
Java 的内存效率:移动式 GC、堆旋钮与 profiling 优先#
任务管理器里 Java 进程占着几 GB 堆,常被贴上「臃肿」标签。若把视角从「绝对 GB 数」切换到「内存管理占用的 CPU 周期」,结论会不同:JDK 默认路径上的 G1 与可选 ZGC 均属 moving(移动式) 收集器——它们刻意用更多 RAM 换取更低的内存管理 CPU 开销。Inside Java Podcast 59 中,Oracle Java 架构师 Ron Pressler 将这一取舍概括为「把 RAM 芯片当作程序加速器」;GPU 加速会被称赞,RAM 加速却被称作 bloated(演讲者观点)。本文按平台设计主题拆解机制,定量经济性数字与云 sizing 经验单独标注来源边界;GC 算法细节以官方 JEP 与 HotSpot 源码为准。

移动式垃圾收集:用 RAM 换 CPU#
为什么#
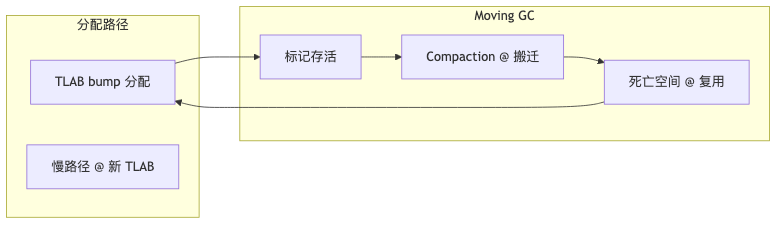
手动 malloc/free、引用计数与非移动式 mark-sweep 都要为「复用一块地址」持续付费:释放、合并空闲块、对抗碎片。移动式收集器换了一条路——在 compaction 阶段把存活对象搬到连续区域,死亡对象所占空间可被后续分配直接覆盖,分配侧接近线性推进。Andrew W. Appel 在 1987 年论文 Garbage collection can be faster than stack allocation 中论证:特定条件下 GC 可比栈分配更快;Ron 引用此文说明 moving collector 并非「事后补丁」,而是降低内存管理 CPU 开销的算法选择(「RAM 当加速器」为演讲者归纳,非论文原文)。
JEP 333 将 ZGC 描述为 compacting collector,通过 object relocation 回收;JEP 248 自 JDK 9 起把 G1 设为 server 默认。相对地,已移除的 CMS(JEP 291 弃用,JDK 14 删除)在 JEP 333 Alternatives 中明确 no support for compaction——与 moving 路线分属不同设计空间。官方移除 CMS 的动机是缺维护者与 G1/ZGC/Shenandoah 可替代(演讲者观点:moving 路线整体更优,属 Ron 归纳,非 JEP 363 原文)。
机制与约束#
| 维度 | Moving(G1 / ZGC) | Non-moving(如 CMS、Go mark-sweep) |
|---|---|---|
| RAM | 更高:保留垃圾、预留 compaction 空间 | 通常更低 |
| 内存管理 CPU | 可通过堆大小调节,倾向更低 | free/碎片成本更直接 |
| 运维旋钮 | -Xmx 等堆边界 ≈ 「内存旋钮」 | 演讲者观点:缺乏同等旋钮 |
即便把旋钮拧到「尽量省内存」,moving collector 仍可能比非移动方案占更多 RAM,但换来更高吞吐(演讲者观点)。经济权衡上,RAM 通常比 CPU 便宜;Ron 在 JavaOne 配套 talk 中给出「多用 10× RAM 换 5% CPU」的量级(本播客未复述,数字未独立核实)。
G1 与 ZGC 不宜混为一谈:JEP 189 写明 G1 做 evacuation 但 does not do concurrent evacuation;ZGC 的 concurrent relocation 是另一档实现。JDK 27 上 JEP 523 拟让 G1 成为所有环境默认 GC(Integrated),延续 moving 主路径。
怎么做#
选型与迁移:-XX:+UseConcMarkSweepGC 在 JDK 14+ 被忽略并回退默认 GC(JEP 363)。新部署优先 G1;低延迟场景评估 ZGC(JDK 15 GA,JEP 377)。无 API 级 breaking change,影响在运维侧。
# 查看当前 GC(JDK 9+)
java -XX:+PrintFlagsFinal -version 2>&1 | grep Use.*GC
# 显式启用 ZGC(示例)
java -XX:+UseZGC -Xmx4g -jar app.jar
常见误区#
- 把「Java 占内存」当成实现疏忽——在 moving 模型下,部分 RAM 是换 CPU 的 deliberate trade-off。
- 将 G1 与 ZGC 的并发移动能力划等号——evacuation 时机与停顿特征不同。
- 用 JEP 363 原文证明「moving 必然更优」——官方写的是维护性与替代品,整体优越性属架构师归纳。

整机视角:RAM 与 CPU 的配比#
为什么#
后端 sizing 若只看「这个 pod 有几 GB」,容易误判。Ron 将关键指标定为 每 CPU core 对应多少 RAM(演讲者观点),灵感来自 Oracle GC 团队成员 Erik Österlund 在 SIGPLAN ISMM 研讨会上的 keynote(keynote 具体论点未检索到可核对全文;Österlund 身份见 JEP 377 Reviewed by)。直觉是:进程若持续占满某 core 的 CPU,同期几乎没有其他程序能有效使用该 core 上的 RAM——「100% CPU + 1% RAM」不会获得额外奖励分(演讲者观点)。
Kubernetes Pod 资源管理 用 request/limit 描述 CPU 与内存,并无「每 core 至少 1 GB」的全局硬性规范。Ron 称最小云实例常见 ≥ 1 GB RAM / core(演讲者观点;云厂商 SKU 随时间变化,需自行核对)。Nicolai 追问 Java 是否在「几 GB」小实例上吃亏,Ron 否定并强调看 RAM/core 而非绝对 GB(具体 benchmark 在 JavaOne talk 中,播客未给出)。
机制与约束#
瓶颈转移逻辑:当 CPU 是稀缺资源时,用闲置 RAM 缓解 GC 与分配压力,符合一般性能工程(双方共识性讨论)。历史语境上,Java 曾以桌面应用为主,用户盯着任务管理器看 RAM;服务端更看吞吐、延迟与成本曲线(演讲者观点)。
怎么做#
在 K8s 或 VM 上同时声明 CPU 与 memory request,避免只压 memory limit 却 CPU 饱和:
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
memory: "4Gi"
结合 -Xmx 时,宜让堆上限低于容器 memory limit,为 metaspace、线程栈、堆外与 GC 预留 headroom——比例因 workload 而异,无单一官方公式。
常见误区#
- 用绝对 GB 横向比较 Java 与 Go/Rust——忽略 RAM/core 与 workload 是否 compute-bound。
- 把 Ron 的 1 GB/core 当作 K8s 规范——Kubernetes 文档无此全局下限。
- 将
https://www.ismm.org/当作内存管理 ISMM——该域名指向山地医学学会;正确入口为 SIGPLAN ISMM。

分配模型:TLAB、compaction 与堆旋钮#
为什么#
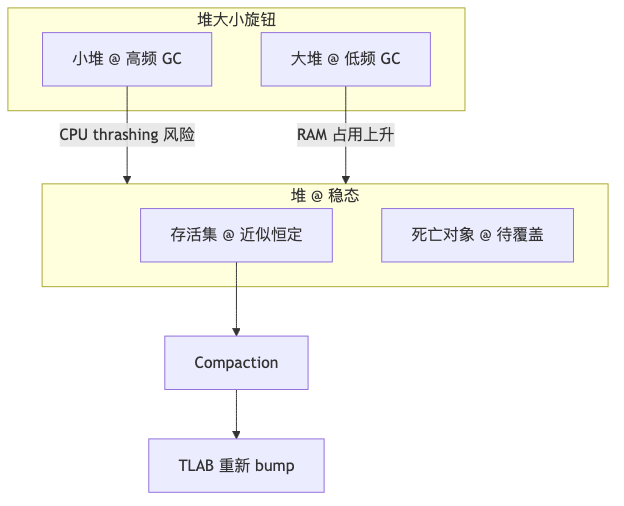
Java 堆分配没有逐对象 free 语义:线程在 ThreadLocalAllocBuffer(TLAB)内通过 _top 指针前移完成分配(内联实现),速度接近线性 bump;释放由 GC 在 compaction 时批量处理。Ron 将稳态下 存活对象数量大致恒定 作为推论前提:GC 对存活集的工作量与垃圾量弱相关,堆越大 → 填满前可分配越多 → collection 频率约与堆大小成反比(理想化稳态推论,无对应 JEP)。堆加倍,同类 preservation 工作约减半;堆 ×10,约少做 10 次——反例是堆长期运行在 90–99% 容量导致 thrashing(通用 GC 经验,HotSpot 未写入该百分比)。
机制与约束#
ZGC 侧已有局部「旋钮」演进:JEP 351 的 -XX:ZUncommit 可将未用堆归还 OS;JEP 377 引入 -XX:SoftMaxHeapSize 软上限——不等于用户完全不再设 -Xmx。Ron 称 GC 团队正努力消除手动设堆,让收集器自行决定最优堆,用户只表达「更偏 RAM 还是更偏 CPU」,ZGC 可能先行(演讲者观点;截至 2026-06-10 无消除 -Xmx 的 GA JEP)。
低层语言可用 arena(大块 buffer + 内部 bump,阶段结束一次性释放)逼近类似效率;Ron 称 Zig 支持较好(演讲者观点)。JEP 454 的 Arena 定义 temporal bounds,与 Zig 式分配器 部分重叠、语义不完全等同。
怎么做#
观察分配与 GC 频率,再调堆——而非先抄「 industry 标准 ratio」:
# 启动时 JFR,观察 allocation 与 GC(JDK 11+)
java -XX:StartFlightRecording=filename=recording.jfr,duration=120s \
-Xmx2g -jar app.jar
# 运行中 dump
jcmd <pid> JFR.dump filename=recording.jfr
ZGC 尝试软上限与归还(需 JDK 15+ 且 -Xms 不宜等于 -Xmx,否则 ZUncommit 等效禁用,见 JEP 351):
java -XX:+UseZGC -Xmx8g -XX:SoftMaxHeapSize=4g \
-XX:+ZUncommit -XX:ZUncommitDelay=300 -jar app.jar
常见误区#
- 认为
SoftMaxHeapSize已取消手动堆配置——ergonomics 仍围绕-Xms/-Xmx。 - 「我自己写 free 逻辑就能比 GC 好」——一般等于自实现一套内存管理机;专家级 malloc 投入巨大(Ron 引述 Stefan Johansson 等,演讲者观点)。
- 将 FFM
Arena与 Zig arena 划等号——JEP 454 管的是 segment 生命周期边界。

跨语言对比:碎片、allocator 与「没有免费午餐」#
为什么#
「C/C++ 更省内存」常来自 micro-benchmark,而非长跑生产形态。Ron 指出 C/C++ 同样面临碎片与长期退化:运行一小时后堆行为可与初期截然不同(演讲者观点;Go GC Guide 对 non-moving 路径有官方描述)。C/C++ 可切换 malloc 实现,效果堪比切换 GC;现代 allocator 与 GC 一样复杂(演讲者观点)。
Go GC Guide 写明 Go 为 mark-sweep、non-moving GC,并预分配地址空间以限制碎片。与已死的 HotSpot CMS 类比有助于直觉,但 Go 并发 mark-sweep 与 CMS 算法 并不等同(演讲者观点:Go 式路径与 CMS「类似」)。Non-moving 路径省 RAM,但 无法像 moving collector 那样用 RAM 换 CPU——与 P01 论点方向一致,定量外推仍属观点。
机制与约束#
微观层面,同一地址 cache hit 与 miss 可导致约 100× 延迟差,且取决于其他线程行为(演讲者观点)——孤立 micro-benchmark 难以外推全程序。经验型 C++ 程序员或能规避部分碎片,但复杂度分布在编译器、CPU 微架构、缓存各层(演讲者观点)。
怎么做#
跨语言评估应固定 workload 与观测窗口,而非单次 malloc 循环:
# 对比时记录 RSS 与 CPU 时间(示例)
/usr/bin/time -l ./native_app
/usr/bin/time -l java -Xmx2g -jar app.jar
对 JNI/FFM 边界,用 JEP 454 Arena 明确堆外生命周期,避免与 JVM GC 语义混用。
常见误区#
- 用同等大小对象的 malloc/free 循环结论推广到 Java——对象尺寸与生命周期分布不同则不可外推。
- 将 Go non-moving 与 CMS 划等号——前者仍活跃且实现不同。
- 忽视 allocator 也是长期状态机——切换
malloc实现不等于「零成本换引擎」。


基准测试会骗人:profiling 优先#
为什么#
性能社区常说 benchmarks lie(演讲者观点;JMH README 强调 pitfalls 但未使用该措辞)——问题常是指数级外推谬误,而非表格数字造假。同等大小对象反复 malloc/free 的 micro-benchmark 显示 C++/Rust 与 Java 同速且更省 RAM,换到真实程序(不同尺寸、生命周期)不可外推(演讲者观点)。
比较性第三方 benchmark(「A 比 B 快」)对 非作者程序 几乎无用;有用的是 对自己代码 做基准,且理解机制与 fast path。Micro-benchmark 在当代整体相关性下降——编译器对孤立子例与全程序上下文可生成截然不同代码(演讲者观点)。
机制与约束#
推荐工作流(演讲者观点):
- 先 profile 全程序(JFR、Java Mission Control),找 hot path。
- 对 hot path 上的具体实现可用 JMH 比较候选。
- 必须回到全程序验证——否则违反 Amdahl 定律:优化占 1% 时间的路径,整体最多 ~1% 提升。
JMH 降低死代码消除等陷阱,但专业外观易导致 @Benchmark + 表格即收工;Aleksei Shipilev 强调数字是起点、需理解成因(Nicolai 转述,非 Shipilev 本人发言)。对他人 API(如 Stream)写 micro-benchmark 博客可能 有害(Ron 倾向;演讲者观点)。
真正拖慢 Java 应用的通常 不是 stream vs loop,而是错误算法/数据结构、过度同步、I/O(数据库等)——多数信息系统 非 compute-bound(演讲者观点)。
怎么做#
# 启动录制(见 java(1) 手册)
java -XX:StartFlightRecording=filename=recording.jfr,duration=60s -jar app.jar
# 运行中 dump(见 jcmd(1) 手册)
jcmd <pid> JFR.dump filename=recording.jfr
# 文本查看热点
jfr print --events jdk.ExecutionSample recording.jfr
JMH 应独立 Maven/Gradle 工程运行,避免 IDE 直接跑主类(README 称 results are less reliable)。
常见误区#
- 用 JMH 分数直接证明语言优劣——外推边界未定义时结论无效。
- 跳过全程序验证——hot path 误判时优化方向全错。
- 把 profiling(自己的程序)与 benchmarking(常指别人的程序)混为一谈——「每个程序都是 snowflake」(演讲者原话意象)。




Structured Concurrency 路线图花絮#
本节为播客结尾 off-topic,非内存主题主体;API 细节以 JEP 为准。
为什么#
Structured Concurrency 将子任务生命周期绑定到父作用域,简化取消与错误传播。Ron 录制时(JDK 26 刚发布)称团队原计划在 JDK 27 将其定为 permanent(演讲者观点)。
机制与约束#
截至 2026-06-10,JEP 533 将 API 交付为 JDK 27 第七轮 Preview(Completed 指标该 JEP 交付完成,非 API 转正),Summary 原文:preview once more in JDK 27。与 Ron 播客意向 冲突——应以 JEP 为准。历史轮次:JEP 480(JDK 23 第三轮)、JEP 499(JDK 24 第四轮)、JEP 525(JDK 26 第六轮)。JEP 12 preview API 默认禁用。
怎么做#
javac --release 27 --enable-preview Main.java
java --enable-preview Main
import java.util.concurrent.StructuredTaskScope;
try (var scope = StructuredTaskScope.open(
StructuredTaskScope.Configuration.newBuilder().build())) {
var sub = scope.fork(() -> fetchData());
scope.join();
return sub.get();
}
生产使用需跟踪 JEP 状态;JDK 28+ 仍可能继续 preview 或最终转正(尚无 Final JEP)。
常见误区#
- 写「JDK 27 Structured Concurrency GA」——JEP 533 仍为 preview。
- 引用 JEP 499 为「Third Preview」——第三轮为 JEP 480(JDK 23)。

参考与延伸阅读#
- Inside Java Podcast 59 — Java is Memory Efficient — 节目主页与摘要,moving GC 与 RAM/CPU 贸易论出处
- JEP 248 — G1 默认垃圾收集器(JDK 9) — server 环境默认 moving 路径起点
- JEP 333 — ZGC 实验性引入(compacting/relocating) — ZGC 移动式语义与 CMS 无 compaction 对比
- JEP 377 — ZGC 生产特性(JDK 15 GA) —
UseZGC与SoftMaxHeapSize - JEP 351 — ZGC 归还未用堆内存 — ZUncommit 与
-Xms/-Xmx约束 - JEP 363 — 移除 CMS(JDK 14) — CMS 迁移与标志忽略行为
- JEP 523 — G1 全环境默认(JDK 27) — 小内存场景默认 GC 延伸
- JEP 533 — Structured Concurrency 第七轮 Preview — JDK 27 API 状态(非 GA)
- Appel 1987 — GC can be faster than stack allocation — moving collector 理论早期文献
- HotSpot TLAB 源码 — 线程本地 bump 分配机制
- Go GC Guide — non-moving mark-sweep — 跨语言 non-moving 路径官方描述
- JMH 项目 README — 微基准工程隔离与 pitfalls
- java(1) 手册 — Flight Recorder 启动选项 —
-XX:StartFlightRecording可复现命令 - jcmd(1) 手册 — JFR.dump — 运行中 dump 录制
- SIGPLAN — International Symposium on Memory Management — 内存管理研讨会正确入口(非 ismm.org)


