
检索列表多样化:几何后处理、评测裂缝与 RAG 上下文预算#
向量检索把「相关」召回到一个候选池里,但相关不等于列表有用。电商要避免同款刷屏,学术搜索要覆盖子领域,RAG 要把有限 context window 分给互补段落——这些需求都指向同一类问题:在已有相关性分数下,如何从 Top-N 里选出内联差异足够大的子集。Pyversity 把 MMR、MSD、DPP、Cover、SSD 等贪心多样化算法封装为 NumPy 后处理层,挂在任意 Python 检索栈之后。本文按工程主题梳理机制与边界:文献与仓库实现可核对处给出链接;Springer Nature 生产路径、默认策略变迁、YouTube+DPP 等口述标为「演讲者观点」,并写明未核实处。
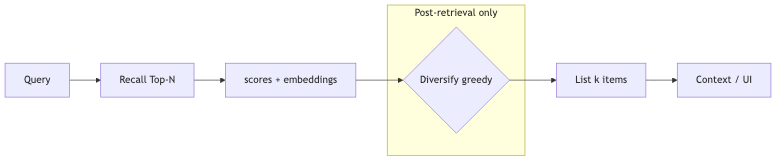
问题空间:多样化站在检索管线的哪一步#
为什么:典型 RAG / 搜索管线是 query → 稠密或混合召回 →(可选)cross-encoder 重排 → 列表构造 → LLM。前段优化的是 query–document 相关性;多样化优化的是已选列表内部的冗余。若跳过这一步,Top-10 可能全是同一主题的近邻 chunk,agent 多跳检索也会反复读到语义重叠的段落(演讲者观点:冗余上下文会浪费 token 并干扰推理;与 Lost in the Middle 类「中间信息被忽略」现象属于不同机制,本期无对照实验)。
机制/约束:多样化是 O(k) 步贪心,每步只对照已选子集与候选全集,不做全排列最优。输入为 embeddings[N,d] 与 scores[N](相关性,可来自向量距离或 cross-encoder);输出为长度 k 的索引重排。与离线 k-means 聚类不同:聚类要刻画全集结构,在线千 QPS 场景下全集二次扫描往往不现实(演讲者观点;k-means 单轮通常为 O(n·k·d),非必然 O(n²),但嘉宾用复杂度对比强调检索后处理的轻量性)。
怎么做(最小示例):
import numpy as np
from pyversity import diversify, Strategy
embeddings = np.random.randn(500, 256).astype(np.float32)
scores = np.random.rand(500) # 可与 embeddings 异源
idx = diversify(
embeddings, scores, k=10,
strategy=Strategy.DPP,
diversity=0.5, # [0,1],越大越偏多样性;内部 λ = 1 - diversity
)
常见误区:把多样化当成「换 embedding 模型」。主流做法是先用最强相关性嵌入召回,再廉价 diversify(演讲者观点);是否在训练目标里注入「天然分散近邻」尚无清晰路径(嘉宾称开放问题)。另一误区是把多样化与 query-time 聚类 / 语义 group-by 混为一谈:二者在「把相似文档归组」上直觉相近,但聚类通常面向全集结构发现,多样化面向已有分数的列表重排;嘉宾用延迟与是否只需已选子集增量来划界,而非否认概念相似(演讲者观点)。
MMR 与 MSD:边际距离 vs 全局散开#
为什么:Maximal Marginal Relevance(Carbonell & Goldstein, SIGIR 1998)是工业界最熟悉的基线:每步在候选中选使「相关性 − 与已选最大相似度」最大的文档。参数在原文记为 λ(相关性权重);Pyversity API 用 diversity ∈ [0,1],内部 λ = 1 − diversity,写作时勿与原文符号混用。
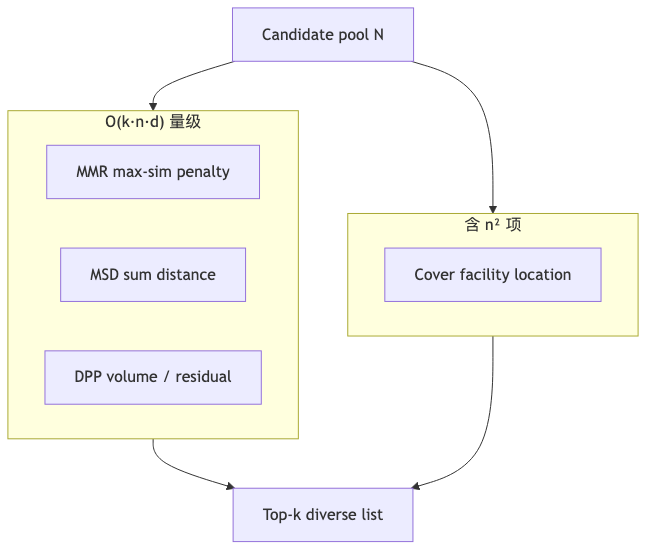
机制/约束:MMR 用 max 相似度惩罚,倾向推开与最近已选项;Max-Sum Diversification(MSD)对全部已选项累加距离,列表往往更「均匀散开」。README 给出二者同为 O(k·n·d);合成基准下 10k 候选、k=10 时 MMR/MSD/DPP 均在 15ms 量级(benchmarks/README,硬件未固定,非生产 SLA)。
怎么做:strategy=Strategy.MMR 或 Strategy.MSD,diversity 从 0.3–0.5 扫一遍;Weaviate Query Agent 的 Search 模式内置 MMR 重排,通过 diversity_weight(0–1)调节。
常见误区:(1)以为 MMR 与 MRR(Mean Reciprocal Rank)是同一缩写。(2)播客录制时嘉宾称「包默认 MMR、处方先试 DPP」——当前 main 分支默认已是 Strategy.DPP(2026-05 核对);写落地文档应以仓库版本为准。(3)把 diversity=0 当成「关闭多样化」后仍期望列表顺序与纯分数排序完全一致——实现上仍走贪心框架,应以对照实验确认行为。
DPP:体积最大化与默认策略之争#
为什么:Determinantal Point Process 在嵌入空间里最大化选中集合的「体积」(核矩阵行列式 / 贪心 residual variance),同时受向量长度与夹角约束,比单一余弦距离惩罚更有几何解释。Chen et al. 给出快速贪心 MAP,摘要写明在推荐场景做过 online A/B——支持「多样化可用产品实验验证」这一方法论,不等于 已公开证实「YouTube 首页」采用 DPP(嘉宾口述 Google YouTube 案例,本期未给出论文题名,未核实)。
机制/约束:Pyversity 复杂度 O(k·n·d + n·k²),n 很大时常数高于 MMR/MSD。作者 README 将 DPP 标为 Recommended default;合成 benchmark 上 DPP 在 ILAD/ILMD 上通常优于 MMR/MSD(指标定义见下节)。
怎么做:无先验时 strategy=Strategy.DPP,diversity=0.4 起调;与 MMR 并排 A/B 看业务 CTR / 满意度,而非只看离线 nDCG。运行时仅依赖 NumPy,可嵌在现有 Python rerank 服务中(仓库 pyproject.toml 已核实)。
常见误区:把 DPP 当成「比 MMR 慢一个数量级」——同阶贪心下差异主要在 n·k² 项;在 n≈数百、云向量库 RTT 占主导时,嘉宾与主持人倾向认为 +1ms 级多样化不如优化网络与初召回(演讲者观点)。
Cover 与 SSD:慢路径覆盖与会话序列#
为什么:科学文献搜索需要子领域覆盖(CV / NLP / 传统 ML 等),而不只是去掉重复标题(演讲者观点)。Coverage-based diversity(RecSys 2016)与 Pyversity 的 Cover(facility location)在「代表全集」目标上与 k-medoids 直觉相近,但实现名是 coverage 贪心而非字面 k-medoids。
机制/约束:Cover 先算 pairwise 相似度,复杂度 O(k·n²);README 建议 n≈10k 以上考虑 GPU/异语言重写。嘉宾称 ~10k 结果规模时优化 Cover 才值得,日常搜索 fast path 用 DPP/MMR/MSD(演讲者观点)。
SSD:Sliding Spectrum Decomposition 为序列感知贪心(滑动窗口 Gram-Schmidt),适合 feed 或带 recent_embeddings 的会话 RAG;benchmark 中列为 niche,本期口述未展开机制细节。
怎么做:文献探索、目录整理类任务 strategy=Strategy.COVER,缩小候选池再跑;会话场景试 Strategy.SSD 并传入近期已读向量。
常见误区:用 Cover 处理百万级实时召回全集——应先截断到 rerank 窗口(如 Top-200)再 Cover。
评测:BEIR、ILAD 与 FreshStack 量的是不同东西#
为什么:选型若只扫 MTEB / BEIR 的 nDCG@k、Recall@k,衡量的是相关性排序,不是列表内差异。在 BEIR 式任务上对 diversify 后列表跑同一指标,往往难涨分——因为优化目标已从「单点相关」变为「列表结构」(演讲者观点;Pyversity 自有 CF benchmark 显示 DPP 可 +nDCG,属特定合成设定,不可外推为 BEIR 普适结论)。
机制/约束:
| 指标 | 来源 | 含义 | 边界 |
|---|---|---|---|
| ILAD | Pyversity metrics.py | 列表内配对平均 (1 − cos sim) | 基准套件内标准名;更广 IR 文献统一性未逐篇核对 |
| ILMD | 同上 | 列表内最小 (1 − cos sim) | 同上 |
| coverage / α-nDCG | FreshStack | nugget 覆盖、带权 nDCG | 需主题/nugget 标注;不是 ILAD |
| nDCG@k | BEIR/MTEB | 相关性 | 不评 diversity |
FreshStack 面向技术文档 RAG:社区问答 → nugget 抽取 → 评检索是否覆盖答案块;与 MTEB 上同名 FreshStackRetrieval 代码检索任务不是同一套框架(核对报告已标注)。
怎么做:离线先用 ILAD/ILMD 做算法对比与 diversity 扫参;有 nugget 标注时加 FreshStack coverage;生产以 A/B(有/无 diversify)测 CTR 或满意度为准(演讲者观点;Chen et al. 2017 摘要支持 A/B 方法论,Springer 管线尚未对多样化做 A/B,统一 benchmark suite 未发布)。
常见误区:用 BEIR 涨分证明多样化无效;或把 FreshStack coverage 写成 ILAD。嘉宾称「漂亮的 recall / nDCG / ILAD 曲线」仍是代理,唯一可靠验证是线上 A/B(演讲者观点)——这与推荐系统多样性文献的一般做法一致,但不意味着离线指标无用:离线用于筛算法族与超参,线上用于验证业务假设。另:BEIR 各子集 qrels 可含多条相关文档,更准确的说法是「主流榜不衡量列表内差异」,而非「每条 query 只有一个 relevant」。
RAG、Agent 与「几何 vs LLM」多样化#
为什么:RAG 与 multi-hop agent 的上下文窗口有限;Pyversity README 将动机写明为 Avoid feeding the model near-duplicate passages。首轮检索若广覆盖、低重复,后续 hop 才有信息增益空间(主持人场景 + 嘉宾认同用例方向)。
机制/约束:多样化仍是检索列表后处理,不等于 agent 工作流本身。Weaviate Query Agent 提供 Ask 与 Search;播客口语中的 think 模式在 2026-05 核对的公开文档中未出现(可能为口语或旧称)。Search 的 diversity_weight 即内置 MMR。
用 LLM 直接挑选「多样文档集」缺乏几何保证、延迟与成本高(演讲者观点),类比「用 LLM 做 rerank 可以,但专用 cross-encoder 往往够用」。embeddings 与 scores 可来自不同模型——scores 须准确反映 query–doc 相关性(演讲者观点);multi-vector(ColBERT / MaxSim)可投影为单向量再套用算法,专门多样化 multi-vector 的文献嘉宾称未找到(边界未验证)。
怎么做:召回 Top-50 → cross-encoder 打分 → Pyversity DPP 取 Top-10 → 拼 prompt;与 Query Agent 内置 MMR 二选一,避免重复 diversify。
常见误区:在 agent 每一跳都堆相似 chunk「提高召回」;或把 Voyage-3-large(偏相关)与 Arctic 2.0(偏多样)分工当成稳定规律——嘉宾称未观察到稳定模式(演讲者观点)。无多样化时加随机扰动有时也能满足探索需求,但方差大、不可复现;多样化是更可控的替代(演讲者观点)。电商场景「多样」常指去同款重复、同色可并存;科学搜索则更接近 serendipitous discovery(主持人转述 Pierce 概念)——同一套算法参数很难同时最优,应按产品语义选策略族。
若你要落地#
- 默认路径:初召回用当前最强相关性嵌入 + reranker;在 Top-200 上跑 DPP(
diversity0.35–0.55 网格),别跳过扫参直接沿用 MMR 习惯。 - 参数与符号:统一使用 Pyversity 的
diversity(越大越多样),勿与 MMR 原文 λ 方向搞反。 - 评测分层:离线 ILAD/ILMD 筛算法;有 nugget 时加 FreshStack coverage;上线用 A/B 看业务指标,BEIR nDCG 仅作相关性 sanity check。
- 场景分流:商品去重 → MMR/MSD 往往够用;文献/探索式搜索 → 缩小池后试 Cover;会话 feed → 评估 SSD。
- 性能预算:n≤1e4、d≤768 时 Pyversity 纯 NumPy 通常不是瓶颈;先压网络与初检索,再考虑 Rust/GPU(演讲者观点)。
参考与延伸阅读#
- MMR 原论文 — SIGIR 1998
- Max-Sum Diversification — arXiv:1203.6397
- DPP 机器学习教程 — arXiv:1207.6083
- 快速贪心 DPP MAP 与在线实验 — arXiv:1709.05135
- Coverage-based 推荐多样化 — RecSys 2016
- SSD 滑动谱分解 — arXiv:2107.05204
- Pyversity 仓库与 API
- Pyversity PyPI 包
- Pyversity 合成延迟说明
- FreshStack 论文 — arXiv:2504.13128
- FreshStack 代码与评测
- BEIR 基准与评测指标
- MTEB 排行榜
- Weaviate Query Agent 文档
- Query Agent Search 与 diversity_weight
- Lost in the Middle — 长上下文位置偏差


