
从 RAG 到 Search Agent:检索、合成数据与评测的三条张力#
大模型产品把「联网搜索」做成默认能力之后,工程团队常面临同一组矛盾:用户要的是短答案还是长报告?训练预算是烧在 LLM token 还是 search API 次数?评测该看答对率还是看轨迹效率?本文围绕 search agent(以 search / browse 工具 在互联网上为多跳 web 问题找答案)这一工作定义,对照 BrowseComp-Plus 等公开基准、合成数据路线 WebShaper,以及嘉宾 Nandan Thakur(BEIR / MIRACL 合著者)在访谈中的工程判断——不强行收束为单一结论;凡未在论文或 leaderboard 中出现的数字,均标为演讲者观点或未核实。
问题空间:三条轴,而不是一个「更聪明的 RAG」#
经典 RAG 往往是「检索一次 → 拼进 prompt → 生成」。Agentic search 把检索变成多轮、可分支的过程:模型决定何时搜、搜什么、是否继续读文档。公开文献里,BrowseComp-Plus 将 Deep-Research agents 操作化为:LLM + search tools,在固定语料上测 Accuracy 与 Search Calls。
与此同时,工业界还有 deep research 产品叙事——用户常期待报告式输出、任意工具编排、更长的 test-time compute。嘉宾的划分是:search agent 锚定「答一问」;deep research 是更宽的伞(演讲者观点)。两条产品线可以共享底层检索,但优化目标与 harness 并不相同。

Search agent 与 Deep research:命名即产品预期#
为什么:同一套「会搜网的模型」,若对外称 deep research,用户会预设长文档、多工具、可下载报告;若称 search agent,更接近 web QA / BrowseComp 族(演讲者观点)。
机制/约束:BrowseComp-Plus 在约 100K 固定文档上评测,便于复现检索栈(BM25、DiskANN 稠密索引等),与「实时全网 API」的商用 agent 不可直接数值对比。
怎么做(心智模型):把 harness 拆成 plan → search → read → answer;先明确交付物是 span 级短答案 还是 nugget 级长答案(后者接近 TREC RAG 的 nugget / support 评测)。
常见误区:用报告类产品的 UX 去评 BrowseComp 式短答案任务,或用一次 RAG 的延迟 SLA 去卡多轮 agent。
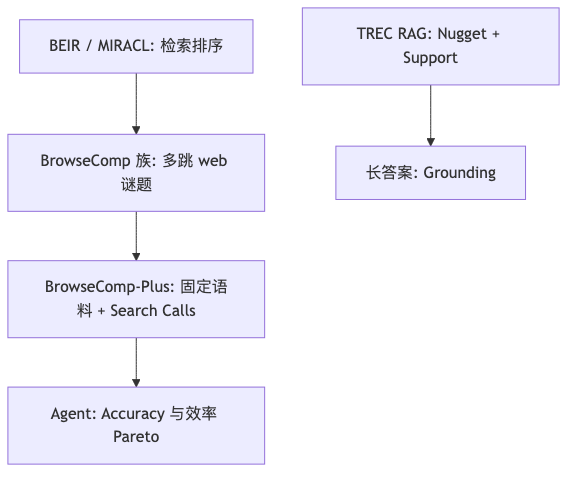
评测谱系:从 BEIR 到 BrowseComp+#
为什么:BEIR 推动社区在 18 个零样本数据集上迭代检索器;MIRACL 把异构语言纳入同一套 qrel 思维。Search agent 需要类似「社区围着 benchmark 转」的拉力,但 IR 指标与 agent 指标不是同一随机过程(演讲者观点)。
机制/约束:
| 层级 | 典型指标 | 稳定性(文献/常识) |
|---|---|---|
| 检索器 | NDCG@k、MRR | 固定 qrel 重跑,方差极小 |
| Agent 端到端 | Accuracy、Search Calls | 同模型多 rollout 方差大 |
| 长报告 RAG | Nugget recall、Support 0–2 | 与 BrowseComp Accuracy 不同族 |
BrowseComp-Plus 论文报告:GPT-5 + BM25 55.9%,换 Qwen3-Embedding-8B 约 70.1%;项目页脚注中 GPT-5 + Google Search API 约 59.9%。嘉宾口述「头部模型已达 90–95%」与上述 2025-08 公开表不一致——可能指另一基准、私有榜或未核对的 BrowseComp(非 Plus)设置;正文不得以口述替代 leaderboard。
嘉宾用 filter / funnel 理解 BrowseComp+ 子句:多候选约束逐条收窄(演讲者观点);论文侧有 human-verified supporting docs + mined negatives、GPT-4o sub-query 分解管线,方向一致,但 10³–10⁵ → 个位数 的数量级未在论文中逐字出现。
怎么做:在固定语料上复现 BrowseComp-Plus + Tevatron 再谈「换检索器是否涨点」;商用 API 轨迹另建私有 eval。
常见误区:把 BEIR 上的 NDCG 提升直接等同于 BrowseComp 上 Accuracy 提升;Search-R1 + BM25 在 BrowseComp-Plus 仅约 3.86% 说明「关键词化查询即可」在该难基准上尚未成立。

合成数据:Orbit、WebShaper 与「链式」多跳#
为什么:Search-R1 等在 NQ、HotpotQA 上训练时,任务难度与 BrowseComp 族错位;不少数据集论文不释出训练数据(演讲者观点)。合成管线试图用 seed → 检索 → 抽事实 → 隐藏 → 再检索 的 intersection 思路造难例。
机制/约束:
- WebShaper(可核对):formalization-driven,Knowledge Projections + agentic Expander;数据集 WebShaperQA。
- Orbit(未核实):嘉宾描述约 20k BrowseComp-风格 四至五层 riddle、DeepSeek 生成 + 自验证 + 外部 search agent 验证、消费级笔记本连续跑数月(演讲者观点)。公开检索未发现署名 Orbit 的论文/仓库;在发布前应视为项目口述。
- 难度对比(演讲者观点):BrowseComp+ 偏 filter(子句多候选、逐条漏斗);Orbit 更接近 A→B→C→D 链式,自认尚未达到 Plus 的 filter 强度。
怎么做(极简管线):
seed_entity → web_search → extract_facts → mask_entity → repeat → QA_pair
质量门禁:每跳用独立检索结果校验可解性,而非仅信任 LLM 自洽。
常见误区:合成题允许模型只解开一条线索就猜答案(嘉宾举 Emoji Movie 类捷径,演讲者观点);理想 agent 应 todo-list 式逐条验证 约束。
训练经济学:GRPO、rollout 与「Search 比 LLM 贵」#
为什么:Search-R1 用 outcome-based reward 与 retrieved token masking,在 7 个 QA 集上让小模型相对 naive RAG 有约 +41% / +20%(Qwen2.5-7B/3B,论文表)。下一步竞争点常被表述为:同等 Accuracy 下更少的 token 与 search 调用(演讲者观点)。
机制/约束:
- GRPO(DeepSeekMath):每题采样 G 条输出,用组内归一化 reward 算 advantage;G 是超参,论文未写死 8。训练时「多条轨迹中少数成功即可产生正 advantage」与嘉宾「8 条里 1 条对就有信号」机制相容,但勿把训练 group size G 与推理 pass@k 混为一符号。
- API 账单(演讲者观点):若
6 turns × 8 rollouts × 1 search/turn,心算约 48 次 search / 训练样本;BrowseComp-Plus 论文称强模型平均每题 >20 次 search。Search 按次计费、LLM 按 token 计费时,agent 训练下 search 账单可高于 LLM——与「token 越来越便宜」的直觉相反。 - 顺序长视界 vs 并行:推理侧 pass@K 可行;训练侧跨 rollout 传信用 RL 太贵,常见路径是 强教师 rollout → SFT 蒸馏(演讲者观点)。
- Context rot:Chroma 研究报告 在控制难度下显示输入变长则性能下降;与「评测保留全轨迹」和「工程压缩上下文」形成张力。
怎么做:先用 Search-R1 代码库 的 PPO/GRPO/reinforce 开关在小语料验证,再放大 G 与 turn 数;单独记录 search_calls 与 tokens 两列成本。
常见误区:把 GRPO 的 G 直接写成 pass@8;在 BrowseComp+ 轨迹里重复提交同一 query仍算有效探索(嘉宾批评为浪费,演讲者观点)。


检索接口:Snippet、全文与自托管栈#
为什么:商用 search API 多返回 snippet + offset,类似经典 reader 的 span;自托管 BM25 / ANN 在十亿级语料可起步,但 agent 有时需要 snippet 级可复现 或全文工具(演讲者观点)。
机制/约束:嘉宾倾向 search → 选 doc → document tool 拉全文 的两段式;训练时因 API 慢/贵未充分做端到端全文 RL(演讲者观点)。学术替代路径包括 FineWeb / ClueWeb 建索引 + 内部 search API;BrowseComp-Plus 与 Tevatron 提供可复现 BM25/稠密检索。「Deep Research Gym」专名在公开 URL 核实中未找到独立项目页(2026-05 核实),写作时宜指 Tevatron/BrowseComp-Plus 生态或标注未核实。
嘉宾猜想(无实验数字):经 SFT/RL 优化后,agent 或只需输出 BM25 关键词 配合 lexical retriever——在 BrowseComp-Plus 上尚未被公开结果支持,保留为研究假设。
怎么做:
# 概念 harness(非生产代码)
for turn in range(max_turns):
q = llm.plan_query(state)
hits = retriever.search(q, top_k=10) # snippet + doc_id
if need_full_text(hits):
doc = corpus.fetch_full(hits[0].doc_id)
state = llm.update(state, hits, doc)
answer = llm.finalize(state)
常见误区:用单次向量 top-k 替代多轮 search;忽略 REPLUG 时代「检索与 LM 分工」在 agent 里以 摘要/外部文件夹记忆(如 Claude Code 式)重现,而非唯一解是 Databricks 式「压缩与检索联合端到端训练」(主持人转述,官方 benchmark 页 2026-05 未核对到)。


Harness:记忆、压缩与评测闭环#
为什么:多轮搜索使上下文长度成为第二瓶颈;三四年前 RAG 主题的 prepend 检索文档(REPLUG)、chunk 裁剪、nugget 报告评测,在 agent harness 里再次出现(演讲者观点)。
机制/约束:
- 模块化:先 search,再按需 full-document tool;与「检索 agent + 压缩器联合端到端训练」路线并存,嘉宾个人更偏模块化(演讲者观点)。
- TREC RAG(可核对):2024 指南含 Nugget、Support、Fluency、Retrieval 四指标;Support 0–2 评 grounding。嘉宾判断「流畅度权重下降、更应看 grounding」属参与者观点。
- 工具使用门槛:约半年前仍需 SFT+RL 才稳 tool use;现 mid/post-training 已蒸馏进大模型,竞赛转向 效率与 Pareto(演讲者观点,时间锚为录制前后口语)。
常见误区:为压长度删掉对评测可审计的 citation 轨迹;把 IR 的「单次确定性排序」心智套在 stochastic rollout 上。

未收敛的结论(刻意并列)#
- 任务定义:BrowseComp-Plus 论文的 Deep-Research agent 操作性定义与嘉宾的「search agent ⊂ deep research 伞」可并存;产品命名仍影响用户预期(演讲者观点)。
- 数据:WebShaper 已发表;Orbit 规模与管线待公开核实。
- SOTA:公开 BrowseComp-Plus ≤70.1%(固定语料设置)与嘉宾 90–95% 口述冲突——正文只能并列,不能合并。
- 训练:GRPO 组内相对奖励支持「稀疏成功」;48 次 API/样本 为 lab 心算,非定理。
- 下一步 benchmark(演讲者观点):多语言/多模态 riddle、FreshStack / CRAG 族加 agentic search、更难 filter——与 Omar Khattab「需要更难 benchmark」一类判断同向,具体指标未在播客展开。
若你要落地#
- 先钉交付物与评测族:短答案走 BrowseComp-Plus 式 Accuracy + Search Calls;长报告走 TREC nugget/support,勿混表。
- 成本账本拆两列:
search_calls与llm_tokens分开记账;训练前用 small G、小 turn 做预算仿真(GRPO 的 G 见 DeepSeekMath)。 - 合成数据加硬门禁:每跳外部检索校验 + 反捷径规则(禁止单线索猜答案),参考 WebShaper 的 agentic Expander 思路。
- 检索栈可复现优先:能在 BrowseComp-Plus 固定语料 上复现再换商用 API;需要全文时显式加
fetch_full(doc_id)工具,而非假设 snippet 够训。 - 上下文策略与评测一致:若评测要完整轨迹,训练可另做压缩/distillation;关注 context rot 文献对长度–准确率权衡的实证。
参考与延伸阅读#
- BEIR:零样本信息检索基准
- MIRACL:多语言检索基准
- Search-R1:强化学习 + 多轮搜索
- Search-R1 官方实现与实验日志
- DeepSeekMath:GRPO 算法定义
- BrowseComp-Plus 论文
- BrowseComp-Plus 项目页与结果表
- BrowseComp-Plus 代码与 Tevatron 检索栈
- OpenAI BrowseComp 数据集(Hugging Face)
- WebShaper:形式化驱动的 web agent 数据合成
- REPLUG:可微调检索 + 冻结 LM
- TREC RAG Track 首页
- TREC 2024 RAG 评测说明(nugget / support / fluency)
- Chroma:Context Rot 研究报告
- Meta CRAG 综合 RAG 基准仓库


