
合成数据:RAG、Agent 与评测里的「造数」边界#
向量库、检索 Agent 与离线评测集,最终都绕不开同一类工程问题:在真实标注稀缺、隐私受限或长尾分布稀疏时,用什么机制补数据,以及补出来的分布是否值得信任。 Hugging Face / Argilla 生态里的 distilabel、Synthetic Data Generator(SDG)与 Persona、DEITA 等研究线,讨论的是 LLM 驱动的数据合成 pipeline——从 instruction 扩增到 preference、再到 Hub 上的可查询数据集。画面素材为三人远程访谈,未见可读架构图或结果表;下文定量与 API 行为以论文、数据集卡片与官方文档为准,嘉宾口述标为演讲者观点。

问题空间:合成数据落在哪条链路上#
为什么:RAG 需要 query–passage–answer 或 chunk 级标注;Agent 需要 tool trace、多轮对话、失败恢复 样本;评测需要 held-out、可复现 的输入变体。真实日志往往带 PII、分布偏斜,或根本不存在「标准答案」。合成数据常被当作 data augmentation 的 LLM 版(Ben 开场表述——演讲者观点),但工程上至少要分清:你是在 扩增训练集、改写评测输入、还是 蒸馏另一模型的行为。
机制/约束:David 提出四层 taxonomy——augmentation、effective prompting、reformation/rewriting、distillation/synthesis(对模型做 completion 或领域蒸馏)——嘉宾框架,非行业标准术语表。与 Llama 3.1 Model Card 中「微调阶段 25M+ synthetically generated」及 LLM-based classifiers 用于数据筛选的叙述可对照:合成 + 过滤 已进入主流发布流程,但 未 意味着预训练主语料由合成构成(部分可核对)。
常见误区:把「合成」等同于「用 GPT 多生成几条」;未定义 目标分布(SFT / DPO / RAG 检索评测)就堆行数,容易在规模化时撞上质量墙——David 称 10 条试跑正常、100 条常需改 pipeline 或换更大模型(演讲者观点,非普适阈值)。对 RAG 而言,合成 query 而不动 chunk 边界与 citation 约束,评测分数可能虚高:模型学到的是「问法分布」,而非索引是否召回正确段落——宜把 检索命中率 与 生成忠实度 拆开度量。
Post-training 形态:instruction、preference 与 critique#
为什么:Self-Instruct 用 175 条种子指令经改写扩到约 52k instructions,再用 GPT-3 API(论文用语;口语常称 ChatGPT)生成 completion 后 SFT——规模数字与 README 一致。后续 UltraFeedback 从既有 prompt 出发,多模型各生成多条 response,再由 GPT-4 做细粒度反馈——流程 verified。
机制/约束:David 将 post-training 数据归纳为 instructions → preferences → critiques 流水线(演讲者归纳)。UltraFeedback 官方四维为 instruction-following, truthfulness, honesty, helpfulness;嘉宾曾列举 helpfulness, conciseness, effectiveness——helpfulness 重合,后两者无官方一一对应,写作时宜以 UltraFeedback README 为准。
怎么做(minimal):固定 seed prompt 集 → 多模型采样 completion → 用 judge(GPT-4 或本地分类器)打维度分 → 导出 preference 对供 TRL DPO/ORPO。
常见误区:preference 数据 越多越好;David 建议对两 completion 的 helpfulness 等分数 求差,差值过小则 不宜纳入 DPO(演讲者启发式,非 UltraFeedback 官方规则)——模型难以学习的「近似平局」会浪费预算。


Persona 驱动合成:多样性,而非知识载体#
为什么:Persona Hub(正确 ID:2406.20094,非误链的 2407.17308)从网页等抽 Text-to-Persona,再 Persona-to-Persona 生成关系人(如店员 → 顾客),并条件生成 instruction–response;论文称可达 10 亿级 persona 规模(摘要自述)。Ben 强调:约 50 词的 persona 描述不能替代可抽取的领域知识,主要带来 variety;同一长文档 + 不同 persona 可改变 instruction/response 分布(演讲者观点)。
机制/约束:论文将 persona 视为 分布式知识视角载体;嘉宾则强调 variety 与覆盖文档 低曝光章节(同一文档直接要 QA 易卡在热门段落——演讲者观点)。二者张力宜并列写明,而非二选一。去重:Persona Hub 论文 写明 embedding cosine similarity > 0.9 过滤,并辅以 MinHash threshold 0.9——verified。
Persona-to-persona 非「向量杂交」:主持人曾类比 batch 内两 persona 交叉;David 澄清为 单 persona 为 seed,由 LLM 生成互动对象,与论文 Persona-to-Persona 中 interpersonal relationships 一致——文献/访谈一致。
怎么做(minimal):选 corpus(如 RedPajama v2 或 fineweb-edu)→ distilabel 跑 Text-to-Persona → 条件生成 QA → 嵌入去重 → 推 Hub。Ben 举例:对 Weaviate 文档 可直接让 LM 综合非结构化内容为 schema 等结构(演讲者观点)——这与「persona 不提供领域知识」并不矛盾:知识仍来自文档,persona 只改写 谁在用、问什么角度。
常见误区:认为 persona-guided 将 一统 所有合成路径。Ben 否认;paraphrase、keyword 注入、原始 seed 仍并存(演讲者观点)。Paraphrase 评测集更偏 鲁棒性测试;训练侧多样性可来自 Persona Hub 等机制,而非仅改写 eval 输入(演讲者观点)。

argilla/FinePersonas-v0.1 在 fineweb-edu 上生成约 2100 万 条 persona,标签含 distilabel;聚类子集 FinePersonas-v0.1-clustering-100k 提供 177 个 cluster 供企业按主题选 persona——数据集卡片可核对;「工程类簇」为使用场景举例(演讲者观点)。
Pipeline 工程:distilabel、缓存与有状态执行#
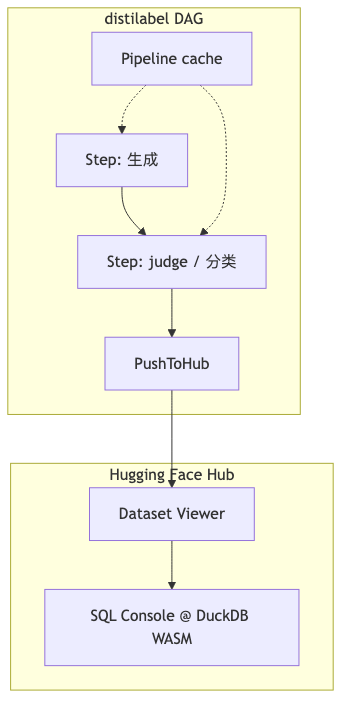
为什么:合成 pipeline 常是 DAG:生成 → 打分 → 过滤 → 写 Hub;中途失败若从头重跑,成本不可接受。
机制/约束:distilabel 文档支持 Ray 调度 vLLM(含 tensor_parallel_size)、PushToHub 边生成边落盘——组件存在 verified。导航含 Pipeline cache;「按 pipeline 配置参数键控缓存、失败回退上一步」 为嘉宾描述,参数键控措辞本次未在可访问文档正文定位,宜对照源码或版本更新说明。Weaviate Transformation Agent 强调 workflow 持久化、第 N 步失败从 N 续跑(主持人产品叙述——演讲者/主持人观点),与 distilabel 的 DAG 缓存是 不同 durability 模型,选型取决于你是否需要跨会话、跨服务的编排。
怎么做(minimal):
# 概念示意:distilabel Step 链 + PushToHub(API 以官方文档为准)
from distilabel.pipeline import Pipeline
# pipeline.add_step(...).add_step(PushToHub(repo_id="org/synth-rag-v1"))
# pipeline.run(parameters={"num_rows": 1000})
SDG README 默认 MAX_NUM_ROWS=1000;任务类型含 Text Classification、SFT、RAG——verified。嘉宾称 500–1000 条 即可起步试跑(演讲者观点;500 非文档默认值)。
常见误区:小规模 demo 顺利即认定 万级可线性扩展(见上节 10 vs 100 条经验)。另: SDG 仓库 注明维护重心已转向 aisheets——产品生命周期,不改变「曾基于 distilabel + Gradio」事实。

Ben 的实践:DSPy 离线优化 prompt,再固化进 distilabel;库内深度集成「轻到不必要」(演讲者工程取舍)。distilabel 强调 可复现的固定 prompt;DSPy 适合多 API、多模型下 一致性 优化——与 DSPy 程序级优化叙事正交,可组合而非互斥。
质量与多样性:DEITA、分类器与「坏榜好零件」#
为什么:合成行数膨胀后,质量、复杂度、多样性 三者常冲突;全量喂入 SFT/DPO 未必最优。
机制/约束:DEITA(正确 ID:2312.15685)在 complexity × quality 标量(论文 evol score (s = q \times c))排序后,用 Repr Filter 在表征空间保多样性(阈值 τ 附录约 0.8–0.9)——verified;访谈中的「2D 映射」为 语义近似、表述不严格。Ben 称 WizardLM 端到端榜样不算强,但 prompt 进化、嵌入多样性筛选 等步骤被后续工作复用(演讲者评价);DEITA README 在 6K SFT 数据预算 下 DEITA-7B 可优于 WizardLM-13B 部分指标——「不强」需结合基准与数据量理解,非全面落后。
HF 为 SmolLM2 等训练 教育内容分类器(0=商业等,1=教材级)——David 称比纯 entropy/diversity 更重(演讲者观点)。SDG 迭代中用 下游 fine-tune 是否涨点 验证 pipeline 是否有意义(演讲者实践),因果需对照实验设计。
常见误区:以单一 benchmark 分数否定整条方法链;忽视 逐步技巧 的可拆卸复用。图像 preference 管线(LMSYS 类 prompt → 复杂度进化 → FLUX 双图 → Argilla 二选一 → ~15k 行 → DPO/ORPO)为 嘉宾项目叙述;当前可见 Hub 仓库元数据为 n<1K、README 占位——~15k 未能用公开卡片证实,引用时宜标注未验证边界。中期 NSFW 渗透 prompt 与生成图,需 preference + 安全分类 + 人工扫尾(演讲者项目教训)。
Hub 数据栈:从生成到 SQL 筛选#
为什么:合成数据若不能 版本化、可查询、可导出训练格式,就只是临时 JSON。
机制/约束:HF Datasets Viewer SQL Console 由 DuckDB WASM 驱动,可从 Data Studio 过滤并导出 Parquet/CSV——verified。David 描述在 约 5 万–10 万 行规模用 SQL 做 近似近邻 式向量检索;远程 ANN 索引能力边界 以当时 Hub 为准(演讲者观点,2026 是否变化未复核)。
怎么做:生成后 PushToHub → Data Studio 打开 → SQL 过滤(如 score_chosen - score_rejected > 0.3)→ 导出供 TRL / transformers / sentence-transformers 训练。
常见误区:把 SQL Console 当作生产级 向量数据库;它擅长 批处理筛选与探索,不等价于在线 ANN 服务。


未收敛的结论:几条仍开放的分歧#
| 主题 | 常见做法 | 嘉宾强调 | 证据边界 |
|---|---|---|---|
| Persona 是否承载知识 | 把 persona 当「角色扮演」增广 | variety > 知识;文档才是知识 seed | 与 Persona Hub 论文表述有张力 |
| Paraphrase | 评测集改写测鲁棒性 | 训练多样性另有 Persona/keyword 路径 | 演讲者观点 |
| Prompt 优化产品化 | Agent 内在线改 prompt | HF 侧更重 自训模型 + 自有数据;Weaviate 关注 RAG optimization as a service | 主持人/嘉宾观点 |
| DSPy × distilabel | 库内集成 | 离线优化 + 版本化注入即可 | 演讲者工程取舍 |
| 合成用于 pre-train | 仅 post-train | Llama 3、SmolLM2 等已用合成+分类过滤 | Llama 3.1 卡片 partially verified |
不必强行统一为一条「最佳实践」;目标函数(涨点、覆盖、安全、成本)不同,pipeline 组件就应不同。Agent 轨迹合成若缺少 工具名、参数与观测结果 的结构化字段,后期很难做 step-level 归因;评测侧若只 paraphrase 用户问句而不变 工具可用集与环境状态,测到的多是措辞鲁棒性,而非规划能力——两类需求应分 dataset schema 设计,而非共用一个 JSONL 模板。
若你要落地#
- 先写清 seed 类型:知识来自 文档/RAG corpus 还是 persona/paraphrase 只负责 分布打散;二者混用时在 metadata 里标注来源,便于失败回溯。
- 用正确论文与官方维度:UltraFeedback 以 四维反馈 为准;Persona Hub、DEITA 分别引用 2406.20094、2312.15685。
- 小规模验证再放大:500–1000 行(SDG 默认上限 1000)跑通 distilabel DAG + Hub 导出,再用 下游任务 metric(分类、RAG、SFT loss)决定是否加预算;preference 删除 分差过小 的样本。
- Pipeline 耐久性单独选型:要跨失败续跑选 有状态 workflow(如 Transformation Agent 路线);要 可复现、可缓存的批处理 选 distilabel + Ray/vLLM,并对照 Pipeline cache 文档与版本。
- 发布前安全与去重:图像/开放域文本合成假设 NSFW 与近重复 会出现;Persona 0.9 阈值与 DEITA Repr Filter 可作为默认起点,而非终点。
参考与延伸阅读#
- Self-Instruct: Aligning Language Models with Self-Generated Instructions (arXiv:2212.10560)
- UltraFeedback: Boosting Language Models with High-Quality Feedback (arXiv:2310.01377)
- UltraFeedback 官方 README(GPT-4 四维标注说明)
- Scaling Synthetic Data Creation with 1,000,000,000 Personas — Persona Hub (arXiv:2406.20094)
- What Makes Good Data for Alignment? — DEITA (arXiv:2312.15685)
- DEITA 项目 README(含与 WizardLM 对比表)
- distilabel 文档首页
- distilabel:Ray 与 vLLM 扩展指南
- Synthetic Data Generator 公告博客
- argilla/synthetic-data-generator Space
- FinePersonas v0.1 数据集卡片
- Hugging Face Hub:Datasets SQL Console(DuckDB WASM)
- Llama 3.1 Model Card(合成微调数据与分类器筛选)
- ModernBERT 论文 (arXiv:2412.13663)
- TRL:偏好优化训练文档


