
向量库上的 Query Agent:可审计检索与两种「问数据」模式#
团队把 RAG 接到业务库之后,很快会遇到一类重复劳动:把自然语言拆成 collection 路由、hybrid 检索、属性 filter、聚合,再决定要不要生成带引用的答案。通用 Agent 框架能编排这些步骤,但每一步都要自己接 Weaviate API、处理 schema 漂移与空结果重试。Weaviate Query Agent 走的是另一条路——把「会调用 Weaviate 的 agent」做成数据库侧能力,对外暴露 Ask Mode 与 Search Mode 两种入口。本文按可核对文档与仍属产品/访谈主张分层讨论,不预设「一种模式替代全部自研 RAG」。


问题空间:Chat RAG、通用 Agent 与「数据库的自然语言接口」#
为什么单独谈 Query Agent#
常见做法是:向量检索 + LLM 生成,或 n8n 式 DAG 把多步串起来。前者往往只暴露「最终段落」,审计时看不到实际 filter 与 limit;后者灵活,但 Weaviate 特有算子(多 collection、聚合、hybrid 参数)都要自己维护。Query Agent 的定位更接近 agent-first data access(演讲者观点):专长是读懂 schema、下发可复现的 Weaviate 查询,而不是通用任务规划。这与 Compound AI 里「多模型 + 检索 + 工具」的宏观图景相容,但实现边界更窄——未验证其能否替代跨 Slack、数仓的异构编排。
机制与约束#
- 运行环境:文档写明面向 Weaviate Cloud(Sandbox 可试用);自托管是否等价支持需查当前版本说明(未在本文环境复现)。
- 计费粒度(产品页,2026-05 核实):Ask 约 4 requests/query,Search 约 1 request/query——集成 Search 作「检索 API」在成本上往往更省,但不等于检索质量自动优于自写
hybrid(见下文评测边界)。 - GA 时间线:
weaviate-agentsv1.0.0 发布于 2025-09-16(GitHub Release);首包 v0.3.3 为 2025-02-28,与访谈中「约 2025 年 3 月 preview、约六个月反馈」大致一致,非精确日历。

怎么做(最小示例)#
from weaviate.agents.query import QueryAgent
from weaviate.classes.agents.query import QueryAgentCollectionConfig
qa = QueryAgent(
client=client,
collections=[
QueryAgentCollectionConfig(name="Jeopardy", views=["default"]),
],
)
# Ask:答案 + 溯源 + 审计字段
ask_resp = qa.ask("Which category appears most often?")
# Search:仅检索,无 final_answer
search_resp = qa.search("questions about European history", limit=10)
(完整连接、Auth、推理 API Key 见 Usage — Instantiate。)
Cloud 控制台与 SDK 的分工#
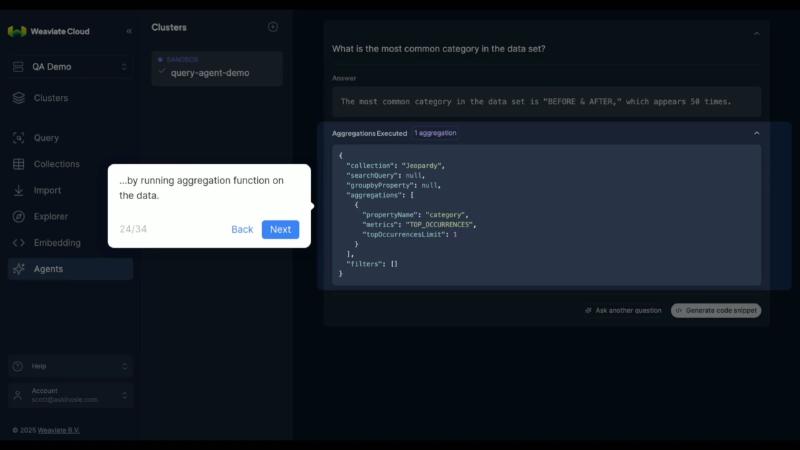
已核实方向:Weaviate Cloud 提供 Agents 页,可选 collection、向量化模块与 system prompt,并用自然语言框试用(见图 ocr_pick_004)。这对产品/数据同学是零代码冒烟路径;工程落地仍应走 weaviate-agents SDK,把 同一问句 在控制台与 ask/search 的 searches 输出对齐,避免「演示可用、流水线不一致」。控制台展示的聚合 JSON(如 TOP_OCCURRENCES)与 SDK 的 aggregations 字段应对同一套语义,但 UI 字段名 未 与 OpenAPI 逐字段核对。
常见误区#
- 把「两行调用」当成零配置:collection 列表、向量化模块、Cloud 凭据仍要显式准备(演讲者观点中的「两行」是营销式简化)。
- 默认 Query Agent 等于「通用自主 Agent」——超出 Weaviate 查询/聚合的能力不在承诺范围内。
- 只在控制台验收、未把
searches/aggregations纳入 CI——回归时无法发现路由或 filter 漂移。
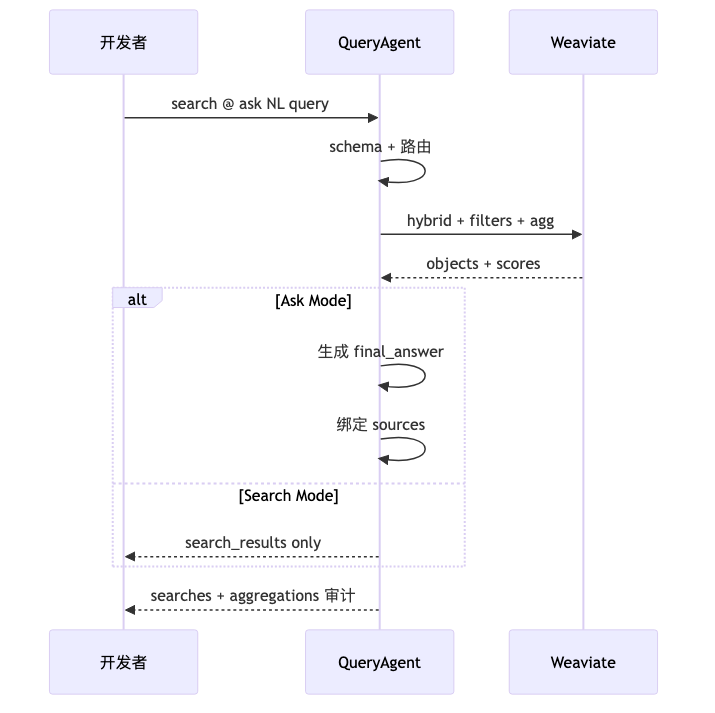
Ask Mode 与 Search Mode:同一 NL,不同目标函数#
为什么 GA 要拆两种模式#
早期 run 路径偏 端到端:路由 → 多路检索 → 扩展 → 写答案(演讲者观点)。集成方常见做法是 丢弃生成答案,只用 sources / search 结果 喂给自有 agent——产品反馈直接催生了 Search Mode(Usage 写明 retrieval only, no answer generation)。Ask 面向「要给终端用户一段话 + 引用」;Search 面向「我要高质量 IR,生成在自己栈里做」。
| 维度 | Ask Mode | Search Mode |
|---|---|---|
| 输出 | final_answer + sources + 审计字段 | search_results(QueryReturn) |
| 文档定义 | 含答案生成 | 无答案生成 |
| 典型集成 | 聊天、报告摘要 | 自有 LLM、排序、重排后再生成 |
| 质量主张(访谈) | Grounded 答案 + 对象级引用 | 须相对裸 hybrid 可感知提升(无公开 uplift 表,见 P09) |
机制:Search 流水线里有什么#
已核实(文档示例 JSON):Search 响应可含 filters(如 price < 100)、metadata 中的 rerank_score,说明存在重排信号。访谈补充、文档未逐步列出:query decomposition、term expansion、overfetch 再 cross-encoder/listwise rerank(演讲者观点)。因此 Search Mode 的增益更可能来自 filter 缩小候选空间 + 复合 IR 流水线,而非新的 BM25/向量核函数——这与「只靠更大 embedding 模型」的叙事并不相同。
怎么做#
多轮对话在 GA 用 ChatMessage 列表(Conversational queries);v1.0.0 起 run 已弃用,指向 V2 API(Release v1.0.0)。访谈称 alpha 未原生支持 chat、用户自行 workaround——无官方 changelog 逐条对照,属时间线叙述。
常见误区#
- 认为 Search 一定比 Ask「更强」——文档只区分职责,未保证 Search 在所有数据集上优于你调参后的
hybrid。 - 在 Search 路径仍期待
final_answer——应改读SearchModeResponse.search_results。
可审计响应:queries、aggregations 与「部分答案」#
为什么审计轨迹比「一段 Markdown」重要#
合规与调试场景需要回答:模型到底查了哪张表、用了什么 filter、有没有跑聚合。Weaviate 把 agent 实际下发的 searches 与 aggregations 放进响应(Inspect responses),便于用 REST/客户端 手工复现同一查询。Ask 模式另有 is_partial_answer、missing_information(AskModeResponse 源码)——显式标记覆盖不全,比静默幻觉略可控。
机制与约束#
sources:object_id+collection(文档 Sources 段)——对象级溯源,不是全文逐句 citation 协议。- 聚合指标名(如
TOP_OCCURRENCES)与控制台演示 JSON 一致;字段全集以运行时 OpenAPI/JSON 为准(未逐字段对照 OpenAPI)。 - 两阶段引用(先
final_answer,再独立 citation 步骤):Charles Pierse 演讲者观点;公开文档只承诺有sources,未描述步骤数或独立 citation agent(客户端源码亦无citation符号)。
怎么做#
print(ask_resp.searches) # 含 queries、filters、collection
print(ask_resp.aggregations) # 无聚合时文档示例为 No Aggregations Run
print(ask_resp.is_partial_answer, ask_resp.missing_information)
for s in ask_resp.sources or []:
print(s.collection, s.object_id)
Citations 与生成解耦:工程含义#
若两阶段流水线属实(演讲者观点),产品行为更接近:先在检索结果上合成答案,再把对象绑定到 sources,而不是在单步生成里「边写边贴脚注」。这对评估的影响是:应分别测 检索召回(searches 是否覆盖真值对象)与 归因准确率(sources 是否支持 final_answer 中的关键断言)。医疗、合规等场景,访谈建议 heavier citation 子 agent 或多轮校验——未在 GA 文档中作为内置模式提供。
常见误区#
- 有
sources就等于答案正确——访谈明确 citations 非银弹;可能出现「引用牵强但存在」。 - 把
sources等同于论文里的 attribution metric——未报告 nDCG、faithfulness 等(评测缺口,见下节)。 - 在 Ask 路径忽略
is_partial_answer——用户会看到流畅文本,但系统已声明信息不足。
Schema 内省、property description 与结构化 filter#
为什么 schema 文档突然变「便宜杠杆」#
纯语义检索擅长「夏天沙滩鞋」这类描述;价格区间、日期、枚举 更适合显式 filter(对话中的共识,与 Weaviate Filters 能力一致)。Query Agent 启动时会 分析 collection 与 property descriptions(Overview — Query Agent context)。多年未被重视的 description 字段,在 agent 路由与 filter 生成里变成 zero-shot 提示:例如国家字段注明 ISO 3166-1 alpha-2,可减少 filter 写成 Ireland 而非 IE 的失败(演讲者观点 + 文档方向一致)。
机制#
客户端模型暴露按类型的 filter:INTEGER、TEXT、BOOLEAN、TEXT_ARRAY、DATE、UUID 等(KnownFilterType)。访谈称结合 structured output 在执行前拒绝无效算子组合,以降低 retry;文档写 agent 生成 filter,未承诺「零 retry」或「执行前必拒绝」。另一点访谈强调:无法预先知道带 filter 的查询是否非空——空结果仍需运行时处理。
怎么做#
在 schema 中为关键属性写清语义与编码:
{
"name": "country_code",
"dataType": ["text"],
"description": "ISO 3166-1 alpha-2 country code, e.g. IE for Ireland"
}
常见误区#
- 空 collection 或缺 description 仍期待稳定路由——应用测试覆盖「冷启动」与「字段歧义」。
- 把 text-to-SQL 经验直接套用:向量库的 filter 与 SQL 优化器假设不同。
多 Collection:路由、联邦检索与「语义 join」#
为什么「选一个 collection」不够#
产品页与 README 提到 cross-collection routing(产品页)。访谈观察到:contracts / customers 等 语义相关但无显式 FK 的 collection,需要 多库查询、结果交错(interleaved)返回(演讲者观点);官方文档 未出现 interleaved 一词。嘉宾用语 semantic joins 指运行时依 schema 元数据关联意图——与 SQL join 互补而非替代(未验证与具体 GraphQL 查询一一对应)。
机制#
- 构造时:
QueryAgent(client, collections=[...]);运行时可在ask/search传入collections或QueryAgentCollectionConfig(含views)。 - 若只需单表,仍应显式收窄 collection 列表,避免路由漂移。
怎么做#
qa = QueryAgent(
client=client,
collections=[
QueryAgentCollectionConfig(name="Meals", views=["default"]),
QueryAgentCollectionConfig(name="RecoveryArticles", views=["default"]),
],
)
qa.ask("High-protein dinners under 600 kcal last week and recovery tips")
常见误区#
- 多 collection 等于自动 ER 建模——无 schema 描述时,联邦结果可能杂乱。
- 期待 SQL 式确定性 join——agent 路由是概率性的,需 eval。
评测、BEIR 与尚未公开的 uplift#
为什么「优于 pure hybrid」不能写死数字#
访谈称 Search Mode 相对 pure hybrid 有 published 提升,且 Connor Shorten 提到在 BEIR 等基准上做过实验(演讲者观点)。截至 2026-05 对 docs.weaviate.io/agents/**、产品页与常见博客的检索,未找到含 BEIR 子集、nDCG@k、Recall@k 或相对 hybrid(α、limit、是否 rerank)对照的公开表。BEIR 论文本身强调 零样本、异质集合;指标口径(nDCG@10、MRR 等)与 Weaviate hybrid API 参数 未对齐 前,只能引用口述,不能写「提升 X%」。
部分核实:流水线组件(filter、decomposition、expansion、rerank)属于业界常见组合;无法核实:具体 uplift 与实验配置链接。
建议的自测清单(可复现)#
在你方 collection 上固定 20–50 条「金标问句」,每条记录:期望 collection、是否应出现 filter、期望 top-k 对象 id。对比三条路径:(1) 手写 hybrid;(2) QueryAgent.search;(3) 可选 Ask。记录 searches 中的 filters 与 rerank_score 分布,而不是只评 LLM 答案 BLEU。若 Search 仅在「带价格/日期约束」子集上胜出,说明收益来自 约束检索 而非向量语义本身——这与访谈中对 Search Mode 机制的判断一致(演讲者观点)。
常见误区#
- 把营销句「better than hybrid」当成你数据集上的保证——应在自有 schema 上做 A/B,并固定
alpha、limit、targetVectors。 - 用 BEIR 总分横向对比不同厂商幻灯片——子集与预处理不一致时无意义。
- 只评端到端问答 F1,不保存
searches日志——出问题时无法区分「路由错了」还是「生成胡说」。
MetaBuddy 与边界:案例、租户、未来方向#
MetaBuddy(健身/营养结构化数据:meals、nutrition、exercises)被 Charles Pierse 称为早期用户,用于压测 filter、date filter、aggregations 与跨 collection 问句(演讲者观点;无第三方案例稿或审计数据,无法核实业务成效)。租户(tenants)在客户端口述中被提及,无实现细节。未来方向包括更长时的 Research / reSearch 与 memory(访谈;客户端 v1.2.0 Research mode 已存在,与口述名称不完全一致)——非 GA 承诺。
访谈中「Agent 入门易、约八成时间在 edge case」与「一周上线生产 agent」的市场话术形成张力(演讲者观点)。若你方 eval 文化薄弱,Query Agent 只能缩短 Weaviate 查询编写,不能替代 任务级回归测试。
另:主持人曾预告结尾 eval hot take,成片在 MetaBuddy / 未来方向处结束,无独立 eval 专节——上文 BEIR 与自测清单是为弥补该缺口而写的工程建议,非节目结论。
若你要落地#
- 先选模式:终端用户要可读答案 → Ask + 检查
sources与is_partial_answer;已有生成栈 → Search,把searches当日志。 - 投资 schema:为 filter 字段写
description与合法值域;在 Sandbox(Usage)用控制台「Ask me something about your data」做冒烟,再迁 SDK。 - 把响应当契约测试:对关键问句断言
filters/aggregations形状,而非只断言final_answer文本。 - 自研 hybrid 基线:固定参数做对照,勿依赖未链接的 BEIR 数字。
- 规划成本与轮次:Ask 4× 请求计费;多轮
ChatMessage会放大调用次数——在网关设预算与超时。
参考与延伸阅读#
- Query Agent 概述(docs.weaviate.io)
- Query Agent 使用说明:Ask、Search、会话、Inspect responses
- Query Agent 产品页与定价
- weaviate-agents-python-client README
- v1.0.0 GA:弃用 run、V2 API、会话上下文
- AskModeResponse / SearchModeResponse 源码
- Weaviate in 2025(Query Agent GA 表述)
- Weaviate hybrid 检索
- Weaviate 属性 filter
- Weaviate 聚合
- RAG 原始论文(Lewis et al.)
- BEIR 基准论文
- Compound AI Systems(BAIR)
- 检索质量与 RAG 总览(Weaviate 博客)
- PyPI:weaviate-agents 包历史


