
Java 流、并发与 HTTP 客户端:那些「能跑」却会在生产炸开的写法#
日常业务代码里,三类 API 最容易让人产生虚假安全感:Comparator 与排序、ConcurrentHashMap 与并发聚合、Stream 与集合变换。它们语法简洁、单线程测试往往绿灯,却在高负载、多线程或升级 JDK 后暴露出性能退化、数据丢失或连接池耗尽。
更棘手的是,这些问题很少以编译错误形式出现:Comparator 重复分配只会让 P99 悄悄抬高;containsKey 竞态只在双线程压测下丢一条记录;Stream 副作用在 JDK 17 上被优化掉、在 JDK 8 上却「正常」执行;HTTP 拦截器泄漏要等连接池打满才在监控上显形。若团队没有把这些模式编码进评审清单或静态规则,修复成本会指数级偏向生产排障一侧。
下文按工程主题拆解机制、给出最小改法,并标明哪些结论来自官方文档与 JEP/JBS、哪些来自排障经验(标注「演讲者观点」)。不追求 API 全景,只聚焦「写法合法、测试通过、上线仍可能炸」的交叉地带。
高频比较路径:别在 compareTo 里反复造 Comparator#
为什么#
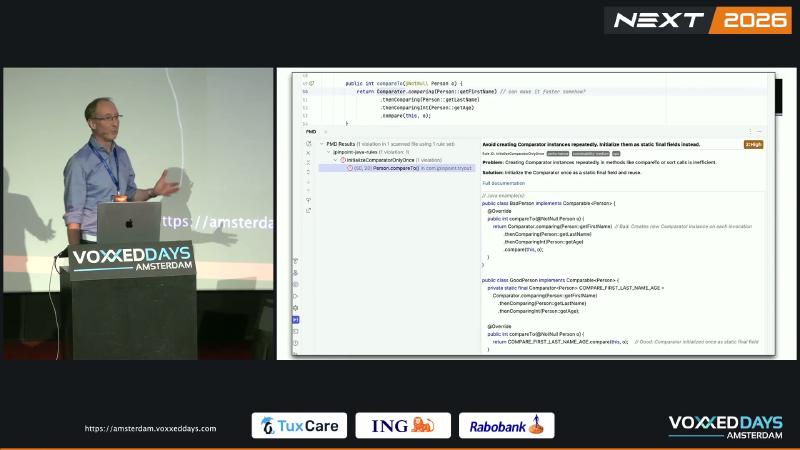
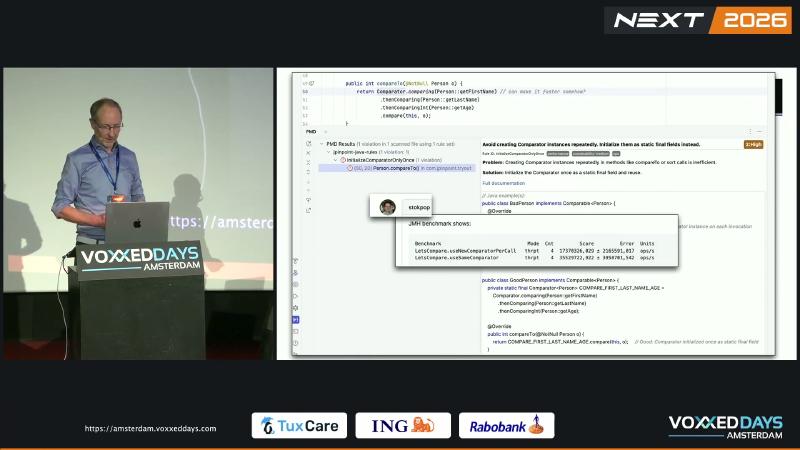
TreeSet、Collections.sort 等结构在插入或排序时会大量调用 compareTo。若每次比较都执行 Comparator.comparing(...).thenComparing(...).thenComparingInt(...),comparing 与链式 thenComparing 会反复分配对象,增加 GC 与 CPU 开销。PMD jPinpoint 规则 InitializeComparatorOnlyOnce 将此类写法标为性能隐患;演讲者在现场 JMH 对比中观测到约 2× 吞吐差距(演讲者观点,具体数据集未公开)。
机制与约束#
Oracle Javadoc 并未强制要求 static final,但 comparator 链每次调用都返回新实例是 API 契约。排序算法对同一 comparator 的调用次数可达 O(n log n) 量级,微小分配会被放大。规则文档建议:在 compareTo、排序回调等高频路径将 comparator 提升为 static final 字段复用。
怎么做#
// 坏:每次 compareTo 构造新链
public int compareTo(Person o) {
return Comparator.comparing(Person::getFirstName)
.thenComparing(Person::getLastName)
.thenComparingInt(Person::getAge)
.compare(this, o);
}
// 好:静态复用
private static final Comparator<Person> BY_NAME_AGE =
Comparator.comparing(Person::getFirstName)
.thenComparing(Person::getLastName)
.thenComparingInt(Person::getAge);
@Override public int compareTo(Person o) {
return BY_NAME_AGE.compare(this, o);
}
常见误区#
- 「lambda 方法引用已经够快了」——瓶颈在重复分配,不在 lambda 本身。
- 「只排序一次,无所谓」——若
compareTo嵌在TreeSet持续插入路径,代价会累积。 - 一次性、局部的 comparator 在特定场景可接受(规则文档亦注明 may be acceptable),但默认可复用就应复用。
- 把 micro-benchmark 当豁免理由——若 comparator 出现在热路径(缓存键排序、实时风控规则匹配),仍应先用 profiler 确认再决定。
ConcurrentMap:容器线程安全不等于复合操作原子#
为什么#
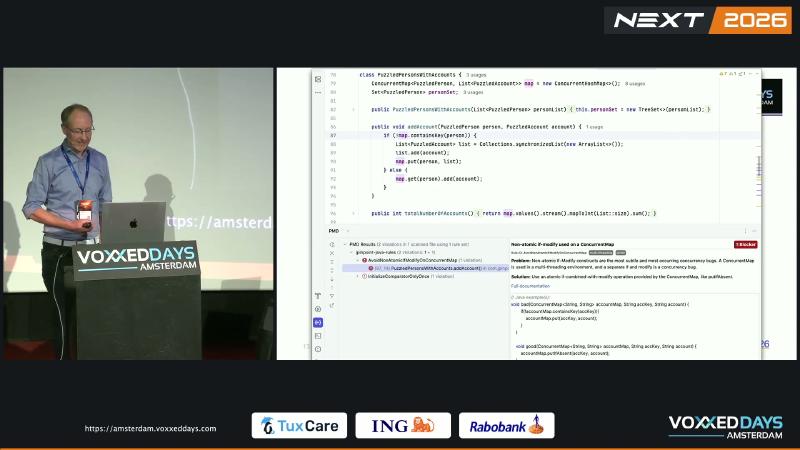
ConcurrentHashMap 保证单次 put、get 等操作的线程安全,但 if (!map.containsKey(k)) { map.put(k, v); } 是经典的 check-then-act:两步之间可被调度打断,两个线程可能都判定 key 不存在,各自 put,后写覆盖先写,导致账户或子列表丢失。演讲者演示中,单线程合计 6 个账户,双线程下出现 3、5 等不稳定结果(演讲者观点)。
机制与约束#
ConcurrentMap.putIfAbsent 文档写明:语义等价于 if (!containsKey) put else get,except that the action is performed atomically。同理,computeIfAbsent 将「检查 + 创建」合并为原子步骤。

怎么做#
// 坏:非原子 if-modify
if (!map.containsKey(person)) {
List<Account> list = Collections.synchronizedList(new ArrayList<>());
list.add(account);
map.put(person, list);
} else {
map.get(person).add(account);
}
// 好:原子创建再追加
map.computeIfAbsent(person,
p -> Collections.synchronizedList(new ArrayList<>()))
.add(account);
常见误区#
- 「用了
ConcurrentHashMap就线程安全了」——仅保证单操作,复合逻辑仍需原子 API。 computeIfAbsent只解决 entry 创建;value 若是共享可变集合,列表本身的add仍需同步或线程安全容器(上例用Collections.synchronizedList与 map 原子创建互补)。- 误以为
putIfAbsent与get+put完全等价——返回值语义不同,需读文档再选。 - 在
synchronized块里手写 check-then-act——能工作但锁粒度粗;优先用 map 自带原子方法,锁只保护 value 内部结构。
Stream 副作用:forEach 填外部集合与「能跑」的函数式假象#
为什么#
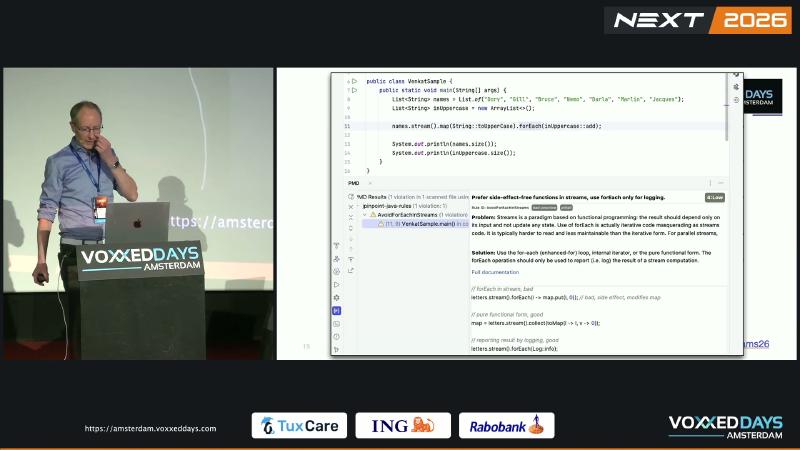
names.stream().map(String::toUpperCase).forEach(externalList::add) 把命令式副作用塞进声明式 pipeline,可读性差,也与 java.util.stream 包 SideEffects 文档 倡导的无副作用风格冲突。PMD jPinpoint AvoidForEachInStreams 将其标为 iterative code masquerading as streams code,建议改用 collect / toList(),或退回 enhanced-for。
机制与约束#
Stream 的中间与终端操作不保证按你想象的顺序、次数执行;并行时副作用还会引入数据竞争。规则措辞比 Javadoc 更严:forEach 仅应用于 logging/reporting(引用 Effective Java Item 46)。Oracle 文档允许 println 等无害调试副作用,但不鼓励用 forEach 做聚合。
怎么做#
// 坏
List<String> out = new ArrayList<>();
names.stream().map(String::toUpperCase).forEach(out::add);
// 好
List<String> out = names.stream()
.map(String::toUpperCase)
.toList();
常见误区#
- 「
forEach也是终端操作,和collect一样」——语义上forEach面向消费,collect面向归约;聚合应选后者。 - 把
peek当调试万能钥匙——peek同样可能被优化掉(见下一节)。 - 需要命令式逻辑时,enhanced-for 往往比「伪 Stream」更清晰。
Stream.count() 与 pipeline 省略:副作用不保证执行#
为什么#
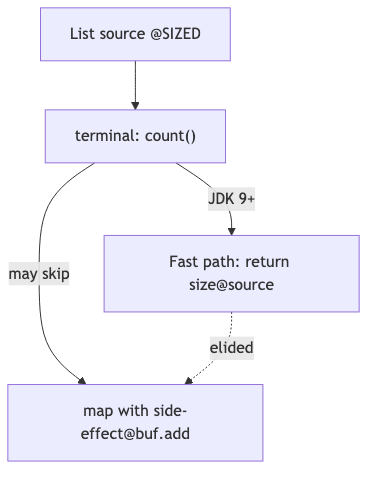
当源集合大小已知、中间 map 不改变元素个数时,Stream.count() 的 API Note 写明:实现可以不执行整条 pipeline,直接从源计算 count。中间步骤里的副作用——例如在 map 里 list.add(name)——可能被跳过。典型 puzzle:7 个名字经 toUpperCase 后,长度大于 4 的应写入 buf,观众多猜 buf.size()==4,实际在较新 JDK 上常为 buf 空、count==7(演讲者演示)。
机制与约束#
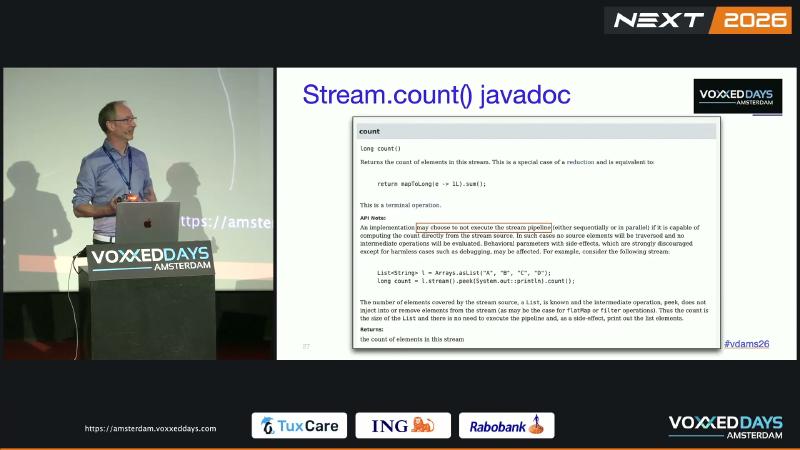
Java SE 21 SideEffects 节明确:「behavioral parameters are always invoked» 不成立——实现可 elide operations (or entire stages) 若证明不影响结果。OpenJDK JDK-8067969 在 JDK 9 为 SIZED Stream 引入 count() 优化(fixVersions: [9])。Java 8 的 count() Javadoc 无「may choose to not execute the pipeline」表述,package-summary 亦无 elide 段落;同一写法在 8 上更可能执行中间步骤,但即便在 JDK 8 也不应依赖副作用。
怎么做#
List<String> buf = new ArrayList<>();
long count = names.stream()
.map(String::toUpperCase)
.map(name -> {
if (name.length() > 4) buf.add(name); // 不保证执行
return name;
})
.count();
// 较新 JDK:buf 可能仍为空,count == names.size()
需要同时计数与收集时,应显式拆分或使用 collect/teeing,勿把 count() 当「顺便跑一遍 pipeline」的触发器。
JDK 版本差异与可复现#
同一类在不同 JDK 上对比 buf.size() 与中间 println 次数:
/usr/libexec/java_home -v 1.8 --exec java -classpath . com.example.StreamCountSimple
/usr/libexec/java_home -v 21 --exec java -classpath . com.example.StreamCountSimple
未核实边界:JDK 8 各 update 是否 backport 该优化,未在 release notes 中确认;CI 应覆盖目标运行时 JDK,不能只用开发机 JDK 8 绿灯就假定生产 JDK 21 行为相同。
从规范角度,Arrays.asList(...).stream().peek(System.out::println).count() 是 Javadoc 给出的标准反例:peek 不改变元素个数,终端 count() 可直接读源大小。你的业务 map 若只做过滤性变换(不改变流长度),就落在同一优化类别里。若确实需要副作用,应使用不承诺融合的终端操作(如 collect)或显式 for 循环,把「执行次数」写进语义而非赌实现。
常见误区#
- 「我本地跑过,副作用一定执行」——规范允许省略,且版本间实现不同。
- 「用
parallelStream就不会优化掉」——并行只增加竞态风险,不保证副作用。 - 在
filter/map里改外部状态——PMDAvoidSideEffectsInStreams同样拦截。
parallelStream 与非线程安全可变集合#
为什么#
parallelStream() 使用 ForkJoinPool.commonPool() 并行切分任务。parallelStream().forEach(mutableArrayList::add) 让多线程同时写 ArrayList——文档写明 not synchronized,结构修改须外部同步。结果间歇性少元素(6 而非 7)是确定性并发 bug,不是「偶发 glitch」。演讲者观点:有团队上线前仅改几个字符加 parallel 即引发间歇性生产问题。
机制与约束#
PMD AvoidMutableCollectionInParallelStreamForEach 描述:multiple threads access an unguarded shared variable。并行流仅在大集合、重 CPU 每元素工作且经实测更快时才值得考虑(AvoidParallelStreamWithCommonPool 建议 Always measure if really faster)。
怎么做#
// 坏
names.parallelStream()
.map(String::toUpperCase)
.forEach(inUppercase::add);
// 好:无共享可变状态
List<String> inUppercase = names.parallelStream()
.map(String::toUpperCase)
.toList();
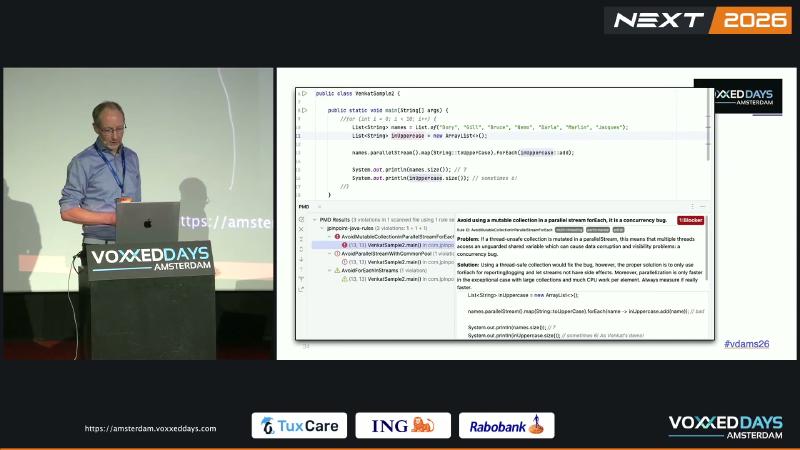
常见误区#
- 「数据量小,并行更快」——任务切分与合并开销常抵消收益。
- 共享
ConcurrentHashMap做累加——单操作安全,复合get+put仍可能丢更新;应用ConcurrentHashMap的原子合并 API 或collect并发收集器。 - 默认 common pool 与业务线程池争抢——IO 密集场景尤需警惕。
- 认为
toList()在并行下也不够安全——JDK 16+ 的toList()返回不可变列表,收集过程由 Stream 框架协调,与forEach手写 add 本质不同。
Spring ClientHttpRequestInterceptor:抛异常前必须 close()#
为什么#
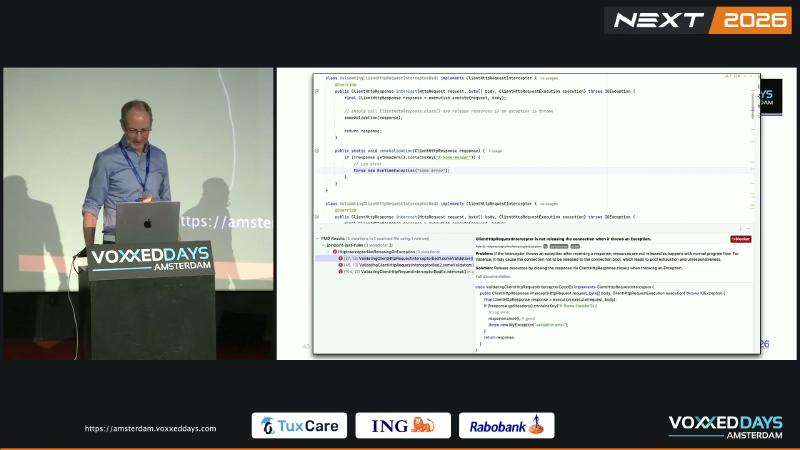
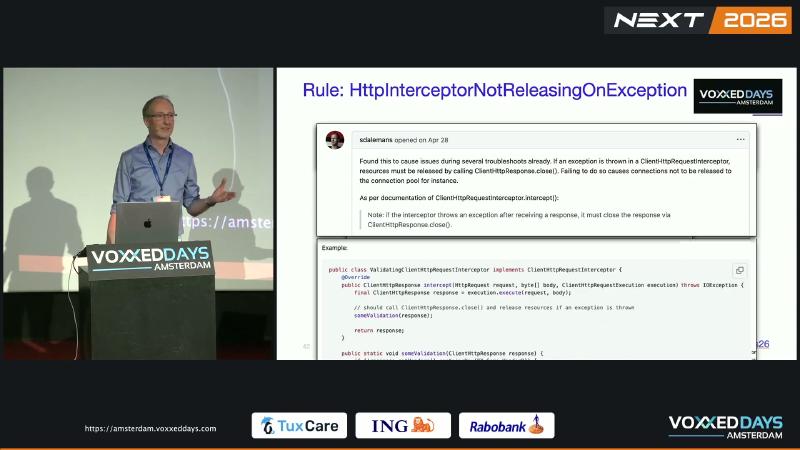
ClientHttpRequestInterceptor.intercept() 在 execution.execute() 拿到 ClientHttpResponse 后,若校验失败直接 throw,而未 response.close(),底层 HTTP 连接可能无法归还连接池,最终出现 pool exhaustion、请求挂起。演讲者观点:多次排障与一次支付类 outage 根因与此相关。Spring Javadoc 原文:if the interceptor throws an exception after receiving a response, it must close the response via ClientHttpResponse.close()。
机制与约束#
ClientHttpResponse 文档:must be closed, typically in a finally block。ClientHttpRequestExecution 仅有 execute(HttpRequest, byte[]),不存在 cancel() 之类替代释放手段。PMD 规则 HttpInterceptorNotReleasingOnException 将未 close 标为连接泄漏风险。
资源链路大致是:execute 从池借连接 → 响应体挂在本线程 → 正常路径由调用方消费并关闭;拦截器在「已借未还」态抛异常,若跳过 close(),池认为连接仍占用,新请求阻塞等待,表现为超时或线程堆积。该机理由规则文档阐述;Spring 接口文档只规定 close 义务,不展开池实现细节——但义务本身是硬性契约。
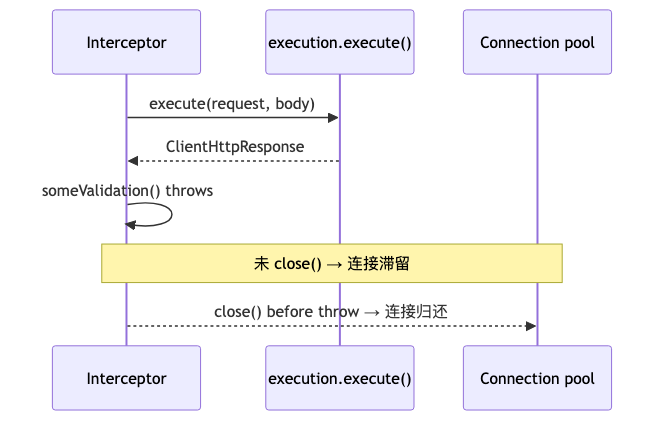
客户端改法#
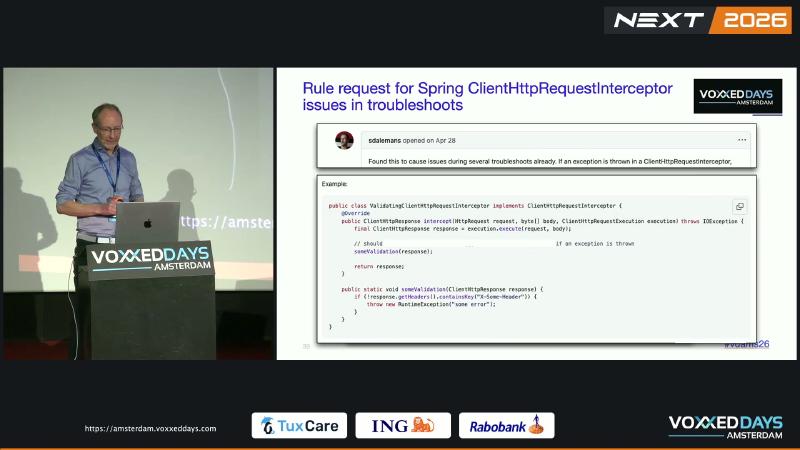
// 坏:校验失败直接抛,未 close
public ClientHttpResponse intercept(HttpRequest req, byte[] body,
ClientHttpRequestExecution exec) throws IOException {
ClientHttpResponse response = exec.execute(req, body);
someValidation(response); // 可能 throw
return response;
}
// 好:抛前释放
public ClientHttpResponse intercept(HttpRequest req, byte[] body,
ClientHttpRequestExecution exec) throws IOException {
ClientHttpResponse response = exec.execute(req, body);
if (!response.getHeaders().containsKey("X-Some-Header")) {
response.close();
throw new IOException("validation failed");
}
return response;
}
服务端与装配(最小上下文)#
// 注册拦截器
@Bean
RestTemplate restTemplate(List<ClientHttpRequestInterceptor> interceptors) {
RestTemplate rt = new RestTemplate();
rt.setInterceptors(interceptors);
return rt;
}
// 服务端:返回待校验头,便于集成测试拦截器行为
@GetMapping("/api/account")
ResponseEntity<String> getAccount() {
return ResponseEntity.ok()
.header("X-Some-Header", "ok")
.body("balance");
}
常见误区#
- 「异常会触发框架清理,不用管」——Spring 接口把 close 义务写在拦截器契约里。
- 「只 log 不抛就安全」——若已读取 body 且不再传递 response,仍须按客户端实现文档关闭。
- 混淆规则名
HttpInterceptorNotReleasingOnException与旧称HttpInterceptorNotReleasingConnectionException(仓库 pmd7 分支实际名称)。
把排障结论写进静态分析:PMD jPinpoint 与左移防障#
为什么#
上述陷阱在代码评审中易被放过:写法「能跑」、单测覆盖不足、JDK 版本与生产不一致。开源规则集 PMD-jPinpoint-rules 将多年性能与故障分析沉淀为 PMD 7 规则,覆盖 comparator 分配、并发 map、Stream 副作用、并行流可变集合、HTTP 拦截器等,可接入 IntelliJ PMD 插件、Maven maven-pmd-plugin 与 Sonar。演讲者观点:生产 incident 的用户体验与排障成本远高于 CI 阶段修复;方法论是 load test、code scan、incident → rule 的反馈环(README 亦写 distilled from analyzing performance problems and failures)。
怎么做#
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-pmd-plugin</artifactId>
<configuration>
<rulesets>
<ruleset>jpinpoint-rules.xml</ruleset>
</rulesets>
</configuration>
</plugin>
较新规则(如 InitializeComparatorOnlyOnce)在 pmd7 分支;集成时对照仓库 README 与 releases 选版本。
常见误区#
- 「规则太多,全关」——可按类别渐进启用,优先并发与资源泄漏类。
- 仅扫 master 分支旧 ruleset——pmd7 才含 HTTP、Comparator 等较新规则。
- 把静态分析当唯一防线——须结合目标 JDK 的集成测试与压测;规则无法覆盖所有运行时语义。
- 期待规则替代 Code Review——静态分析应降低漏网概率,不能替代对业务并发模型的理解。
落地顺序建议#
若资源有限,可按风险优先级分批启用:先 HTTP 拦截器 close 与 ConcurrentMap 非原子 if-modify(数据与可用性);再 并行流可变集合 与 Stream 副作用(并发与 JDK 迁移);最后 Comparator 静态复用(性能)。每引入一类规则,用一周时间消化存量告警,避免一次性洪水导致团队关规则。
参考与延伸阅读#
- Comparator — Java SE 21 API 文档
- ConcurrentMap.putIfAbsent — 原子语义说明
- ConcurrentMap.computeIfAbsent — 原子创建模式
- java.util.stream 包 SideEffects — 副作用与优化边界
- Stream.count() — pipeline 可省略的 API Note
- OpenJDK JDK-8067969 — SIZED Stream count 优化
- ArrayList — 非线程安全说明
- ForkJoinPool.commonPool — 并行流默认线程池
- ClientHttpRequestInterceptor — 异常时须 close 的契约
- ClientHttpResponse — 必须关闭的响应体
- PMD-jPinpoint-rules — 规则集仓库与集成说明
- jPinpoint JavaCodePerformance — 性能与并发规则文档
- jPinpoint JavaCodeQuality — Stream 与代码质量规则
- Stream.count() — Java SE 8 文档对照
- java.util.stream SideEffects — Java SE 9 起 elide 表述


