
REFRAG:把 RAG 上下文从「token 串」变成可压缩表示#
生产级 RAG 的常见路径是:检索若干 passage → 拼进 prompt → 让 decoder 做全长 self-attention prefill。瓶颈往往在 decoder 侧算力与 TTFT,而不是检索本身。向量库与 reranker 优化的是「找什么」;一旦 top-(k) 文本进入 LLM,prefill 仍按 token 长度计费。
REFRAG(Representation For RAG,Meta Superintelligence Labs,一作 Xiaoqiang Lin)提出 compress → sense → expand:用 chunk 级表示缩短 decoder 序列,再用 RL 对高信息熵片段选择性展开。论文摘要给出相对先前工作的 3.75×、16× 有效上下文扩展,以及特定设定下最高约 30.85× TTFT——这些数字 强依赖 对照模型(如 CEPE)、compression rate (k)、是否使用 pre-computed cache 与序列长度,不能脱离 Figure 2 / Table 2 语境泛化。
下文按机制、训练与评测边界组织;访谈中的产品判断与论文未写明的数字会单独标注。若你已在用 CEPE 等「压缩式长上下文」方案,可把 REFRAG 看作在 RAG 块稀疏注意力 假设上,把压缩与 按需展开 写进训练目标,而非仅改 inference 剪枝。
问题:RAG prefill 在算什么#
为什么:检索 top-(k) 后,passage 常以数百 token 计;多段拼接后 prefill 复杂度近似随序列长度二次增长(标准 Transformer attention)。行业侧更常盯 TTFT(time to first token),而不仅是吞吐。
机制/约束:论文在 RAG 拼接上下文上观察到 block-diagonal attention patterns——passage 内注意力强于跨 passage(附录有 LLaMA-2-7B-Chat 可视化)。据此主张大量 跨 chunk 的细粒度 attention 可省略;这与「RAG 必须全文互看」的直觉相悖,但 未给出可部署的定量阈值(演讲者观点:跨 chunk 权重「很小」)。
常见误区:把「压缩」理解成向量库的 ANN 量化。REFRAG 的 compression rate (k) 指每 (k) 个 token 在 decoder 占 1 个位置((L=s/k)),与 embedding 的 bit-width 无关(§2)。
多粒度表示:chunk embedding 进 decoder#
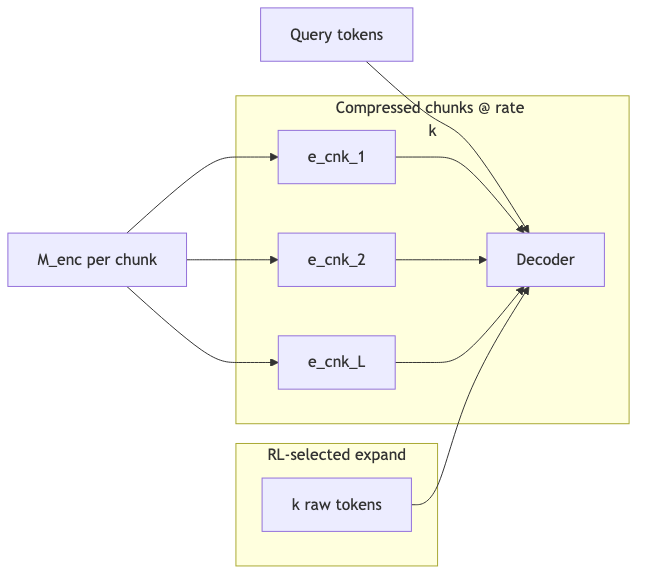
为什么:若仍把全部 raw token 喂给 decoder,prefill 长度几乎不变。REFRAG 用独立 encoder (\mathcal{M}_{\text{enc}}) 将每个 chunk (C_i) 编码为 (\mathbf{c}_i),经投影 (\phi) 得到 (\mathbf{e}^{\text{cnk}}_i=\phi(\mathbf{c}i)),与问题 token embedding 一并输入 (\mathcal{M}{\text{dec}})(§2 Model Architecture)。
机制/约束:访谈用 VLM 用少量 embedding 表示图像 作类比(演讲者观点;论文正文未写 modality / vision)。可核对的是:预计算 chunk embedding 与 在线并行编码 两条路径均成立;即使不做全库预计算(「REFRAG without cache」),因 decoder 序列变短仍可加速(Figure 2 报告 (k=16)、长度 16384 时最高约 16.53× TTFT,须对照基线与是否含 cache)。
怎么做(算例):(k\in{16,32}) 为论文主设定。16 384 token、(k=16) → 1024 个 chunk 位置;(k=32) → 512。访谈「16k 压到约 1k」与 (k=16) 算术一致(已核实)。
常见误区:认为「一个 embedding 代替整篇文档」。访谈称早期把 数百–上千 token 压成单个 embedding 完全失败(仅访谈);论文仅有 (k) 增大后的性能回归曲线(Figure 10),无该探索叙事。
论文在 (k=32) 时相对 LLaMA 报告 TTFT 32.99×、相对 CEPE 3.75×(§2),同时在 CPT perplexity 上仍 competitive——这与访谈「(k=32) 可与无压缩 LM 相当」方向一致,但论文表述更谨慎:并非 宣称在所有任务上等同 LLaMA-Full Context 无损。(k>32) 时性能回归趋势明确;生产上应把 (k) 当作 延迟–质量旋钮,而非越大越好。
注意力分工与块级 prefill#
为什么:在压缩模式下,decoder 只见 (L) 个 chunk 位置,块内 token–token attention 在 compressed 段消失;需要展开的 chunk 再以 (k) 个 raw token embedding 进入(§9.1 混合输入)。
机制/约束:encoder 对 (C_i) 做标准编码(论文用 RoBERTa,未逐句写死「块内 full self-attention」,但符合常规 encoder 行为)。Decoder 在压缩段为 chunk 级 互注意力;展开段恢复 token 级。主持人提到的 block diagonal attention 与论文术语 一致。
常见误区:以为去掉跨 chunk attention 后 永远不需要 raw token。高熵事实(数字、细粒度字段)往往需 selective expansion;单靠重建损失,perplexity 可能几乎不降,但「复述 chunk 内长数字」仍失败(§3.1 + 演讲者观点)。
RL 选择性展开:二值决策及其边界#
为什么:统一压缩会丢失 chunk 内高熵信息;需在 延迟 与 保真 间折中。
机制/约束:策略在 chunk embedding 上 顺序 选 (T’=pL) 个 index 做 expand;用 Pointer Networks 的 masking 约束 action space(论文脚注);优化用 GRPO,而非复现 Vinyals 原训练目标。Reward 与下一段 perplexity 相关(§9.1)。访谈描述「一次前向 + mask 重归一化 softmax 无放回采 (m) 个」与 sequential + 不重算 logits 精神一致,但不宜字面等同(部分核实)。
与检索多样性的关系:主持人问 MMR/去重是否会削弱「可省略跨 chunk attention」;嘉宾答 RL 展开与多样性机制无关,多样性影响的是 不同 chunk 间 注意力,根因是 chunk 来自不同句子/文档(演讲者观点;论文提到 dedup 后的 block-diagonal,未讨论 MMR)。
常见误区:把展开当成连续粒度控制。当前实现本质是 二值:整 chunk 要么 1 个 (\mathbf{e}^{\text{cnk}}),要么展开为 (k) 个 token(演讲者观点);动态 chunker / 动态 tokenizer 被列为未来工作。
策略网络 (g_\theta) 在 chunk embedding 上堆 两层 Transformer(§9.1),复用 ({\mathbf{c}_i}) 而不在每次选择后重算 logits——这是为 训练吞吐 做的工程取舍。推理延迟上,展开比例 (p)(展开 chunk 数 (T’=pL))直接决定 prefill 长度在「纯压缩」与「接近全 token」之间的落点;若业务以 TTFT 为 SLA,应把 (p) 与 (k) 一并纳入 profiling,而不是只调 top-(k) 检索数。
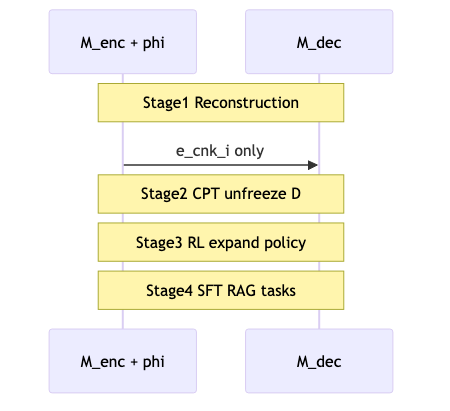
训练:四段流水线与对齐陷阱#
为什么:若只做 RAG 式 SFT,decoder 可能 忽略 chunk embedding、退回参数记忆(访谈强调;论文用 reconstruction + curriculum 规避,§3.1)。
机制/约束(论文可归纳为四段,无 “four-stage” 标题):
- Reconstruction:freeze decoder,训 encoder + (\phi);从单 chunk (\mathbf{c}1) 重建 (x{1:k}) 起步。
- CPT(continual pre-training):next paragraph,unfreeze decoder。
- RL selective compression。
- SFT:RAG、多轮等。
Curriculum 在 CPT/reconstruction 内另有 Stage 1–9 数据混合(Table 8),≠ 访谈口中的「四阶段」专有名词。
怎么做(资源):主实验 LLaMA-2-7B decoder;论文默认 8 nodes × 8 H100、FSDP、Bfloat16(§10.2)。访谈「单机 8 卡 5–6 天 / 8 机×8 卡 1–2 天」(仅访谈;论文未给 wall-clock)。实现栈 PyTorch + Hugging Face(仅访谈);facebookresearch/refrag 截至 2026-05 为 404,复现未能核实。
常见误区:跳过 reconstruction/curriculum。附录 ablation 显示去掉任一项对齐 显著变差(已核实)。
CPT 阶段使用 Slimpajama 子集约 20B tokens(§10.2),规模远大于 RAG SFT 的 1.1M 条样本。这解释了为何访谈建议读者 优先看 pre-training 与 RL 章节:主表 1–2 的 perplexity 反映的是 continual pre-training 是否学会「读压缩上下文」;RAG exact match 表则是 在已对齐模型上的应用层展示。若你的场景只有少量领域 QA 数据、无法承担 CPT,应预期 无法复现 论文级 TTFT–质量折中,最多借鉴架构思想做小规模试验。

评测:该看哪张表、数字如何读#
为什么:RAG 下游任务(QA、摘要)易掺入 SFT 与检索器差异;访谈主张 严格结论在 CPT perplexity 与 RL(演讲者观点);论文 §5 仍花篇幅写 RAG 应用,不宜单方面贬低。
| 维度 | 论文可核对 | 访谈/未核实 |
|---|---|---|
| CPT 主指标 | Perplexity(Table 1–2) | — |
| RAG | Exact match,16 tasks 平均 % 提升;实现 stricter(脚注) | 「200 万条」SFT → 论文 1.1M |
| 同延迟 | REFRAG 8 passages vs LLaMA 1 passage:strong retriever +1.22%,weak +1.93%(§5.1) | 「约 +2%」量级接近但需标 retriever |
| TTFT | 摘要 30.85×;§2 有 16.53×((k=16), 16384, cache)等 | 须写清基线与 cache |
| 数据消融 | 未报告 needle-in-haystack 式消融 | 嘉宾:架构与长上下文数据 兼有,本工作 未做数据消融 |
常见误区:把 RAG 表的 exact match 平均提升 说成 pass@k 或 MRR;把 equal latency 理解成「相同 token 数」。

向量库与 Agent:产品张力(多为推断)#
向量库:常规做法对检索 embedding 重度量化 且推理时 丢弃,只保留 raw text。REFRAG 若产品化,访谈认为需要 全精度 chunk 向量进入 decoder,数据库重心从「存 passage 文本」转向「存可解码表示」(演讲者观点;论文未论证 ANN 量化对比)。量化 chunk 向量仅在与 预计算落盘 相关的工程场景被提及为「可另做」。
Agent:论文提及 multi-turn / agentic;访谈将 search agent(大量搜索结果塞 prompt)与 GUI、多模态、长工具历史视为 同一类上下文管理(演讲者观点)。主持人展望「API 返回 REFRAG 向量、agent 间传递向量」—— 无实验支撑。
TTFT 与 Serving:量化、线性注意力、专用芯片(Cerebras/Groq 等)与 REFRAG 可能正交(嘉宾判断),论文 未做组合实验。
长上下文数据 vs 架构:主持人援引 lost in the middle / context rot——仅靠架构能否解决,还是必须配 needle-in-haystack 式长上下文训练?嘉宾答 二者兼有,但 REFRAG 未做数据消融(演讲者观点;论文亦无同类实验)。落地时若你的基座未行长上下文 CPT,block-diagonal 假设在域外数据上是否成立,需要 自行验证,不宜外推论文 LLaMA-2-7B 设定。
结构化抽取:主持人问「按字段展开含 date published 的 chunk」是否会替代传统 LLM 结构化抽取。嘉宾称可能影响数据库/RAG 服务形态,但自称非数据库专家(演讲者观点)。这与 Weaviate 等 schema 化存储并不自动等价;更稳妥的路径是把 REFRAG 展开视为 推理期注意力预算分配,而非取代 ETL/抽取流水线。
若你要落地#
- 先对齐评测口径:区分 CPT perplexity(Table 1–2)与 RAG exact match(§5.1);复现 equal-latency 时固定 passage 数、retriever 强弱与是否 cache。
- 从 (k=16) 或 (32) 做延迟–质量曲线:勿假设任意 (k) 或「单 embedding 代替整段」;论文显示 (k=32) 仍 competitive,更大 (k) 回归。
- 训练侧预留 reconstruction + curriculum:不要指望纯 RAG SFT 让 decoder 信任 chunk 表示。
- 存储与 Serving 分开设计:检索 ANN 量化 ≠ REFRAG 的 (k);若走预计算路径,评估全精度 (\mathbf{e}^{\text{cnk}}) 的存储与加载成本。
- 开源前以论文为准:代码仓库未公开时,用 HTML 版 §2–§3 与附录 §9.1 对照实现,访谈数字(2M 数据、训练天数、VLM 类比)仅作线索。
参考与延伸阅读#
- REFRAG 论文摘要(arXiv:2509.01092)
- REFRAG HTML 全文 — 架构 §2
- REFRAG — 训练配方 §3.1
- REFRAG — RAG 实验 §5.1
- REFRAG — RL 选择性展开 §9.1
- REFRAG — 算力与超参 §10.2
- REFRAG PDF 印刷版
- Retrieval-Augmented Generation(Lewis et al., 2020)
- Pointer Networks(Vinyals et al., 2015)
- Lost in the Middle(Liu et al., 2023) — 长上下文位置偏差,与 block-diagonal 讨论相关
- Needle In A Haystack — 长上下文评测范式 — 论文未做同类数据消融时的对照阅读
- CEPE — 压缩式长上下文对照(论文 bib)
- GRPO — REFRAG RL 优化引用(Shao et al., 2024) — 见论文参考文献列表
- Hugging Face Transformers — 访谈称实现基础;论文正文未写明
- facebookresearch/refrag — 论文声明仓库 — 核实日 404,落地前需再查
- Weaviate 向量数据库文档 — 与「存 passage vs 存 chunk 表示」的产品讨论对照(非 REFRAG 官方规范)


