
把 JFR 事件流交给 AI:集中式 JVM 监控与 JMX 自愈的工程路径#
微服务故障排查里,最耗时的往往不是打开一份 JDK Flight Recorder(JFR)录制,而是判断「该看哪台 JVM、哪段时间」。-XX:StartFlightRecording 配合 jcmd dump、再用 Java Mission Control 人工分析,在单体式应用上够用;一旦 order-service 的延迟来自 customer-service 或 product-catalog,工程师逐个登录、拉文件、对齐时间轴时,根因窗口往往已经关闭。
Oracle Java Platform Group 工程师 Yagmur Eren 与 Joakim Nordström 在 Jfokus 2026 上演示了一条替代路径:各 JVM 用 RecordingStream 持续向中央服务推送精选事件,再由 LangChain4j 多 Agent 解读、判定,并通过 JMX 远程执行有限自愈动作。该方案把 JFR 当作持续telemetry而非事故后取证,把 AI 当作结构化推理层而非聊天框;二者通过明确的 schema、工具调用与人机确认策略衔接。下文按工程主题拆解机制;演示数值与模型选型标注来源,API 行为以 JDK 21 文档为准。

被动 dump 为何在微服务场景失效#
为什么#
JEP 328 把 JFR 做成 JDK 内置、低开销的诊断设施,java 手册页 也支持启动时 -XX:StartFlightRecording=。问题在于操作模型:dump 是事后快照,跨服务因果链需要多份录制在时间上与业务请求对齐。演讲用虚构的 Galaxy Cafe 订单拓扑说明:order、customer、product-catalog、shipping 各自跑在容器 JVM 上,瓶颈可能在任意一跳(演讲演示场景,非公开基准)。
机制与约束#
传统路径:jcmd <pid> JFR.dump → 下载 .jfr → JMC 分析。该模型假设工程师已锁定嫌疑服务。分布式链路下,order-service 的 CPU 升高可能只是下游 HTTP 放大的症状;等确认「不是本服务」再去别的机器 dump,异常可能已消退。Interplanetary Galactic Coffee Day 这类流量尖峰场景里,问题可能在数十秒内自愈,留给人工 dump 的重叠窗口极窄。
集中式流式监控的目标是把「采集」前置为常态,把「解读」交给可编排的软件层。监控服务侧可同时保留原始事件用于事后审计,与 LLM 摘要并行——AI 加速 triage,不替代合规留存。
怎么做#
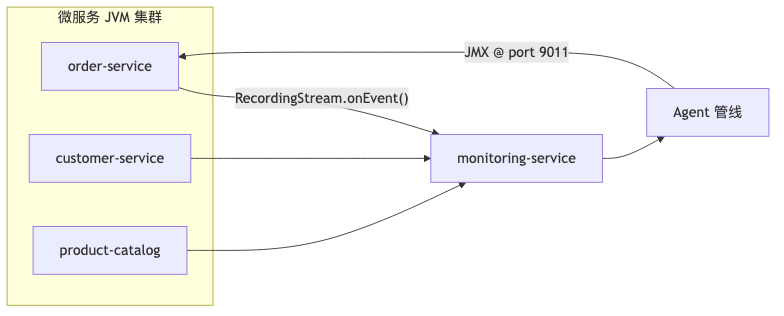
架构上改为:每个微服务 → 中央 monitoring-service → AI 分析管线 →(可选)JMX 动作。传输层在演示中为 HTTP 逐条 POST;生产可换消息队列或 gRPC,JFR API 本身不规定传输协议。
常见误区#
- 认为「开了 JFR 就等于可观测」——未集中汇聚时,跨服务关联仍靠人工。
- 把 AI 解读当成 JMC 替代品——LLM 输出需结构化约束与人机确认,不能替代原始事件存档。
- 忽略演示拓扑与真实生产的差距——端口、认证、留存策略均需单独设计。
用 JFC 控制事件订阅与传输开销#
为什么#
EventStream 允许对全部事件注册通用 onEvent(Consumer)。默认 Configuration 模板启用大量事件类型;若每条事件都 HTTP 上报,微服务集群会产生可观 fan-out(演讲者观点:默认配置约九十类事件,具体数字未在 jfr(1) 手册中核实)。官方性能说明建议:对已知事件名优先使用 onEvent(String, Consumer),而非在通用 handler 里过滤。
机制与约束#
jfr(1) 规定设置键格式为 <event-name>#<setting-name>=<value>,例如 jdk.ThreadCPULoad#enabled=true。Configuration.getSettings() 返回 Map<String,String>,可遍历 #enabled 键决定订阅集合。RecordingStream.startAsync() 异步消费,不阻塞业务线程。
怎么做#
监控侧按服务下发精简 JFC(演示片段):
jdk.ThreadCPULoad#enabled=true
jdk.ObjectAllocationSample#enabled=true
jdk.ExceptionStatistics#enabled=true
微服务侧选择性注册 handler:
Configuration config = Configuration.create(configReader);
RecordingStream recording = new RecordingStream(config);
for (var e : config.getSettings().entrySet()) {
if (e.getKey().endsWith("#enabled") && "true".equals(e.getValue())) {
String eventName = e.getKey().split("#")[0];
recording.onEvent(eventName, monitoringClient::handleEvent);
}
}
recording.startAsync();
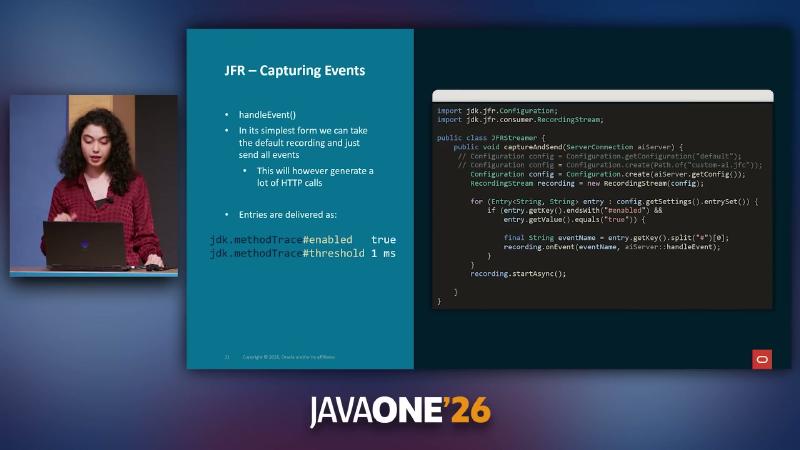
#enabled true 的项,再 recording.onEvent(eventName, handler) 与 startAsync()。
监控服务 handleEvent 侧(演示为 Spring Web 端点,非 JFR 标准)接收 JSON 后入队,由 AgentWorkflowService 异步触发 Agent 管线——避免在 JFR 回调线程里同步调用 LLM。
注意:Configuration.create() 接受 Reader 或 Path,无 create(String) 重载;远程下发须转成 Reader。可用 jfr metadata 子命令核对事件是否存在于目标 JDK 构建中。
常见误区#
- 直接
onEvent(e -> forward(e))转发全量——网络与序列化成本随事件类型线性膨胀。 - 只开事件、不设
threshold——如jdk.ThreadCPULoad#threshold=1 ms可进一步降噪(JFC 语法支持)。 - 假设 JFR 端过滤等于监控侧零成本——
handleEvent内的 JSON 序列化与批处理策略仍须优化。
Java Agent 非阻塞接入与集中配置#
为什么#
多实例手工改启动参数、嵌入 RecordingStream 代码,运维成本高。Java Instrumentation 允许在 premain 挂接逻辑,且 java.lang.instrument 要求 premain 尽快返回,避免拖慢 Spring Boot 等框架启动。
机制与约束#
-javaagent:agent.jar=options 在 main 之前执行。演示约定 options 为 baseUrl,serviceName(自定义格式,非 JVM 标准)。Agent 在独立线程拉取监控服务的 GET /configuration(带 ServiceName 头),加载 classpath:{serviceName}.jfc,再启动 JFRStreamer。同一 JVM 常并行暴露 JMX(演示端口 9011),二者无 API 级绑定。
怎么做#
java -javaagent:jfr-agent.jar=http://monitoring:8080,order-service \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9011 \
-jar order-service.jar
public static void premain(String args, Instrumentation inst) {
var cfg = parseArgs(args);
new Thread(() -> new JFRStreamer().captureAndSend(
new ServerConnection(cfg.baseUrl(), cfg.serviceName())), "jfr-streamer").start();
}

Configuration.create(aiServer.getConfig()) 与集中配置端点配合。
常见误区#
- 在
premain同步连接 HTTP——启动超时或监控不可达会阻塞进程拉起。 - 生产沿用演示的 JMX「无 SSL、无认证」——仅限本地;远程监控须 TLS 与凭证(通用 JMX 实践)。
- 忘记 Agent 与业务类加载器隔离——JFR 消费代码应尽量少依赖应用类。
JMX 运行时控制面与 MBean 发现#
为什么#
检测异常后,仅告警仍要人工登机器改配置。高峰场景下 order-service 需从逐条 HTTP 拉商品(SINGLE)切到批量(BATCH);product-catalog 需 clearCache 清空搜索缓存。演示通过 DynamicMBean 把 BatchEnabled 属性与 clearCache 操作暴露给远程监控。
机制与约束#
ManagementFactory.getPlatformMBeanServer() 注册 ObjectName,如 com.galaxycafe.orders.config:type=SelfHealing,service=order-service。监控侧 JMXConnectorFactory 连接 service:jmx:rmi:///jndi/rmi://host:9011/jmxrmi,queryNames(null,null) 枚举 MBean,再 getMBeanInfo 读取属性与操作元数据。type=SelfHealing 为演示过滤约定,非 JMX 标准类型。
怎么做#
微服务注册:
ObjectName name = new ObjectName(
"com.galaxycafe.orders.config:type=SelfHealing,service=order-service");
server.registerMBean(new BatchConfig(), name);
监控侧发现:
JMXConnector c = JMXConnectorFactory.connect(
new JMXServiceURL("service:jmx:rmi:///jndi/rmi://order-host:9011/jmxrmi"));
for (ObjectName mbean : c.getMBeanServerConnection().queryNames(null, null)) {
if ("SelfHealing".equals(mbean.getKeyProperty("type"))) {
catalog.add(mbean, c.getMBeanServerConnection().getMBeanInfo(mbean));
}
}

clearCache 操作与 BatchEnabled 属性,分别对应 invoke 与 getAttribute。
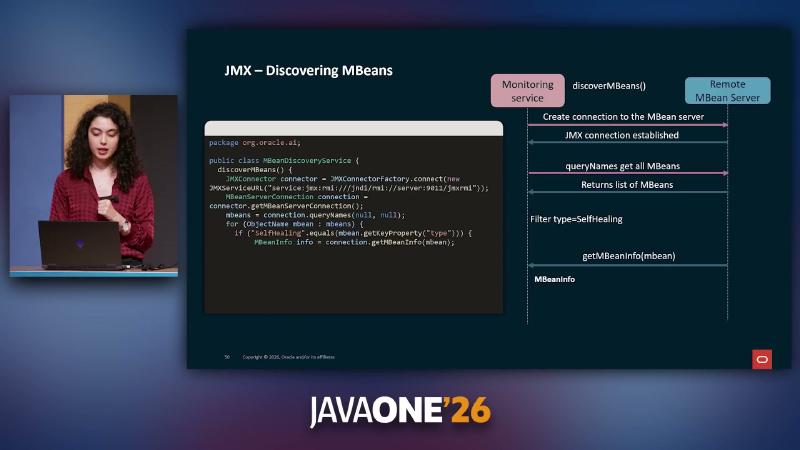
MBeanDiscoveryService 经 JMXConnectorFactory.connect 与 queryNames 发现 SelfHealing MBean。
常见误区#
- 把 JMX 当配置中心——无版本审计与变更回放,宜限「应急开关」类操作。
- 未限制
invoke权限——任何能连 9011 的客户端都可执行操作。 - 假设
queryNames一次足够——滚动发布后应定期刷新 catalog。
为 LLM 标注 JMX 动作语义#
为什么#
SelfHealer Agent 需要知道「能对哪个服务做什么」。把 MBean 元数据原样塞进 prompt,模型难以区分 clearCache(需人工确认)与 ENABLE_BATCH(可自动)。演示在 Descriptor 自定义字段 ai.action、ai.confirmation,注入 system prompt。
机制与约束#
DescriptorSupport.setField 可挂到 MBeanOperationInfo(impact=ACTION)与 MBeanAttributeInfo。字段语义属演示约定,JMX 规范不识别 ai.* 命名。ai.confirmation=true 表示 human-in-the-loop;false 允许自动执行(仍建议外层审计)。
怎么做#
Descriptor d = new DescriptorSupport();
d.setField("ai.action", "CLEAR_CACHE");
d.setField("ai.confirmation", "true");
new MBeanOperationInfo("clearCache", "Clears search cache", null,
"void", MBeanOperationInfo.ACTION, d);
Descriptor ad = new DescriptorSupport();
ad.setField("ai.action", "ENABLE_BATCH");
ad.setField("ai.confirmation", "false");
new MBeanAttributeInfo("BatchEnabled", "boolean",
"Enable batch product fetch", true, true, false, ad);

descriptor.setField("ai.action", "CLEAR_CACHE") 与 ENABLE_BATCH 标注动作语义。
常见误区#
- 只标注 action、不标注 confirmation——自动清缓存类操作风险高。
- 假设 LLM 会读 JavaDoc——须把 descriptor 序列化成简明动作表。
- 把 descriptor 当授权——真正执行前仍要在服务端校验 action 白名单。
多 Agent 分工与工具增强#
为什么#
单一 LLM 同时做 JFR 解读、异常判定、运维决策,准确性与可解释性往往不足(演讲者观点)。演示拆为三个 LangChain4j @Agent 接口:JfrDataProcessor 压缩原始事件,AnomalyDetector 判定,SelfHealer 选动作。@MemoryId 按 serviceName 隔离会话记忆,避免 order 与 catalog 上下文串扰。
机制与约束#
langchain4j-agentic 模块在官方文档中标记为 experimental,API 可能变更。JfrDataProcessor 用 @Tool 补充领域知识:readJfrDocumentation 加载 JfrEventDescriptions.md;fetchOlderEvents 在证据不足时扩展时间窗。工具类名与 Markdown 文件均为演示实现,非框架内置。
ProcessedJfrContext 演示字段包括 summary、eventTypes、evidence、processedMetrics。健康运行时摘要会描述「moderate CPU across thread pools」、C2 CompilerThread 的 JIT 活动、byte array 分配模式——供下游 Agent 引用而非直接读原始事件流。
怎么做#
public interface JfrDataProcessor {
@Agent("Process raw JFR events into concise LLM-ready context")
ProcessedJfrContext process(@MemoryId String serviceName,
@V("context") String context);
}
class JfrDataProcessorTools {
@Tool("Read JFR event documentation for event types you're analyzing")
String readJfrDocumentation() { return loadClasspath("JfrEventDescriptions.md"); }
@Tool("Fetch older JFR events before earliest timestamp in current window")
String fetchOlderEvents(String serviceName, String beforeTimestamp) {
return repo.findOlder(serviceName, beforeTimestamp).toJson();
}
}

JfrDataProcessor 的 @Agent 与 @UserMessage 将原始 JFR 转为 LLM 可读上下文。
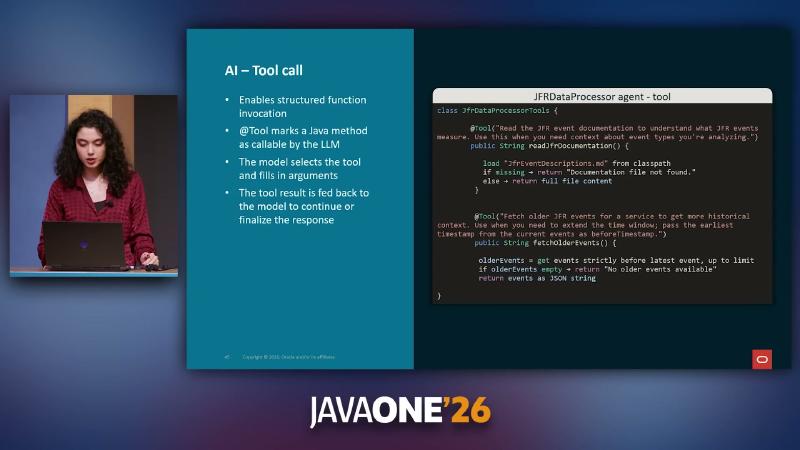
JfrDataProcessorTools 中 @Tool 标记 readJfrDocumentation,供模型按需查阅事件说明。
常见误区#
- Agent 切得越碎越好——跨 Agent 状态传递成本上升,宜按「可验证输出边界」拆分。
- 不给工具只给原始 JSON——token 爆炸且模型缺乏
jdk.ThreadCPULoad等语义。 - 忽视
@MemoryId存储增长——长时运行须设 TTL 或摘要策略。
结构化检测输出与工作流编排#
为什么#
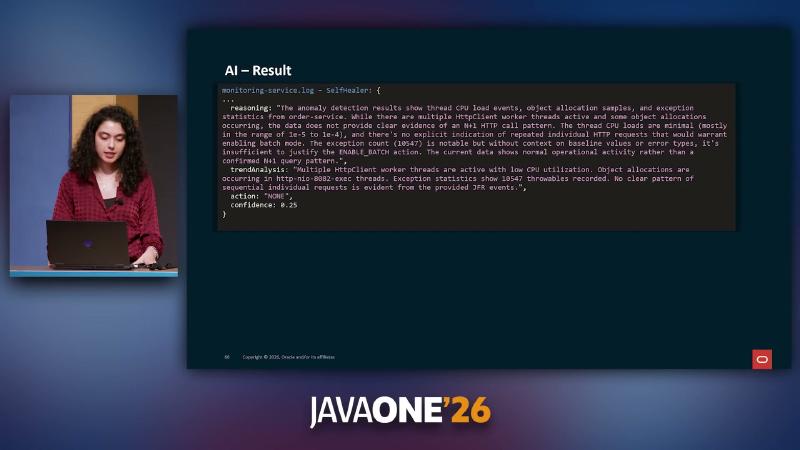
LLM 容易在证据不足时「自信结论」。演示用 @Description 约束 POJO:reasoning 先陈述依据,再输出 anomalyDetected、confidence(0.0–1.0)、moreDataRequired。字段顺序依赖 prompt 与模型行为,@Description 不保证 JSON 物理字段序(未独立核实)。
机制与约束#
AgenticScope 在子 Agent 间共享状态。loopBuilder 让 DataProcessor 与 AnomalyDetector 迭代,直至 !moreDataRequired && confidence >= 0.85(演示阈值);sequenceBuilder 再串联 SelfHealer。当前 Javadoc 写法与演讲幻灯略有差异:循环名用 .name("detection-loop"),读状态用 readState("detection") 而非 scope.get。
怎么做#
public static class DetectionOutput {
@Description("What is wrong, or confirmation the system is healthy")
public String reasoning;
public boolean anomalyDetected;
public double confidence;
public boolean moreDataRequired;
public Map<String, Object> keyMetrics = Map.of();
}
var detectionLoop = AgenticServices.loopBuilder()
.name("detection-loop")
.maxIterations(5)
.exitCondition(scope -> {
DetectionOutput d = scope.readState("detection");
return d != null && !d.moreDataRequired && d.confidence >= 0.85;
})
.subAgents(dataProcessor, anomalyDetector)
.build();
var pipeline = AgenticServices.sequenceBuilder()
.subAgents(detectionLoop, selfHealer)
.build();
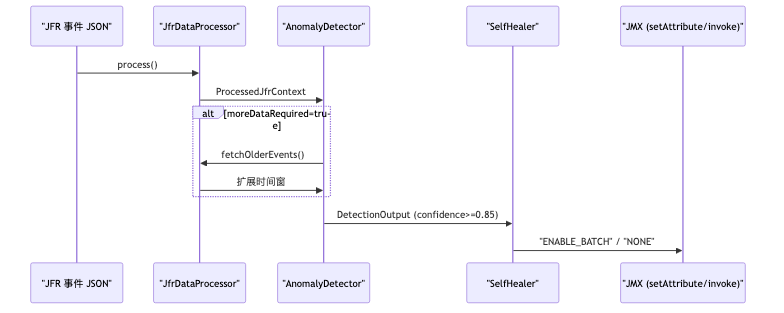
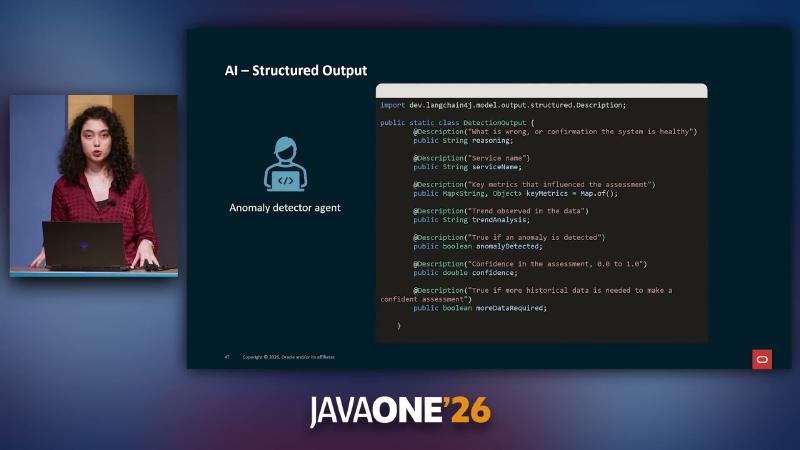
DetectionOutput 含 reasoning、confidence、moreDataRequired 等字段,服务 AnomalyDetector。
常见误区#
- 单次快照即触发告警——应先走
moreDataRequired与 tool 拉历史。 - 把
confidence当统计置信区间——实为 LLM 自评,须用结构化输出与离线评测校准(演讲者观点:链式生成可缓解过早承诺,无官方文档对应)。 - 复制演讲
loopBuilder("name")签名——应对照当前 LangChain4j Javadoc 调整。
端到端自愈与生产边界#
为什么#
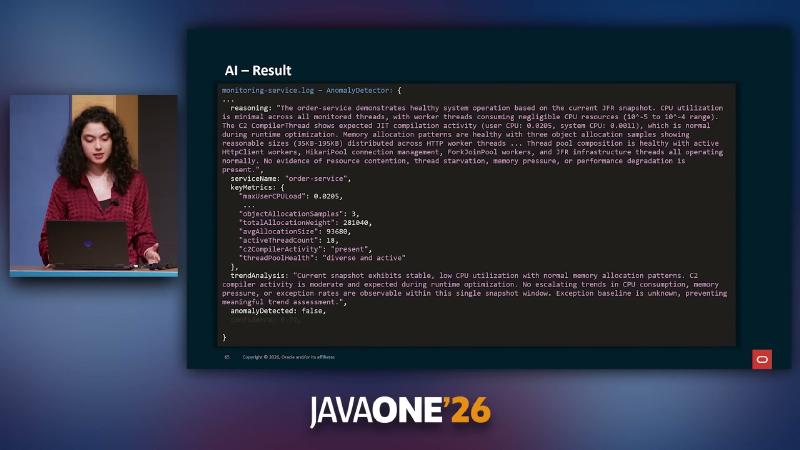
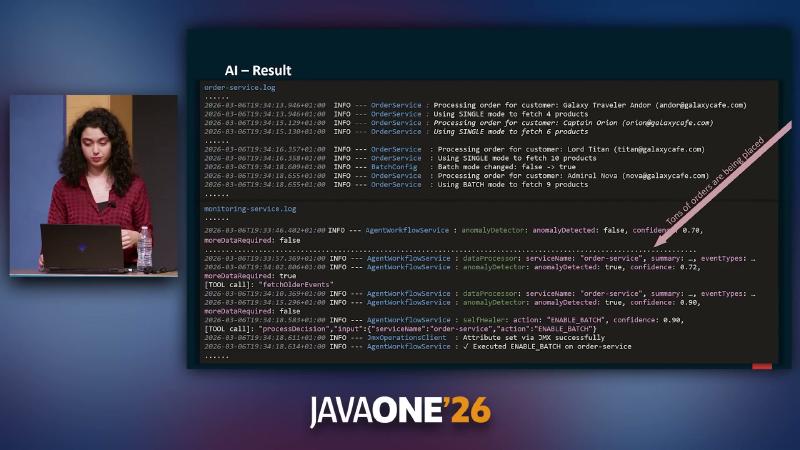
检测与决策须可观测。演示在合成高峰流量下,根因叙事为 order-service 以 SINGLE 模式逐条 HTTP 拉取商品,在流量尖峰下形成类 N+1 压力。AgentWorkflowService 日志显示:AnomalyDetector 先报 anomalyDetected: true, confidence: 0.72,并触发 [TOOL call]: "fetchOlderEvents";扩展窗口后置信度升至 0.90。SelfHealer 输出 action: "ENABLE_BATCH", confidence: 0.90,JmxOperationsClient 记录 Attribute set via JMX successfully,order-service 日志由 Using SINGLE mode to fetch 4 products 变为 Using BATCH mode(整条链路来自演讲 OCR/日志,无公开仓库可复现)。
机制与约束#
健康快照下 JfrDataProcessor 可产出含 jdk.ThreadCPULoad、jdk.ObjectAllocationSample、jdk.ExceptionStatistics 的摘要,C2 CompilerThread 升高可被解读为正常 JIT 活动。证据不足时 SelfHealer 返回 action: "NONE"、confidence: 0.25。模型选型为 Anthropic Haiku 4.5(演讲者观点);温度、误报率、SLA 未验证。
怎么做#
@Tool("Execute healing action on target microservice via JMX")
void processDecision(String serviceName, String action) {
if ("ENABLE_BATCH".equals(action)) {
jmx.setAttribute(serviceName, "BatchEnabled", true);
}
}
可观测日志(演示):
INFO OrderService : Using SINGLE mode to fetch 4 products
INFO BatchConfig : Batch mode changed: false -> true
INFO OrderService : Using BATCH mode to fetch 9 products

常见误区#
- 把演示当成生产 SLA——缺少认证、批处理传输、回放测试与人工审批流。
- 见到 JIT 线程 CPU 就告警——须结合
ThreadCPULoad阈值与业务指标。 - 自愈动作无回滚——
BatchEnabled切回 SINGLE 须有对应 runbook 或自动回退条件。 - 把虚构监控大屏(
ALL SYSTEMS NOMINAL)当成已交付产品——仅为叙事道具,无对应开源实现。
若要在自有环境试验,最小路径是:单 JVM 启用精简 JFC + RecordingStream → 监控服务落库 → 单 Agent 做结构化摘要;确认 token 预算与延迟后再引入 JMX 发现与多 Agent 循环。讲者另有一篇 GC 日志 + ML 调优 G1 的论文(见文末 Inside.java 链接),主题相关但与本架构无直接代码依赖。
参考与延伸阅读#
- Flight Recorder 故障排查概述 — Oracle JDK 21
- RecordingStream API — JDK 21
- EventStream API — JDK 21
- Configuration API — JDK 21
- jfr(1) 命令手册 — 事件设置语法
- JEP 328: Flight Recorder
- java(1) 手册 — StartFlightRecording 与 javaagent
- java.lang.instrument 包说明 — JDK 21
- DynamicMBean API — JDK 21
- JMXConnectorFactory API — JDK 21
- Java Management Extensions (JMX) 指南
- LangChain4j Agents 与 Agentic 工作流教程
- LangChain4j Tools(Function Calling)教程
- LangChain4j Structured Outputs 教程
- Inside.java:JVM 调优与机器学习论文介绍(讲者 Yagmur Eren)


