent 拉工具/RAG/内部文档生成领域样本,并辅以 adversarial dataset generation 压测(演讲者观点);无 Patronus 公开复现流水线。
常见误区#
- 只优化 outcome 而忽略过程中「过早结束」类逻辑错误(见 Percival 演示)。
- 期待 Percival 自动整段替换 prompt;首版刻意只给建议(演讲者观点)。
未收敛的分歧(刻意并列)#
| 主题 | 常见实践 | 嘉宾/产品叙事 | 证据限度 |
|---|---|---|---|
| 静态 eval | 回归集 + CI | 高开放 Agent 需动态评判 | 分场景成立;「不可能」仅访谈定性 |
| Failure 规模 | 文档 20+ | 访谈 60 | 以 taxonomy 文档 为准,60 标演讲者观点 |
| Judge「首次」 | 多家 SLM judge | Lynx/Glider 首创表述 | 论文仅 claim 特定 benchmark |
| Weaviate 集成 | 向量库通用能力 | Percival 记忆后端 | 记忆类型有 docs;Weaviate 实现为访谈观点 |
| 延迟 vs 监督 | 越低越好 | 完成率优先 | 演讲者观点,无调研引用 |
若你要落地#
- 分层评测:确定性子链路保留静态集 + outcome;开放 Agent 上对生产 trace 做过程级 taxonomy 与抽样人工复核。
- 先接 trace,再扩 benchmark:用 Percival Debugging 类能力把「读 trace 数小时」压缩为「看 failure mode + 建议 prompt」,再反哺 eval 用例。
- Judge 选型:RAG 离线回归用 Lynx/HaluBench 协议;在线护栏用 Glider 类 SLM + 明确 rubric,并记录 Accuracy vs Pearson/F1 不同指标,避免混榜。
- 记忆分库:episodic(轨迹摘要)与 semantic(稳定约束)分 collection;Weaviate 配置在 Patronus 公开 schema 前标为待核实。
- 人工闸门:Suggested Prompt Fix 走 PR 评审,不把未验证建议自动写入生产 prompt。
参考与延伸阅读#
- Patronus AI 官网
- Percival — Agentic Supervision 产品页
- Percival Debugging Overview(官方文档)
- Percival Error Taxonomy(官方文档)
- Lynx 论文(arXiv:2407.08488)
- Lynx 开源仓库
- HaluBench 数据集
- Glider 论文(arXiv:2412.14140)
- Glider 模型(HuggingFace)
- LMUnit 论文(arXiv:2412.13091)
- LMUnit 介绍(Contextual AI)
- Scalable Oversight(Bowman et al., 2022)
- Weaviate 开发者文档
- Weaviate Multi-tenancy
- Weaviate Hybrid search
- OpenAI Models 文档(上下文与 GPT-4o mini)


