
企业 RAG 与 Agent:当向量库遇上四十年分析软件#
受监管行业里的 builder 常面对同一组张力:非结构化数据占多数、模型迭代快于合规审批、POC 密度远高于可运维生产。SAS 的 Saurabh Mishra 与 Weaviate 联合创始人 Bob van Luijt 在一期技术对谈里,分别从企业分析软件与开源向量数据库两侧拆解这些张力——下文按工程主题重组,不按时序复述;可核对主张绑定 RAG 原始论文、SAS Retrieval Agent Manager(RAM)、Weaviate 文档 等一手来源,其余标为演讲者观点。
问题空间:三条并行曲线#
企业 AI 落地很少卡在「能不能调 LLM」,而卡在三条曲线是否对齐:
- 数据曲线:文档、手册、工单、扫描件持续变更;SAS 博客 称企业数据 >80% 为非结构化——该比例出自 SAS 二次陈述,未在文中给出可复现调研链接,宜作方向性判断而非审计数字。
- 模型曲线:BYO LLM、嵌入模型、量化与 ONNX 加速(RAM Features List 有提及)使推理侧可选型,但知识截止日期与合规边界不会随 API 版本自动解决。
- 组织曲线:B2C 产品(如 ChatGPT)的周活规模拉高高管对「AI 战略 / agent 数量」的焦虑(演讲者观点),与「企业 RAG 其实仍处早期」的工程判断并存——两条叙事不必收敛为同一结论。
能力演进:Retrieval、RAG 与 Agent#
为什么#
同一团队里「RAG」可能指检索增强生成模式,也可能指含分块、嵌入、入库的整条数据管道(SAS 侧强调后者权重更大,演讲者观点)。若不先对齐语义,排期与验收会错位。
机制与约束#
Bob 将企业能力概括为 retrieval → RAG → agents 三阶段(演讲者观点)。学术上,Lewis et al., 2020 将 parametric memory(预训练 seq2seq)与 non-parametric memory(dense vector index)组合——索引可更新而无需重训全部生成参数,即「解耦」在架构层的含义;论文仍对联合组件做 fine-tune,不等于生产上永远零协调。
Saurabh 补充时间尺度:行业「历史性」叙事往往只回溯一年;严肃 RAG 投入约自 2024 上半年起,且 「R 之前」 的数据准备被长期低估(演讲者观点)。
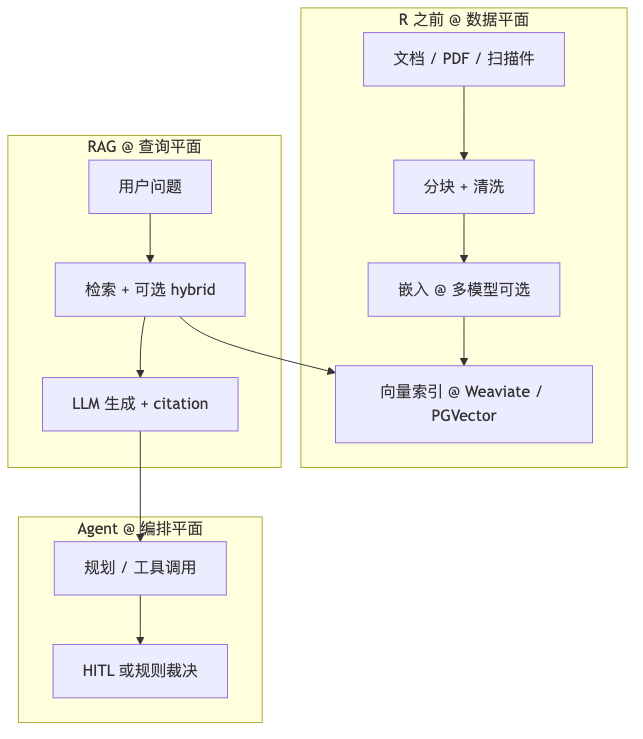
怎么做(最小示例)#
概念上把三类 SLA 分开验收:索引新鲜度(小时/天)、检索 recall@K、生成 groundedness——勿用单一「聊天好评率」替代。
ingest_job → chunk_store + vector_index
query → retrieve(k=8, filter=tenant_acl) → prompt → answer + citations
常见误区#
- 把「上了向量库」等同于「完成了 RAG」。
- 用 Agent 编排掩盖劣质分块(garbage in, agent out)。

「R 之前」:嵌入管道才是隐性主战场#
为什么#
SAS RAM 产品页 定位处理 unstructured enterprise data(含 PDF、扫描件)。若 ingest 质量差,再强的生成模型也只能放大噪声。
机制与约束#
Saurabh 称 SAS 在既有 复杂 AI 管道引擎 上验证文档→嵌入流程,可接 SAS 自训或外部模型(演讲者观点;引擎 SKU 未在公开 RAM 页点名,待架构白皮书核实)。访谈称 no-code UI 可在分钟级完成 document→embedding(演讲者观点,无公开 benchmark)。
制造场景叙事(个案 / 演讲者观点):遥测 ML 告警 → 文档/RAG 生成可执行维修计划;SAS 预测性维护博客 主张在 ML 检测之上叠加 RAG 编排,且 doesn’t replace your existing ML systems——与「预测 + 检索 + 生成」分层一致,但未披露具名客户与量化指标。
怎么做(最小示例)#
为每个文档版本保留 doc_id、chunk_id、embedding_model_id,便于回溯与重嵌:
{
"doc_id": "manual-v3",
"chunk_id": "manual-v3#p12",
"embedding_model": "text-embedding-3-large",
"vector_ref": "weaviate://Class/uuid"
}
常见误区#
- 只调 prompt,不版本化 chunk 与嵌入模型。
- 忽视扫描件 OCR 错误在向量空间的系统性偏差。

微调与 RAG:叠加,不是二选一#
为什么#
「已经 fine-tune 就不做知识库」在数据持续变更的场景下往往不成立。
机制与约束#
Saurabh:微调模型仍是时间点快照;除非更新频率跟上业务数据,否则会 stale;RAG 用于注入新鲜事实(演讲者观点)。这与 RAG 论文 用显式非参数记忆缓解 updating world knowledge 的方向一致,但企业侧还可叠加领域微调——二者是模块组合,非互斥替换。
怎么做#
domain_finetuned_llm + fresh_index(query) → grounded_answer
上线前用固定评测集对比:仅微调、仅 RAG、微调+RAG 三臂。
常见误区#
- 把微调当作「一次训练永久正确」。
- 在 regulated 场景用微调替代可审计的 citation 链。
框架 POC 与企业软件:两条速度曲线#
为什么#
企业 builder 常用 LangChain 等快速搭 demo;访谈称框架版本漂移使 POC→生产 困难(演讲者观点)。Bob 补充企业里长期存在「阻止你做某事的人」与「做新东西的人」——下文聚焦 builder,不代表治理侧多余(演讲者观点)。
机制与约束#
Saurabh 归纳:框架「擅长 tinkering,不一定是 production-level software」(演讲者观点)。可核对事实:LangChain 仓库存在且活跃;对 POC→生产难度的评价无第三方 benchmark。
RAM 侧对照:内置 automated / user-driven evaluations、plugin 式集成(Features List)——属产品承诺,非 LangChain 替代品的客观排名。
怎么做#
POC 阶段就记录:依赖版本锁、检索指标、合规检查清单;生产迁移时优先换可运维边界(索引服务、eval 流水线、权限中间件),而非逐行搬运 notebook。
常见误区#
- 把 demo 延迟当作生产 SLA。
- 忽视「成功者一只手数得过来」与展会密度之间的反差(演讲者观点)。

权限、合规与 Agent:RBAC 并未换新范式#
为什么#
AI 没有减轻「数据难」:治理、隐私 rigor 未放松(演讲者观点)。regulated 行业仍质疑把数据送进 OpenAI/Anthropic 的 prompt(演讲者观点)。
机制与约束#
Bob 以 Weaviate Query Agent 讨论:对 agent 而言传统 RBAC「基本未变」(演讲者观点)。可核对:Weaviate RBAC 定义 roles → permissions → resources(collections、tenants 等);Query Agent 为 Cloud 上自然语言查询服务,文档未写「Agent 不改变安全范式」——该句保留为访谈判断,与 RBAC 机制相容但不等同官方表述。
Saurabh 同意:数据与安全 overlay 仍是老问题;AI 只是新入口。
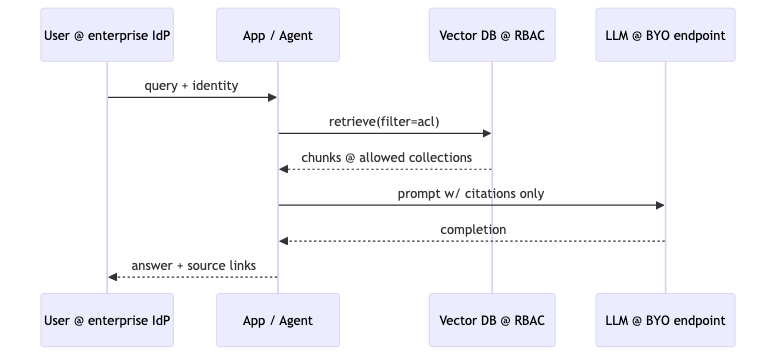
怎么做#
检索前硬过滤 collection / tenant;LLM 调用走企业批准的 endpoint;日志中分离 prompt 内容 与 审计元数据 的保留策略。
常见误区#
- 认为「Agent 自主」即可绕过内容 ACL。
- 在多租户向量库只做应用层 filter,不同步权限撤销事件。


准确度契约:chat、eval 与 citation#
为什么#
RAG 场景下,用准确度交换业务价值,无法要求 100% 准确(Bob,演讲者观点)。LLM 在 workflow 内引入不可完全消除的非确定性(Saurabh,演讲者观点)。
机制与约束#
缓解路径(产品层,部分可核对):
| 手段 | 文档支持 | 访谈补充 |
|---|---|---|
| 自动化 / 用户驱动 eval | Features List:optimal configuration | champion–challenger 多路嵌入管道(术语未出现在官网) |
| citation | Auto-generates citations linking answers to source documents | 点击 citation 滚动至 PDF 段落(UI 细节未在文档验证) |
| HITL | human-in-the-loop oversight | mission-critical 分岔(演讲者观点) |
官网营销句 Improve content accuracy by up to 40% 未给出基线、数据集与 metric——不可与 MRR、pass@k 等学术指标对齐。
怎么做#
offline: golden_qa → score(retrieval, answer, citation_match)
online: thumbs + sample human audit → champion config promotion
常见误区#
- 用聊天「感觉对」代替 citation 是否覆盖关键句。
- 把 40% 提升当作可复现实验结论。
Agent 边界:自治、人在回路与确定性混合#
为什么#
自治(autonomy) 被视作 agent 关键特征;mission-critical 场景下,完全自治与企业可接受风险冲突(演讲者观点)。自主 agent 的障碍大于 chat RAG:前者要求系统替人决策,后者允许人读完后行动(演讲者观点)。
机制与约束#
可并存模式(Saurabh,演讲者观点):
- Human-in-the-loop agent:执行到关键步骤暂停待批。
- 混合工作流:规则 / 传统 ML 处理裁决点,RAG/LLM 处理文书、摘要等非裁决环节(房贷类示例)。
Bob 侧 Query Agent 代表「自然语言 → 自主检索」;企业若上自治编排,仍需在策略层定义工具白名单与副作用上限。
怎么做#
为每个 agent 能力标注 autonomy_level(read-only / draft / execute-with-approval)并在编排器强制执行。
常见误区#
- 「上了 RAG 就能上 autonomous agent」的线性假设。
- 用单一聊天界面承载高后果操作且无审批链。
RAM 与向量库:开放栈里的首选集成#
为什么#
企业需要 BYO LLM / BYO 向量库;但若一切皆可选,决策成本爆炸(演讲者观点)。合理解法是 开放架构 + first-class integration。
机制与约束#
可核对(RAM Features List):
- 向量库:PGVector 与 Weaviate 并列集成;plugin-based integrations、no vendor lock-in。
- LLM:OpenAI、Azure OpenAI、Amazon Bedrock、Ollama 等。
- citation、evaluation、ONNX / quantization 与 diverse hardware。
访谈独有 / 待官方确认:多嵌入模型、将支持 BYO embedding、显式 champion–challenger 流程;「RAM 已 GA」——产品页有 Get started today,抓取文本中未出现 GA 字样,宜写「已公开发布 / 可采购」。
Bob:Weaviate Python client(文档,PyPI weaviate-client,v4 默认 gRPC)更像 library 而非传统 DB driver(演讲者观点)——心智模型差异,非 API 规范术语。SAS 栈 Python 后端、React 前端、公司内亦有 Go(演讲者观点,RAM 实现语言未在官网证实)。
访谈称 RAM 可在无 GPU 基础设施上通过架构选择加速(演讲者观点);官网只写硬件多样性与 ONNX,未声明「无需 GPU」。
怎么做#
# 概念:RAM 编排层 + Weaviate 作向量后端(伪代码)
import weaviate
client = weaviate.connect_to_local() # 或 Cloud;见官方 quickstart
# ingest / hybrid_search / tenant 配置按 RBAC 与 schema 文档实施
选型时并行 PoC:同一 corpus 下对比 Weaviate 与 PGVector 的 hybrid、多租户、运维成本——勿仅凭品牌合作叙事拍板(SAS×Weaviate 合作动机来自访谈,官网未记载选型过程)。
常见误区#
- 把「first-class」理解成「唯一绑定」——文档并列 PGVector。
- 忽视 gRPC 50051 等网络策略(见 Python 客户端文档)。


成熟度、TCO 与采购对话#
为什么#
Builder 关注嵌入模型与框架;客户 demo 优先问部署成本与 TCO(演讲者观点)——关注点错位会直接导致 POC 无法立项。
机制与约束#
Bob 类比 AI 企业落地可能比从业者想象的更早还要早——像互联网早于 Google/Amazon 上市(演讲者观点,未与渗透率数据对应)。Saurabh 类比零售被线上替代前夕:无人能预测破坏力,且 B2C 采用速度使组织难以吸收「其实还早」(演讲者观点)。
RAM 入口重定向至产品页;FAQ 行业含 banking, insurance, manufacturing, health care, public sector——与访谈行业列举一致。GA 时间点、roadmap 细节以 SAS 发布说明为准。
怎么做#
商务材料准备:索引规模 → 存储与重嵌成本、查询 QPS → 向量库节点、合规 → 数据驻留与 LLM 路由,与技术指标并列。
常见误区#
- 只展示「更聪明的回答」,不展示 $/1M tokens 与 重索引周期。
- 用 consumer ChatGPT 体验推导 enterprise SLA。


若你要落地#
- 先钉清「RAG」边界:验收 ingest(分块、嵌入版本、ACL)与 query(recall、citation)分开,再谈 Agent 自治级别。
- 向量库 PoC 用同一 corpus:对照 Weaviate 与 PGVector 的 hybrid、租户与运维;RAM 仅作参考集成列表,不替代你自己的 SLA。
- 把 RBAC 放在检索之前:对齐 Weaviate RBAC 或等价模型;regulated 场景单独评审 LLM 出站数据流。
- 用 eval + citation 建信任链:offline golden set 驱动配置晋升;线上 citation 至少到文档级,段落级滚动需在产品中实测。
- 高后果场景默认 HITL 或规则裁决:LLM 负责文书与摘要,不把信贷、安全等裁决点交给端到端自治(演讲者观点,与 RAM HITL 营销方向一致)。
参考与延伸阅读#
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(arXiv:2005.11401)
- RAG 论文 PDF
- SAS Retrieval Agent Manager 产品页
- RAM Features List(Weaviate / PGVector、eval、citation、LLM 集成)
- SAS 预测性维护为何不止检索(制造 + RAG 叙事)
- Weaviate 开发者文档入口
- Weaviate 文档 llms.txt(Query Agent、hybrid search 等索引)
- Weaviate 概念:Data structure 与 vector / embedding
- Weaviate Python 客户端(weaviate-client、gRPC)
- Weaviate RBAC 概述
- Weaviate Query Agent 概述
- LangChain GitHub 仓库
- SAS Viya 平台页(模型治理与部署生态,非 RAM 架构白皮书)
- SAS 产品文档入口
- ONNX 项目主页(RAM 加速相关技术背景)


