
真实仓库上的软件工程智能体:SWE-Bench 与评测脚手架之争#
当 RAG 与 Agent 的讨论从「能不能写 LeetCode」滑向「能不能修生产 bug」,评测对象也随之变化:不再是单函数通过率,而是 GitHub issue → patch → 项目测试是否转绿。Princeton 与 Stanford 一作团队提出的 SWE-bench 把这一链条固化成可复现基准;配套的 SWE-agent 则把争论焦点推到 Agent-Computer Interface(ACI)——模型与代码库之间该留多少「智能」给 LM,多少交给符号脚手架。
下文按工程主题整理机制、证据边界与仍在并行的路线;不把播客口述当作唯一事实来源,凡官方文档/论文可核对的与「演讲者观点」分开标注。
评测对象:从合成题到 PR 驱动的 resolved#
为什么#
HumanEval 类基准测的是孤立函数上的单测通过;真实工程却是跨文件定位、环境依赖、回归风险并存。若 Agent 产品只在这类指标上优化,上线后仍可能在「修一个 issue 弄挂十个测试」上翻车。
机制与约束#
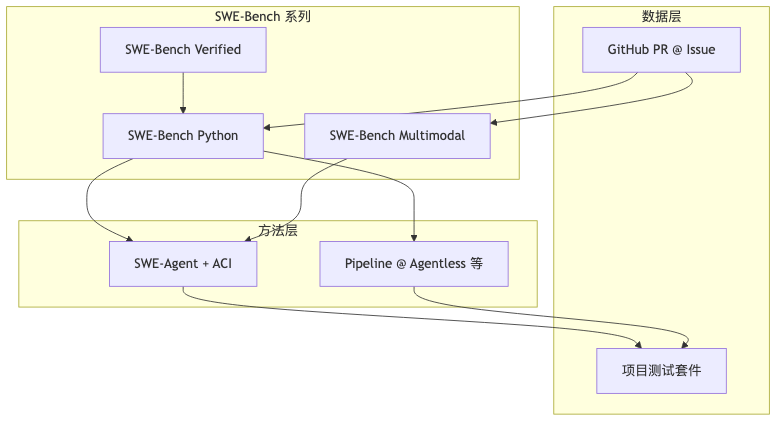
SWE-bench 论文摘要 写明:从 12 个流行 Python 仓库 收集 2,294 条真实 GitHub issues 与 pull requests;模型任务为 editing the codebase to address the issue;验收依赖 unit test verification,以 PR 合并后行为为参考。官网 original 页 进一步描述 pipeline:爬取 PR/Issue → 构建 Docker image → 对提交 patch 跑 Fail-to-Pass 等测试,判定 resolved。
主指标是 resolution rate(提交中成功 resolved 的比例),不是检索场景的 MRR;SWE-agent 在 SWE-bench 上报告 pass@1 = 12.5%(摘要页可核对)。不同子集(Full / Lite / Verified / Multimodal)分母与难度不同,不宜不标明 split 就横比百分比。
怎么做(minimal example)#
# 概念流程:本地需 Docker;具体 CLI 以 swebench 文档为准
# 1) 取实例:repo + base_commit + problem_statement
# 2) 模型产出 unified diff / patch
# 3) harness 在容器内 apply patch → 跑 FAIL_TO_PASS 测试
# 4) 全绿 → resolved
Hugging Face 数据集卡 提供 Oracle 与 BM25 retrieval 等设置,对应 SWE-bench_bm25_* 派生集——初版论文即含检索基线,而非「纯端到端猜文件」一种玩法。
常见误区#
- 把 leaderboard 上的 pass@1 式 resolved 率当成「已能替代中级工程师」——绝对分仍低,且子集 curated 程度不同。
- 忽略 FAIL_TO_PASS / PASS_TO_PASS 语义:resolved 是测试契约下的修复,不等于产品验收或 UI 主观正确。
- 名称含 SWE,便默认覆盖 Java、移动端、运维脚本;演讲者观点:当前系列只覆盖一部分仓库与工程活动,Multimodal 才系统扩展到 JavaScript / 视觉 UI(617 instances、17 个 JS 库,论文摘要可核对)。

Agent 循环 vs Pipeline:控制权与泛化税#
为什么#
「Agent」在工程里常指 LM 每步决定是否调工具、是否结束;另一条路线把流程写死为 localization → search → edit,并用 AST、向量库、类/函数清单替模型完成部分导航。两条路争的是同一预算:美元/实例、是否需要 Docker、换语言是否重写脚手架。
机制与约束#
| 维度 | Agent(如 SWE-agent) | Pipeline / compound 式(Agentless、AlphaCodium 类等) |
|---|---|---|
| 控制流 | 模型驱动工具调用与停止 | 预设阶段,符号步骤更多 |
| 代码库表示 | 偏简单接口,让 LM 自导航 | 预处理为 NL 摘要、向量索引、符号表 |
| 执行环境 | 通常需 Docker、可跑测试 | 不少方案弱化或省略在线执行 |
| 泛化 | 演讲者观点:更通用,但更贵、运维更重 | 演讲者观点:Python SWE-bench 上常很强,换 JS/React 易失效 |
SWE-bench Multimodal 摘要 给出一次对照:SWE-agent 约 12% resolved,次佳约 6%(特定实验设定)。演讲者观点(John Yang):在同一套 bash/CLI 交互下,agent 在 Multimodal 域仍相对最好,但绝对分仍低于 Python 版 SWE-bench——「接口通用」≠「任务已解决」。
无单一最优解:存在 LM 能力 vs scaffold 责任 的显式 trade-off;Multimodal 论文中强调,为 Python OOP 定制的 parser 在 React hooks / 函数式 代码上可能系统性失效——符号脚手架越重,换域时越可能要拆掉重写(演讲者观点,与论文「跨语言更难」方向一致)。
怎么做(minimal example)#
# Agent 路线(概念)
while not done:
obs = env.run(last_tool_output) # 测试日志、文件片段、搜索摘要
action = lm.choose_tool(obs) # edit | search | run_tests | finish
env.execute(action)
# Pipeline 路线(概念)
files = bm25_or_ast_localize(issue_text)
patch = lm.edit_only(files) # 常无在线测试环
常见误区#
- 用 Python 子榜高分推断「pipeline 全面优于 agent」——可能只是在 BM25 + 固定文件集 设定下过拟合。
- 把「无需 Docker」当作永久优势——官方评测仍以容器内跑测试为主线;pipeline 的「不执行」与 可复现 leaderboard 不是同一回事。
- 把 compound AI system(固定图:检索→重排→编辑)与 ReAct 式 agent 对立成意识形态;二者是可组合的工程选择。


检索、长上下文与「整库输入」#
为什么#
Issue 文本往往不足以指向正确文件;要么 检索 缩小上下文,要么用 长上下文 吞下更多文件。2023 年前后长窗口刚实用时,缺少「真正吃掉整库」的 coding benchmark,团队曾尝试 把整个 codebase 交给 LM 修 bug(演讲者观点,Carlos E. Jimenez)。
机制与约束#
SWE-bench 初版在论文与 HF README 中纳入 BM25 retrieval baseline——演讲者观点(John Yang):当时选的是「最快能跑通」的方案,更细的检索/符号结构问题留到 SWE-agent 再系统回答。
并行探索仍在 leaderboard 上共存:file-by-file 长上下文、向量库 schema、agent 自带 grep/搜索(ACI 专用搜索命令)。三者对 上下文预算、歧义空结果、假阳性文件 的权衡不同;未决,无公开结论证明哪一种在「全 split、全模型」下支配。
怎么做(minimal example)#
# BM25 检索 + 编辑(概念,与 HF 派生集一致)
candidates = bm25_index.query(issue.title + issue.body, top_k=20)
context = "\n".join(read_file(f) for f in candidates)
patch = llm.generate_patch(context, issue)
常见误区#
- 认为「128K 上下文 = 不需要检索」——成本、注意力稀释与 无关文件噪声 仍可能拖垮 pass@1。
- 只优化 embedding 模型,却不在 FAIL_TO_PASS 上验证 patch——检索 MRR 与 resolved 脱钩。
- 演讲者观点(主持人提出、嘉宾未否定但无对照实验):增强 docstring / 仓库元数据有时比改 agent 更有效——值得做 ablation,不能当已证事实。

ACI:工具输出形状决定 agent 上限#
为什么#
同一 LM,换交互界面可能大幅改变 resolved。SWE-agent 论文核心主张是定制 Agent-Computer Interface:让模型顺畅地读文件、搜代码、跑测试,而不是把原始 shell 输出无节制灌回上下文。
机制与约束#
SWE-agent ACI 文档(可核对)要点包括:
- 专用搜索命令:只列出有匹配的文件路径,避免刷屏。
- 文件查看器:每轮约 100 行;文档写明展示更多 match 上下文反而迷惑模型。
- 与裸
grep/bash 相比,强调摘要式搜索结果。
演讲者观点(John Yang):曾尝试分页展示 grep 命中,翻到第 37 条仍占满上下文却未增加信号——分页浏览比一次性摘要更差(设计叙事;未见播客给出量化 A/B 数字,机制以 ACI 文档与论文为准)。
怎么做(minimal example)#
# 反模式:把 500 行 grep 原样塞进 prompt
# 较优:工具返回「路径 + 行号摘要 + 可选局部片段」
search("TypeError.*NoneType") →
src/foo.py:42-48 (snippet)
tests/test_foo.py:10 (snippet)
常见误区#
- 堆更多工具(GDB、浏览器、K8s)而不改 观测压缩——CTF agent 与 SWE-agent 初始工具集不同,演讲者观点 来自 John 的 InterCode / CTF 经验。
- 假设「语言无关」等于「零归纳偏置」——bash 接口在 Windows/C# 仓库上仍可能吃亏。

评测基础设施:Docker、Verified 与数字的可信度#
为什么#
Leaderboard 上的 resolved 率,隐含「patch 在什么环境里跑测试」。环境漂移、依赖缺失、 flaky test 会把 模型能力 与 harness 缺陷 混为一谈。
机制与约束#
SWE-bench GitHub README 时间线(可核对):
- 2024-06-27:与 OpenAI Preparedness 合作,迁移到 fully containerized evaluation harness using Docker。
- 2024-08-13:发布 SWE-bench Verified——500 题,工程师审核描述、测试与可解性(verified 页)。
评测指南 将 Docker 作为现行评测要件。
演讲者观点(John Yang):称 2025 年 1 月 才意识到初版「现有 CI 即可复现」是错的,必须与 OpenAI 做 Verified 时强化容器化——这与官方 2024 年中已宣布容器化 在时间上冲突;更稳妥的表述是:团队对早期非容器实践的反思,或针对 Multimodal/JS 环境的再加固,不能写成「Docker 评测到 2025 年 1 月才引入」。
演讲者观点:Verified 的 Docker 沙箱工程与 500 例人工筛选 同等重要,但前者不易在 Twitter 上传播。沙箱极限:浏览器渲染、headless Chrome、部分能力在沙箱中不可用——leaderboard 数字依赖底层设定(与 Multimodal 论文 增加 Node.js、Chrome、Xvfb 一致)。
无法核实:John 口头「单实例 Docker 镜像最大约 10 GB」——已查 Multimodal 论文/HF/官网未见单镜像体积表;官网建议评测机 ~120 GB 磁盘(全库镜像规模),勿将口述当作上限定理。
怎么做(minimal example)#
# 提交评测前自检(概念)
docker info
# 按 SWE-bench 文档构建/拉取对应 repo@commit 镜像
# 使用 sb-cli / Modal 等云评测时核对 split 名称与 harness 版本
常见误区#
- 只报 Verified 500 题分数,却用 Full 集训练的检索索引——数据泄漏风险需查项目政策,播客未展开。
- 在本地无沙箱环境「目测 patch 合理」代替跑测试——与 resolved 定义不符。
- 忽视 PyPI 导向 采集(collect README)与 Node/前端 仓库生态的差异——Multimodal 是为补这一缺口。


多模态与「看见界面」:Xvfb、Computer Use 与域迁移#
为什么#
大量前端 bug 的验收标准是 像素/布局/交互,Issue 文本却不包含截图。Multimodal 把 visual、user-facing JavaScript 纳入同一 resolved 契约。
机制与约束#
Multimodal 论文 描述:在 SWE-bench Docker 上增加 Node.js、Chrome;用 Xvfb 模拟显示、xwd 截图;SWE-agent M 提供浏览器/看图能力。
演讲者观点(Carlos E. Jimenez):与 Anthropic Computer Use「同类」——未见 SWE-bench 官方文档建立产品级等价;Xvfb + 浏览器基础设施有论文支持,类比本身未证实。
演讲者观点:容器化 + 不允许 agent 常驻本机 将成为常态——安全与可复现优先于「本地全自动」;官方推 Docker/云评测(Modal、sb-cli),但并非字面「禁止本地开发」。
怎么做(minimal example)#
# 概念环:容器内 headless 显示 → 截图 → 模型 → patch → 视觉/单元测试
Xvfb :99 → 打开 PR 复现步骤 → screenshot → VLM → edit JS/TS → npm test
常见误区#
- 把 Multimodal 的 12% vs 6% 读成「多模态已接近人类」——绝对分仍低,且 HF split 合计 612(102 dev + 510 test)与论文 617、官网 517「含视觉元素」等口径可能不同,写作须标明来源。
- 在 Python pipeline 上微调 prompt,便期望零改动迁移到 React hooks——与嘉宾「拆掉 Python 专用 scaffold」警告一致。

sequenceDiagram
participant I as Issue @ 截图线索
participant A as SWE-Agent M
participant X as Xvfb @ Chrome
participant H as Harness
I --> A
A --> X: 复现 UI
X --> A: 像素观测
A --> H: patch
H --> H: FAIL_TO_PASS + 视觉测试
人在环路:自主修 bug 还是协作副驾驶#
为什么#
生产环境问责在人;「全自动 merge」与「daemon 只总结 stack trace」是不同产品承诺。
机制与约束#
演讲者观点(John Yang,ReAct 脉络):有人要指挥 agent 逐步执行,有人要 agent 给建议、人动手写;近未来答案因场景而异。「最终一切 agent 化」在同一段对话里与「协作形态高度场景化」并存——张力未消解。
监控/诊断类 daemon:未必自动改代码(演讲者观点),避免无人负责的自动 patch。
怎么做(minimal example)#
# 分级落地
L0: 只读 — 总结 trace、猜根因、列可能文件
L1: 建议 patch — 人 review 后应用
L2: 自动 PR — 必需测试绿 + 人 approve + 回滚策略
常见误区#
- 用 SWE-bench resolved 推销「无人值守 on-call」——基准不含 on-call 轮转、事故沟通、跨团队协调。
- 忽视 成本:演讲者观点 SWE-agent 修一例约 2+ 美元,pipeline 约 0.4–0.5 美元或更低(当时 leaderboard 经验)——官方无固定报价;官网 leaderboard JSON 可见单例 约 $0.19–$3+ 浮动,随模型与步数变化(无法核实为常数)。

若你要落地#
- 先钉评测契约:选定 split(Full / Verified / Multimodal)、harness 版本与 Docker 能力;用 评测指南 理解 resolved,勿用检索指标偷换。
- 在 Agent 与 Pipeline 间做显式 trade-off 表:是否要在线跑测试、单次美元上限、目标语言是否只有 Python;换 JS/前端时预案 拆掉 Python 专用 parser(Multimodal 教训)。
- 投资 ACI 而非堆模型:搜索/读文件的输出形状优先于再加一个 405B;对照 ACI 文档 做摘要式工具返回。
- 把环境当一等公民:跟官方 2024-06 容器化时间线对齐;若听到「2025 才上 Docker」类口述,以 README 为准做内部复盘,而非对外宣传。
- 产品分层人在环路:从只读诊断到自动 PR 分级上线;用 Verified 子集做回归,再考虑是否追求 Full 集分数。
参考与延伸阅读#
- SWE-bench 论文(arXiv:2310.06770) — 任务定义、2,294 实例与测试验收
- SWE-bench OpenReview(ICLR 2024) — 会议与审稿信息
- SWE-bench 官网与 Leaderboard — 各子榜与提交入口
- SWE-bench 原版说明(original.html) — 数据采集与 Fail-to-Pass
- SWE-bench Verified 说明 — 500 题人工审核子集
- SWE-bench GitHub 仓库 README — Docker 迁移与 Verified 时间线
- SWE-bench 评测指南 — Docker 要求与 resolution 指标
- Hugging Face:princeton-nlp/SWE-bench — Oracle / BM25 等设置
- SWE-agent 论文(arXiv:2405.15793) — ACI 与 pass@1 12.5%
- SWE-agent ACI 设计文档 — 搜索与文件查看器约束
- SWE-bench Multimodal 论文 — JS、视觉测试与 Xvfb
- Hugging Face:SWE-bench_Multimodal — 公开 split 与字段
- OpenAI:Introducing SWE-bench Verified — 与 OpenAI 合作背景(访问性以实际 HTTP 为准)
- Berkeley BAIR:Compound AI Systems — pipeline 式多组件系统框架
- ReAct 论文(arXiv:2210.03629) — 推理与行动交织的 agent 脉络
- Anthropic:Computer Use 文档 — 与 Multimodal 口述类比的独立阅读


