
语义查询引擎:当 LLM 算子进入查询优化器#
RAG 与 Agent 把「检索 + 生成」推成默认架构,但生产管道里仍大量存在 批式分析:对百万行图文音做 filter、join、map,再与关系算子混写。传统 TPC-H / TPC-DS 几乎不含长文本与多模态字段;Spider、BIRD 等 text-to-SQL 基准也缺少 search / 语义算子 维度。MIT 博士生 Matthew Russo 参与 SemBench 与 Palimpzest / Abacus 等工作,主张把 foundation model 上的 semantic filter / join / classify / map / rank 当作一等查询算子,由 logical / physical plan 与 代价–质量 优化器统一调度——这与「每个步骤手写 Python + 调模型」的脚本式 RAG 不是同一条路。
下文按问题空间、算子本体、执行与优化、基准与落地边界组织;表达力可互写 与 优化器可重写 并不等价;访谈中的产品对比、工业 bear case、具体美元数字在无法核对处会单独标注。
问题空间:从 ML UDF 到语义算子#
为什么:关系型 WHERE 无法表达「图像路径指向红车」「合同条款是否含竞业限制」;历史上 BigQuery ML 等路线把预测函数嵌进 SQL,但泛化依赖特征工程。Foundation model 的 zero-shot 能力使 谓词与变换 可直接写在查询里(演讲者观点)。
机制/约束:一旦管道含 LLM 或 vision 调用,延迟与美元成本 常压倒传统 join 与索引扫描——向量检索约毫秒级、单次 LLM 调用可达秒级是常见经验量级(演讲者观点;具体比例随模型与 batch 而变)。优化目标从「最小化 I/O」转向 cost–quality–latency 三维,且 quality 往往只能采样估计。
怎么做(概念):把用户意图编译为带语义算子的计划,而非在应用层逐行 apply():
# 概念示意:声明式语义 filter(非某系统完整 API)
plan = (
scan("papers")
.semantic_filter("abstract mentions retrieval-augmented generation")
.semantic_map("extract first author name")
)
# 优化器可选:先 filter 再 map、选 Flash vs GPT、RAG 预筛等
常见误区:把「语义查询引擎」等同于 text-to-SQL Agent。Weaviate Query Agent 侧重自然语言问答与 filter 生成;Transformation Agent 用 append_property / update_property 物化新列 回 collection——接近 semantic map/classify,但中间结果默认持久化。Palimpzest 类引擎强调 on-the-fly 计算、不必写回库(架构对比为演讲者观点)。另一条误区是把 向量库 当作完整语义 QP:ANN 解决相似度检索子问题,不自动提供跨表 semantic join 的物理计划选择,也不替代 filter pushdown 与 模型级实现规则。
算子本体:五类 taxonomy 与 map 万能论#
为什么:SemBench 将核心算子规范为 filter, join, classify, map, rank(论文写作 filters, joins, mappings, classification, ranking),以便横向比较 LOTUS、ThalamusDB、Palimpzest、BigQuery 等各自不同的 API 表面(已核验:arXiv:2511.01716 摘要与 README 表头)。
机制/约束:存在「semantic map 万能论」:filter(二元谓词)、classify、rank 理论上都可写成 map(rank 在全表排序时更接近 aggregate)。Russo 的立场是:表达力等价 ≠ 优化等价——只有 filter 天然适合 Oracle + proxy 式近似查询处理(AQP):proxy 与 Oracle 对同一行可判定「同意/不同意」,高/低置信区间可跳过昂贵 Oracle(演讲者观点;与 LOTUS cascade 中 learn_filter_cascade_thresholds 及 gold algorithm 术语方向一致,已部分核验)。semantic map(如生成摘要)难以用二元一致性做同样阈值带(演讲者观点)。
怎么做(互写 vs 优化):若仅需表达力,可用 map 模拟 filter:map("does image show red car? yes/no") 再关系过滤;若需 cascade,应保留独立 semantic_filter 算子类型,让优化器学习 proxy 阈值(LOTUS)或黑盒实现(Palimpzest)。semantic rank 在 SemBench 中单独成类,全表排序时更接近 aggregate + order,不宜强行并入 map(taxonomy 设计动机;已核验 README 分列 Rank)。
常见误区:在 benchmark 设计里用开放式摘要作 ground truth——SemBench 倾向 刚性字段抽取(如论文作者名),开放生成评测仍属边界未闭合问题(演讲者观点)。
执行模型:急切 DataFrame 与惰性 SQL 计划#
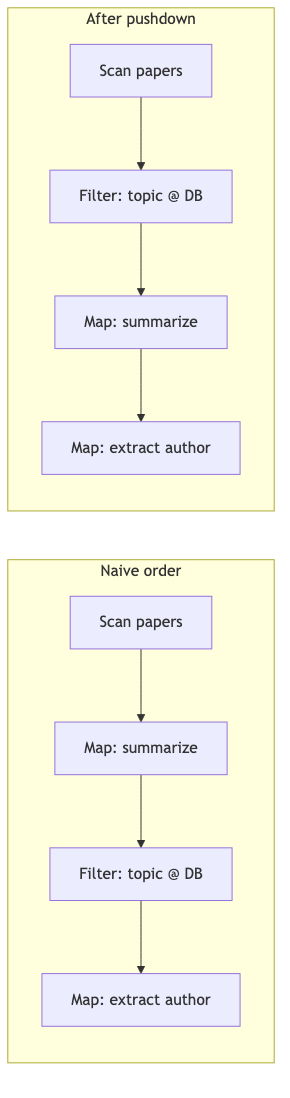
为什么:算子顺序决定 调用次数(尤其 filter 与 map 的 reorder)及 能否 pushdown。
机制/约束:
| 路径 | 典型行为 | 优化空间(文献/代码) |
|---|---|---|
LOTUS DataFrame sem_* | 逐算子 materialize(演讲者观点) | LazyFrame + optimize() 支持 cascade / predicate pushdown(部分核验) |
| Palimpzest / ThalamusDB / BigQuery | 整查询提交 → logical reorder + implementation rules | Abacus:transformation rules + implementation rules(如 PushDownFilter、EmbeddingJoinRule) |
怎么做(计划示意):扫描论文表 → 按主题 semantic filter → 两次 semantic map 时,应先 filter 再 map,避免对全文跑昂贵 map(Abacus 论文案例;已核验 存在 filter pushdown 规则)。
ThalamusDB 补充:ThalamusDB 自述 approximate query processing 引擎,与 LOTUS 的 cascade 是否同构 未在 README 中核验到 proxy/oracle 三元结构——嘉宾「可能类似」仍应标为 访谈观点。
常见误区:认为有了向量库就自动获得 查询级 优化。ANN 解决的是检索子问题;语义 join 两侧若仍走 nested-loop LLM,复杂度仍可达 N×M(Palimpzest NestedLoopsJoin 对左右候选双重循环,已核验)。另:LOTUS 已有 LazyFrame 时,「DataFrame 完全无法 reorder」应弱化为 默认急切 API vs 显式 optimize() 的对比(部分核验)。

语义 join:学术 bull case 与工业 bear case#
为什么:传统分析型 workload 里 join reorder 与物理实现选择曾是核心;语义 join 若同样主导美元账单,优化器值得投入(演讲者观点)。
机制/约束:
- Bull:含多模态 join 的查询里,实现选择可导致数量级费用差——嘉宾口述修订案例:约 12,000 张图、总费用 约 $2–$27、embedding join 显著便宜于逐张 vision LLM(访谈观点;公开 Abacus 论文与仓库 未核验到 12k 与 $2–$27 同数,MMQA 在 SemBench 规模为 1,000 图)。
- Bear:真实 workload 难举大量刚需 multimodal join;更常见是两侧 semantic map 抽实体 + 关系 join。动物场景上 map 出
elephant与North African elephant后字符串 join 失败(演讲者一手尝试;未给出 定量失败率)。 - 向量检索 vs 语义 join:约会匹配等「找相似 profile」更像 vector search,不必上升为声明式 join 算子(讨论性观点)。
EmbeddingJoin 先用样本 LLM 标定 min_matching_sim / max_non_matching_sim,相似度落在中间带才调用 LLM——与 filter 的「两阈值 + 中间带」同族(已部分核验)。
常见误区:把所有「跨集合匹配」都建模为 semantic join。Many-to-many 文本对齐在工业界常被 map + equi-join 替代,且 map 抽取质量不稳定。
优化器哲学:固定 Oracle vs 黑盒实现空间#
为什么:用户不应手写每步的模型名、temperature、ensemble 与 RAG 的 K。
机制/约束:
| 流派 | 优化变量 | 代表机制 |
|---|---|---|
| LOTUS 式(嘉宾概括) | 在 固定 gold / Oracle 下用 proxy 降本 | Cascade 阈值;论文强调相对 gold 的 accuracy guarantee(DOI 10.14778/3749646.3749685) |
| Abacus / Palimpzest 式 | 实现为 黑盒,采样估 cost / quality / latency | Pareto-Cascades、OptimizationStrategyType.PARETO、sample budget(论文示例约束 spend less than $1) |
Palimpzest 对 map/filter 的 implementation rules 包括:model selection、MixtureOfAgents*、CritiqueAndRefine*、RAGRule(上下文削减 + 检索)、k_budgets = [1,3,5,10,15,20,25] 等(已部分核验 rules.py)。语义 filter 可实现为单次 LLM、RAG → top-K → LLM,或由 agent 生成 Python / regex 一次编写再批量执行(演讲者观点,Palimpzest 设计哲学)。
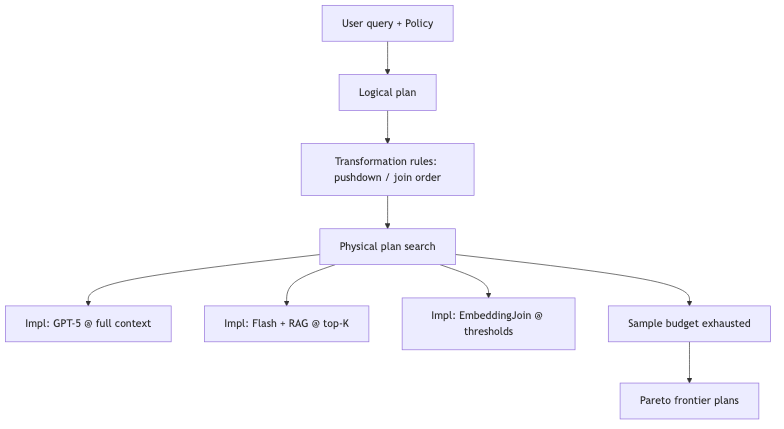
常见误区:把论文里的 $1 采样预算 理解成「每行 10¢」——公开 Policy 为 MaxQualityAtFixedCost(cost_budget) 等 计划级 约束(已核验);per-row 10¢ 在已读文档中 未出现。
SemBench:共同任务比排行榜名次更重要#
为什么:没有共享 workload,「语义查询引擎」无法像 TPC 时代那样积累可复现的工程知识。
机制/约束(对照 SemBench README,已核验):
| 场景(正式名) | 查询数 | 模态 |
|---|---|---|
| Movie | 10 | 表 + 文 |
| Animals(口语 wildlife) | 10 | 表 + 图 + 音 |
| E-Commerce | 14 | 表 + 文 + 图 |
| MMQA | 11 | 表 + 文 + 图 |
| Cars(嘉宾口语 medical) | 10 | 表 + 文 + 图 + 音 |
| 合计 | 55 | 四模态均有 |
算子列仅有 Filter / Join / Map / Rank / Classify,尚无 semantic group-by / aggregate workload(已核验 表头无 GroupBy 列)。已评测系统:LOTUS、Palimpzest、ThalamusDB、BigQuery;README 指向 在线排行榜(本次环境 TLS 未能打开页面,榜单内容未独立核对)。
评测哲学(演讲者观点):早期 相对名次不如建立共同任务重要;prompt 敏感导致方差大。Ground truth 多来自 Kaggle 标签 + 合成列(如动物 location);合成 filter 与 embedding 可能 相关(主持人以 Weaviate mod 10 合成 filter 经验类比)——benchmark 构造仍是开放问题。Abacus 论文在 CUAD 法律合同域报告相对次优系统 quality +6.7%–39.4%、10.8× cheaper、3.4× faster(已核验 摘要级数字;具体曲线需查正文表)。指标上 SemBench README 侧重 F1 / precision / recall / relative error,与生成任务的 pass@k 不是同一套口径——跨文献对比时需对齐 evaluator。
semantic GROUP BY:嵌入 → 聚类 → 簇摘要,嘉宾倾向归为 semantic GROUP BY(聚合本身也是语义),而非 join;与 Transformation Agent 物化属性形成对照(演讲者观点)。
混合查询与 deep research:尚未闭合的边界#
为什么:真实系统常把 ClickHouse 式关系过滤与语义算子串在同一管道。
机制/约束:当前多数 workload 下 只优化语义段 即可获得主要收益,因语义算子数量级更慢(演讲者观点)。反例:关系侧过滤到极少行后,语义调用次数很少时,关系引擎优化 与 Palimpzest 未专门优化关系段(嘉宾自述)会变得重要——Palimpzest 关系侧优化边界 未验证。
Deep research(高层意图 → 系统自规划)与声明式 semantic QP 重叠程度待定(演讲者观点)。若未来 万级 filter 可并行 且 API rate limit 放松,瓶颈可能在关系与语义算子之间转移(嘉宾推测,未验证)。vLLM 自管权重:LOTUS 经 LiteLLM 可接 vLLM endpoint,但优化器是否利用自管权重降本——嘉宾称 Palimpzest 侧 非常基础、仍以 API 为主(访谈观点)。
怎么做(混合管道):关系引擎先做选择性极高的 WHERE / partition prune,再把 百行级 子集交给语义算子;在 Palimpzest 未优化关系段时,这一步往往要在外部完成,而非指望单一框架自动下推(演讲者观点 + Palimpzest 边界 未验证)。
若你要落地#
- 先固定算子语义与评测字段:开放摘要难评测;优先刚性抽取 + 可复现 F1 / relative error(SemBench README 方向),再谈复杂 map。
- 把 filter 与 map 分开建模:若需要 cascade / AQP,filter 类二值谓词与 map 的优化路径不同;勿因「map 能写出来」就合并算子类型。
- 用 SemBench 或自有 workload 量「计划级」美元:对照 sembench.org 与 Palimpzest
Policy,在 join 上显式比较NestedLoopsJoinvsEmbeddingJoin,勿假设向量库已优化 join。 - Agent 物化 vs 查询内计算:需要多次复用的 enrich 列适合 Transformation Agent;一次性分析管道可评估 Palimpzest / LOTUS LazyFrame,避免中间结果写爆存储。
- 对访谈数字保持审计:12k 图、$2–$27、排行榜名次结论等,写作与采购决策前应回查论文修订与复现实验。
参考与延伸阅读#
- SemBench 论文(arXiv:2511.01716)
- SemBench GitHub 与 workload 表
- SemBench 在线排行榜(README 链接)
- Abacus 论文(arXiv:2505.14661)
- Abacus PVLDB 条目
- Palimpzest GitHub
- Palimpzest 文档站
- LOTUS GitHub
- LOTUS 语义算子优化(arXiv:2407.11418)
- LOTUS cascade 优化(VLDB 2025)
- ThalamusDB 项目站
- Weaviate Query Agent 用法
- Weaviate Transformation Agent 用法
- RAG 综述(Lewis et al., 2020)
- TPC-H 规范入口


