
充分上下文:RAG 该测「够不够答」,而不只是「像不像相关」#
RAG 管线里,检索器把若干 chunk 拼进 prompt,生成模型再作答。工程上常把失败归咎于「没召回到」或「模型胡说」;评测侧则大量依赖 RAGAS 一类 relevance、faithfulness 指标。UC San Diego 与 Google 等合作者在 Sufficient Context: A New Lens on Retrieval Augmented Generation Systems(正文标注 Published as a conference paper at ICLR 2025)中提出:给定当前 context,模型是否应当能答这道题——与「片段与 query 多相关」不是同一维度。下文把论文可核对结论与访谈中的工程推断分开标注;数字优先对齐 Table 1 / Figure 2 / Figure 4 / Figure 6。

问题空间:检索质量、上下文充足性与拒答#
| 关切 | 常见做法 | 本文强调的缺口 |
|---|---|---|
| 检索排名 | nDCG@k、向量相似度 | 高相关 ≠ 信息够答题 |
| 生成忠实度 | RAGAS faithfulness | 忠实于错误前提的 context 仍可能答错 |
| 拒答 / 选择性生成 | 固定阈值、仅模型自评 | 单独用「不充分」门控会砍掉大量「不充分却答对」样本 |
生产日志里,三类失败常叠在一起:召回不足、context 充足但模型不会用(Table 4a:Gemma 在人工标为 sufficient 时仍有约 25.4% 被判为 hallucinate)、context 不充分却靠 parametric knowledge 答对(摘要写明 SOTA 模型在 insufficient context 下仍 35–62% 答对)。若只优化相似度或只训「不知道就说不知道」,容易在错误子集上优化。

充分上下文 vs 相关性:概念与可测边界#
为什么#
RAGAS 提供 context_precision、context_recall、faithfulness、answer_relevancy 等,但没有与论文同名的 sufficient context 二元标签。论文 §3.1 定义:实例 ((Q,C)) 为 sufficient,当且仅当存在 plausible 答案 (A’),使得在 (C) 的信息下 (A’) 能合理回答 (Q);允许多跳推理,不要求事先给出 ground-truth answer。这与 TRUE-NLI 式 entailment(给定答案 (A) 再判蕴含)不同。
机制与约束#
- 概念区分(访谈框架,非形式定理):存在「相关但不充分」;嘉宾认为充分信息应相关,但论文未证明「充分 ⇒ 相关」的偏序。演讲者观点。
- Table 1 中 TRUE-NLI(T5 11B)precision 高、recall 低,与「蕴含 ⇒ sufficient、逆不成立」的叙述一致(文献)。
怎么做(最小示例)#
用 LLM 作二元 autorater(论文 Table 1 用 Gemini 1.5 Pro 0/1-shot;大规模打标用 FLAMe-RM-24B):
Given question Q and retrieved context C only:
Does there exist an answer A' that Q can be reasonably answered from C alone?
Reply: sufficient | insufficient
勿把「C 是否包含 GT 字符串」当作唯一规则:论文 Contains GT 准确率 0.809,仍低于 Gemini 1-shot 0.930(Table 1)。
常见误区#
- 用 embedding 相似度阈值替代 sufficiency 标注。
- 把 RAGAS
context_precision当作「够不够答」的代理指标。
金标 autorater 与主实验数据集#
为什么#
要评「autorater 是否可靠」,需要小规模人工金标,再在大规模检索 context 上分析模型行为。
机制与约束#
- 金标集(§3.2):115 条 ((query, context)),专家标 sufficient / insufficient;来源为 PopQA、FreshQA、Natural Questions、EntityQuestions——并非 HotpotQA / MuSiQue(后者用于 §4 主实验)。访谈若混述数据集名称,以论文为准。
- 主评估(§4.1):FreshQA(True Premise, 452)、Musique-Ans(dev 500)、HotpotQA(dev 500);检索管线为 FlashRAG + REPLUG +
intfloat/e5-base-v2。 - Table 1(金标 115 条):Gemini 1.5 Pro 1-shot F1 0.935 / Acc 0.930;0-shot 0.878 / 0.870;FLAMe-24B 0.892 / 0.878。播客「80–90%」落在区间内但偏保守,宜写 87–93%。
怎么做(最小示例)#
分层统计前先固定 autorater(论文主分析用 Gemini 1-shot),再按 sufficient / insufficient 切分 Correct / Abstain / Hallucinate(LLMEval 语义判对错,非纯字符串匹配;见附录 B.3)。
常见误区#
- 认为金标与 HotpotQA 同分布——115 条与 500 条 dev 分析是两套构造。
- 用含 ground-truth answer 的 prompt 作生产默认(Table 1 显示有提升但仍弱于无答案 Gemini 1-shot)。
不充分仍答对:parametric knowledge 与 RAG 的耦合#
为什么#
若「不充分 ⇒ 应拒答或再检索」,会假设模型不会用预训练知识补洞——论文数据表明该假设不成立。
机制与约束#
- 35–62%(摘要):SOTA LLM 在 insufficient context 下仍输出 correct(文献,§4.3)。
- Table 2 定性:该现象大量来自 closed-book 本就能答对 的题——检索到的片段不够单独答题,但模型靠参数化知识过关。
- 反直觉(文献):在模型无 context 本答不对时,塞入仍不充分的 context,有时反而「解锁」正确答案(访谈强调;机制为开放问题)。
怎么做(最小示例)#
对每条 query 记录四元组:(sufficient_label, rag_context, model_answer, llm_eval_correct),单独汇报 insufficient ∧ correct 占比,勿与全量 accuracy 混报。
常见误区#
- insufficient 占比高就强制二次检索——可能删掉已靠参数化知识答对的样本。
- 把「答对」等同于「忠实使用了 context」。

RAG 损害 abstention:检索越多,越不敢说「不知道」#
为什么#
工程直觉认为 RAG 降低幻觉;论文 §4.2 标题即 Models Abstain Less with RAG:加入 context 后模型更不愿 abstain,在 insufficient 子集上幻觉相对上升。
机制与约束#
- Gemma 2 27B(
gemma-2-27b-it)在 HotpotQA 上(Figure 6,堆叠条解读):Without RAG — Correct 65.2% / Abstain 24.8% / Hallucinate 10.0%;With RAG, insufficient — 37.9% / 11.9% / Hallucinate 50.2%(文献)。 - 播客口述「加检索后幻觉约 66%」在正文图表中无法精确对齐;最接近误读是把 64.1% correct(sufficient + RAG)听成幻觉率。未核实边界:除非有幻灯片,宜采用 Figure 6 数字。
- Claude 等:无 RAG 时 abstain 84.1% → 有 RAG 52%(§4.2,文献)。
怎么做(最小示例)#
对比同一模型三条曲线:no_rag、rag_sufficient、rag_insufficient,分别报 abstain rate 与 hallucinate rate(论文用 LLMEval 管线)。
常见误区#
- 检索命中 GT 片段就认定风险下降——sufficient 子集上 abstain 可升高,insufficient 子集仍可能大量 hallucinate。
- 只训「看到 context 就答」,不训「context 不够要说不知道」。
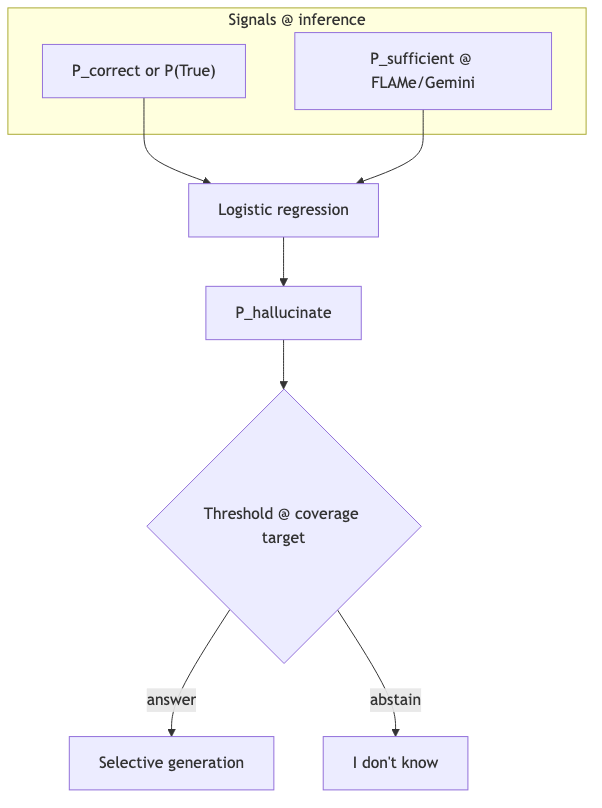
选择性生成:不要单独用 P(sufficient) 当门控#
为什么#
团队曾设想用 sufficient-context rater 决定 abstain;§5.1 写明这种 heavy-handed 做法会 lower overall performance,因砍掉「insufficient 但 correct」样本。
机制与约束#
- P(True):Kadavath et al. — 多次采样再自评(开源模型成本高)。
- P(Correct):直接要「最可能答案 + 概率」(专有模型用,文献 §5.1)。
- Sufficient 信号:二值 autorater(实验用 FLAMe,1600-token chunk;任一块 sufficient 则整体 sufficient)。
- 组合:与自评概率做 logistic regression 预测 hallucination,再阈值化——不是单独 P(sufficient) 门控。
- 增益(相对仅 confidence):HotpotQA 上 Gemma 27B 在 最高准确率区域 >10%;Gemini 1.5 Pro 在约 70% coverage 区域 >5%(文献 Figure 4)。摘要另写在实际作答子集上正确占比提升 2–10%。
- Coverage = 未 abstain 的查询占比;Selective accuracy = 作答子集上的正确率——勿与 recall@k 或 pass@k 混用。
怎么做(最小示例)#
# 概念:离线拟合,线上用同一阈值控制 coverage
# features: [logit_p_correct, logit_p_sufficient, optional_bias]
# label: hallucinate per LLMEval on (Q, C, model_answer)
Musique 上 Gemma 的 sufficient 系数可为 0(增益消失)——组合信号数据集相关(文献)。
常见误区#
P(sufficient) < τ就拒答或触发再检索。- 只报全量 accuracy,不画 coverage–selective accuracy 曲线。
Context 长度、拼接与「工程层」上下文#
为什么#
长上下文窗口普及后,常见论点是「不必 RAG、一次塞全库」。论文 Figure 2 与访谈对此给出部分反证与延伸。
机制与约束#
- 本文实验(Figure 2):检索 context 上限 2000 / 6000 / 10000 tokens;2000→6000 时 sufficient 比例温和变化(如 Musique 33.4% → 44.6%),6000→10000 几乎不变;后文固定 6000 tokens(文献)。
- Lost in the middle:Liu et al., TACL 2024 被引用;本文未报告「金答案在 context 中间 vs 首尾」的对照——播客关于 chunk 拼接、metadata 量、人工标 sufficient 变难等多属 演讲者观点 / 经验延伸。
- 矛盾 evidence:检索片段互相矛盾时,嘉宾倾向标 insufficient;与模型 parametric knowledge 冲突则是另一层(预训练/微调)。演讲者观点。
- Context engineering:在 relevance 之后,如何把碎片组成可用整体(消歧、一致性)——与 Graph RAG、重排并列,非替代召回(演讲者观点)。
怎么做(最小示例)#
在 6k token 预算下做截断实验:比较 sufficient 比例与下游 selective accuracy,而非盲目拉满窗口。
常见误区#
- 窗口越大越好,忽略无关 context 增幻觉(Related Work 引 noise 文献;本文主实验按 sufficient/insufficient 分层,非单独「无关片段」对照)。
- 把访谈中的位置效应实验归因于 Joren et al. 2025 正文。

教模型拒答:SFT/LoRA 与产品侧重排#
为什么#
若 selective generation 仍不足,自然会问:能否 SFT 出可靠的「我不知道」?论文 Table 3 与 Vertex 产品文档给出部分答案与边界。
机制与约束#
- Mistral-7B-Instruct-v0.3 + LoRA(rank 4, alpha 8):混合「I don’t know」与正常答案——%Correct 可升,%Abstain 仍极低(文献)。访谈称 Mixtral;以论文模型名为准。
- 访谈:100% I don’t know 样本能推过去,但混合比例与 abstention 非线性(演讲者观点);DPO/GRPO 对校准不确定性「有空间」——未在本文实验。
- Vertex AI RAG Engine reranking:提供 semantic reranker 与 LLM reranker(Gemini 评估 chunk 与 query 的 relevance)。文档未出现 sufficient context 作为排序目标。
- 论文 §6 Future Work:细粒度 sufficient autorater 可用于 ranking after retrieval——研究方向,非已核实产品行为。嘉宾称 Google 合作中将 sufficiency 思想接入 re-ranker(演讲者观点;无法在公开文档核实)。
怎么做(最小示例)#
产品侧:在多路召回后用 LLM reranker 压缩 top-k;评测侧:用 Table 1 级 autorater 离线标 insufficient 比例,驱动 recourse(web search、人工、更强模型),而非单一 abstain 门。
常见误区#
- 假设 Vertex 默认按 sufficiency 排序。
- 用单次 LoRA 实验否定一切 retrieval-aware fine-tuning(论文未测 RAFT 等;主持提到的 Frankenstein RAG vs 联合训练为访谈对照,非本文结论)。
评测生态:与 RAGAS、ARES、主动检索的并置#
| 方法 | 与 sufficiency 的关系 |
|---|---|
| RAGAS | 多维 LLM-judge;无同名 sufficient 标签 |
| ARES | 编译式 judge:context relevance、faithfulness、answer relevance |
| FLARE | 低置信 token 触发 forward-looking 再检索 |
| FLAMe | 24B 级 autorater,成本介于 Gemini 与人工之间 |
演讲者观点:下一步可像 RAGAS 一样为 sufficiency 建大数据集并微调 judge;生产日志标 insufficient 可触发改 corpus、人工裁定、贵检索等 recourse——与「只改模型」并列。
若你要落地#
- 离线:在自有日志上对 ((Q,C)) 跑 Gemini 1-shot 或 FLAMe sufficiency 标签,单独统计 insufficient ∧ correct 占比,再决定 recourse,勿用单一阈值全局 abstain。
- 在线选择性生成:采集 P(Correct)(或开源用 P(True))与 P(sufficient),用 logistic regression 拟合 hallucination,按目标 coverage 调阈值并画 selective accuracy 曲线。
- 检索预算:优先在 ~6k tokens 量级做截断与重排实验(对齐 Figure 2),再考虑拉满 10k+。
- 拒答训练:若 SFT「I don’t know」,用论文 Table 3 预期——准确率可能升而 abstain 不恢复;需另设计偏好学习或检索感知训练,并单独评 abstain。
- 产品重排:Vertex 等平台的 LLM reranker 文档写的是 relevance;将 sufficiency 接入排序视为 论文 Future Work + 自定义管线,上线前用金标子集验证。
参考与延伸阅读#
- Sufficient Context(arXiv:2411.06037) — 定义、Table 1–4、Figure 2/4/6
- arXiv PDF(2411.06037) — 表格与图形的可核对副本
- RAG 原始框架(Lewis et al., 2020)
- RAGAS 可用指标文档
- ARES: Automated Evaluation Framework
- P(True) / 语言模型自评校准
- FLAMe: Foundational Autoraters
- FLARE: Active Retrieval Augmented Generation
- Lost in the Middle(Liu et al., 2024)
- HotpotQA · MuSiQue
- Vertex AI RAG:Retrieval and ranking
- RAFT: Retrieval-Augmented Fine-Tuning — 访谈对照的检索感知微调方向
- Weaviate 文档:RAG 与向量检索 — 向量库侧工程背景(与论文无直接绑定)
- DBLP: Joren et al., ICLR 2025 — 书目信息
写作说明:论文称已发表于 ICLR 2025;若 arXiv v2 与 OpenReview 终稿不一致,以出版 PDF 为准。播客数字与图表不一致处,正文已标「文献 / 演讲者观点 / 未核实」。


