
当查询变成整段代码:RAG 评测与搜索型 Benchmark 的分裂#
生产里的 RAG 管线早已不是「用户敲五个词、系统返回十条蓝链」。开发者会把报错栈、LangChain 配置片段、多仓库上下文一并塞进检索器;Agent 还会在生成过程中反复查库。与此同时,选型仍常看 BEIR 上的 nDCG@10 或 MTEB 排名——这些榜多数假设 短查询、秒级响应、排名列表质量。BEIR 共同一作 Nandan Thakur 在公开讨论中主张:搜索型 IR 评测与 长上下文、事实级覆盖 的 RAG 评测正在分裂;二者不应被单一数字合并。(下文标注 演讲者观点 处来自其访谈表述,已与论文核对处单独标明。)

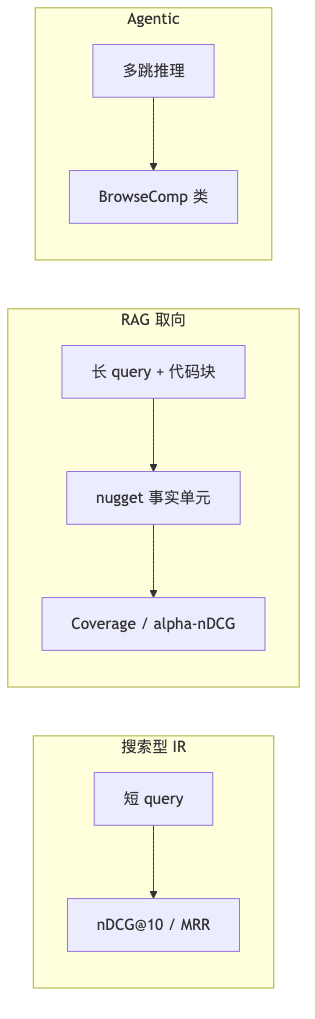
问题空间:三条互不替代的评测轴#
| 轴 | 典型代表 | 测什么 | 容易误读之处 |
|---|---|---|---|
| 异构零样本检索 | BEIR、MIRACL | 短 query → 文档排名 | 高分 ≠ 长代码问答可用 |
| 开发域 RAG 检索 | FreshStack | SO 长问题 + GitHub 语料上的 nugget 覆盖 | 偏 检索 test collection,非端到端生成榜 |
| Agentic / 多跳 | BrowseComp、BRIGHT | 推理链 + 多次检索 | 延迟预算与 BEIR 不可比 |
演讲者观点:Wikipedia、HotpotQA 式「短问 + 已知世界知识」的 RAG 评测,模型可能不靠检索就能答;更应测 小众域、新文档、需长总结 的任务(其以 TREC RAG 中多因素人物关系类问题为例)。该判断是评测哲学,非 BEIR 论文结论。
若你维护向量库或 RAG 网关,常见失败模式是:线上 query 分布已迁移到「粘贴半页日志」,而离线仍只跑 MS MARCO 式短 query 回归——外推误差往往体现在 召回够用但 nugget 覆盖不足,而非 nDCG 小数点后的排名抖动。
BEIR:为什么 IR 与 NLP 需要同一套零样本榜#
为什么#
BEIR 论文 指出:神经 IR 长期在 同质、窄域 设定下比较(例如在 MS MARCO 上训练又在同分布上评测),难以判断模型能否迁移到法律、生物医学、争议检测等 分布外 任务。BEIR 聚合 18 个公开集、9 类检索任务,统一报告 零样本 nDCG@10(pytrec_eval 的 ndcg_cut_10)。
机制与约束#
- DPR 在 BEIR 上被论文描述为少数非 MS MARCO 训练的稠密基线之一,零样本泛化在 18 集中普遍弱于在 MS MARCO 上训练的模型——说明「同源训评高分」与「跨域榜」可脱节(文献)。
- 主表以 nDCG@10 为主;beir 框架亦支持 MRR、Recall@k,但 论文主结果不以 MRR 为统一主轴。
- 演讲者观点:选 @10 是为模仿搜索结果页前若干条;论文原文仅写用户希望相关结果 靠前,未出现 Google/SERP 明文——宜视为工程类比,非 BEIR 原文表述。
怎么做(最小示例)#
# 概念:beir 评测检索器在多个数据集上的 nDCG@10
from beir import util
from beir.datasets.data_loader import GenericDataLoader
from beir.retrieval.evaluation import EvaluateRetrieval
dataset = "nfcorpus"
url = f"https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/{dataset}.zip"
data_path = util.download_and_unzip(url, "datasets")
corpus, queries, qrels = GenericDataLoader(data_path).load(split="test")
# retriever.search(...) 后:
# ndcg, _map, recall, precision = EvaluateRetrieval.evaluate(qrels, results, [10])
常见误区#
- 用 BEIR 榜首直接选型 长查询 RAG 产品——查询长度、标注粒度、延迟假设均不同。
- 把 MRR 与论文主表 nDCG@10 混为同一「BEIR 分数」。

FreshStack:长查询、nugget 与 test collection 的「故意作弊」#
为什么#
FreshStack 面向 开发者 RAG:查询来自 Stack Overflow(2024-10 dump,保留 accepted answer),筛选 2023 年起 的小众技术主题以降低 LLM 训练污染;语料为对应标签下的 GitHub 公开仓库切块(文献/ HF 数据集卡)。演讲者观点:坚持真人社区问题,批评部分 RAG benchmark 过度依赖合成 query。
机制与约束#
- 分块:论文规定语料 maximum 2048 tokens(文献)。访谈称因当时 embedding 上下文上限而折中——论文未写该因果,不宜当作官方解释。chunk 越大,单文档内事实越集中,但跨文件依赖(如 monorepo 多包引用)更依赖检索器多次命中,而非一次大块命中。
- 检索指标:除排名质量外,Coverage@20 直接对应「前 20 篇能否撑起全部 nugget」——比「第 11 名相关文档是否存在」更贴近 RAG 生成前的上下文充足性(文献定义;与生成端 hallucination 仍非同一指标)。
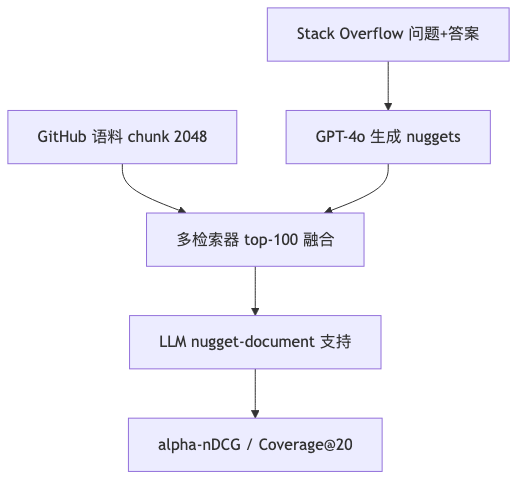
- Nugget:core concept or atomic fact essential in a response;谱系可追溯至 TREC QA 的 information nugget(论文引 Voorhees 2003、Lin 2005/2006 等)。FreshStack 用 GPT-4o 从问答生成 nugget,并在子集上由研究者验证精度/覆盖(文献)。
- 标注:单元是 nugget–document 支持(二元),而非整段长 query 与文档的「部分相关」。池化时对多路 inference(子问题分解、HyDE 类闭卷答案等)与 oracle(答案全文、nugget 拼接)检索,每模型 top 100,分数归一化后 相加融合,再对融合结果 top 20 做 LLM 支持判断(文献;与访谈口述的 top-50 数字不一致,以论文为准)。
- 演讲者观点:构建 test collection 时混合 BM25、稠密向量、ColBERT 类检索器以增加标注多样性,在 test collection 语境下属于某种「cheating」——目的是减少 holes(应标未标进池的文档)。文献核对:FreshStack 池化用 BM25、BGE、E5 Mistral 7B、Voyage-large-2 及分数融合,未使用 ColBERT;MIRACL 标注阶段为 BM25 + mDPR + mColBERT(top-10 判断),融合为归一化 平均,亦非 RRF。
检索侧指标含 α-nDCG@10、Recall@50、Coverage@20(nugget 被前 20 文档覆盖的比例)等(文献),与 BEIR 主榜不可直接横比。
怎么做(最小示例)#
从 Hugging Face 加载查询与 nugget 标注(需接受 FreshStack 许可条款):
from datasets import load_dataset
queries = load_dataset("freshstack/queries-oct-2024", split="train")
# 字段含 nuggets、nugget 级 relevant_corpus_ids 等;见数据集卡
自建私有集时可复用范式:分解/多路查询 → 融合扩池 → nugget 级判支持,但上线服务是否同样多路融合需单独做延迟与成本评估(演讲者观点)。
常见误区#
- 把 FreshStack 分数当作 端到端 RAG 答案质量——它主要评 检索 test collection。
- 假设访谈中的 RRF 即 FreshStack 默认实现——论文为 归一化分数求和;RRF 见 SIGIR 2009,与 MIRACL/FreshStack 建池写法 不同。
- 追求「召回越多越好」——演讲者观点 提出 minimal spanning subset:若少量文档已覆盖全部 nugget 与引用,优于把 20 篇塞进 context;非 已标准化竞赛指标。


查询改写:SPLADE、分解与「理想 embedding」的张力#
为什么#
经典 IR 的 query expansion 对 BM25、ColBERT、SPLADE 均常有收益。演讲者观点:理想状态下,端到端 embedding 应 无需 显式 rewriting;但现实里用户查询变长变复杂后,query decomposition(FreshStack 子问题、BRIGHT 代码/数学)在现阶段仍有必要——与「理想」并存,而非二选一结论。
机制与约束#
- SPLADE(SParse Lexical And Expansion):在词汇表维学习稀疏激活,实现 隐式 expansion,缓解 vocabulary mismatch(文献);可部分替代手工加词,但不等于可删掉所有 LLM 改写步骤。
- FLARE(arXiv:2305.06983):生成中对 低置信 token 触发 forward-looking 再检索,属 active RAG 一族(文献;演讲者观点 将其与 multi-hop 评测动机一并提及)。
怎么做#
对短 Web 查询:可先 A/B 无改写 vs SPLADE/稠密混合;对长开发问题:在标注或评测集上尝试 nugget 级子查询,再与 HyDE 类 oracle 路对照 FreshStack 论文的 inference/oracle 划分。
常见误区#
- 把 MTEB/BEIR 上的单向量榜首等同于「长查询无需分解」。
- 在生产环境照搬 test collection 的 四模型融合——演讲者观点 承认线下建池强、线上 multi-hybrid 效率差。
Agentic 检索与延迟预算的再谈判#
为什么#
BRIGHT 等强调更长、需推理的查询;BrowseComp 类任务需要代理式浏览与多跳检索。演讲者观点:此类任务 必须 agentic retrieval,单次搜索不够;与 BEIR 短 Web 查询上「分解有帮助但非必须」形成对照。
机制与约束#
- 延迟:读 PhD 时强调检索延迟;现在 ChatGPT/推理模型用户愿为答案质量等 数分钟(演讲者观点,行为假设,无统一实验编号)。
- 专利检索 等:可接受 30 分钟–1 小时 离线、多级 reranker(monoT5/duoT5 等 Waterloo 系工作)——与 BrowseComp「agent 浏览 20 分钟」同属 正确性优先、延迟不敏感 族(演讲者观点)。
- FLARE 与 Search-R1 等把 何时检索、检索什么 纳入训练或循环,与静态 top-k 检索评测不同轴(Search-R1 细节本稿未独立核验)。
怎么做#
为 agent 产品单独建 多跳成功率 / 工具调用轨迹 评测,与 nDCG@10 分栏报告;引用 TREC RAG Track 的 nugget 级 A_strict 等指标时,对齐当年赛题定义而非往年口径。
常见误区#
- 用单一「检索准确率」概括 BrowseComp 与 BEIR。
- 忽略 streaming 带来的「可接受等待」变化,仍按 200ms SLA 设计多跳 agent(演讲者观点)。

域专用 Embedding 与通用模型:尚无标准答案#
演讲者观点:承认「不知道标准答案」;小模型难压缩多域知识,但 decoder/LLM 底座变大 后,通用跨域训练可能变容易;knowledge cutoff 仍可用 RAG 补新文档——需在 你自己的域 上实测,而非照搬榜一。
AIR-Bench 等合成/模拟域 benchmark 在缺乏人工标注时有用(演讲者观点);与 FreshStack「真人 SO」路线形成 不同取舍,不构成孰优孰劣的单一结论。
未在本访谈字幕中展开:主持人曾问 FreshStack 的 hard negative labeling,嘉宾转向 mixture of retrievers——不可 将本集当作 hard negative 训练指南。
结构化检索与分页:评测空白#
房产 App「城市 + 500 条在售 + 分页聚合」类需求,涉及 text-to-SQL、过滤与 MapReduce 式并行推理,而非传统 BEIR 文本相关性。演讲者观点:个人研究重心在 纯文本检索与 embedding;承认 pagination 重要,但 未 给出替代 nDCG@10 的分页评测方案——工程上宜自建 分面检索 + 聚合正确性 指标,勿期待 BEIR 延伸覆盖。


若你要落地#
- 分轴建榜:短查询保留 BEIR/MTEB 类检索榜;产品若已是长上下文 + 代码块,增加 FreshStack 类或 自建 nugget 评测,勿用单一 nDCG@10 选型。
- 复现 FreshStack 标注时:以论文 top-100 融合、top-20 判支持 为准;融合策略写清是 分数和 还是 RRF,勿混称。
- 报告 agent 与搜索:BrowseComp/BRIGHT 与 BEIR 分栏;延迟 SLA 单独声明。
- 建池可厚、线上可薄:多检索器融合扩池在 离线标注 有效(演讲者观点 + 文献),生产路径需另做 QPS/成本测算。
- 争议域先 A/B:域专用 embedding(如 Voyage 域模型路线)与通用大 embedding 在你的 query 分布上实测,而非只看公开榜。
参考与延伸阅读#
- BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models
- BEIR 评测代码仓库 beir-cellar/beir
- FreshStack: Building Realistic Benchmarks for RAG on Developer Documentation
- FreshStack 查询集(Hugging Face)
- FreshStack 语料(Hugging Face)
- MIRACL: A Multilingual Retrieval Dataset
- MIRACL 项目主页
- SPLADE v2: Sparse Lexical and Expansion Model
- Reciprocal Rank Fusion(SIGIR 2009)
- FLARE: Active Retrieval Augmented Generation
- BRIGHT: A Realistic Benchmark for Retrieval-Augmented Generation
- TREC RAG Track 官网
- MTEB Leaderboard
- Sentence-Transformers 训练与评测概览
- RAG 原始论文(Lewis et al.)
- AIR-Bench: AI Retrieval Benchmark


