
知识工程在 LLM 时代的再定位:符号骨架、神经弹性与企业护栏#
企业 AI 栈里,RAG、向量检索与 Agent 工具调用已属标配;与此同时,OWL 2 本体检索、生物医学本体、以及「先建模再推理」的知识图谱路线仍在运转。两条技术脉络长期平行,却在 LLM 普及后被迫回答同一组问题:自然语言里的概念能否被机器稳定地结构化?边缘案例出现时,类别定义如何修订?企业 Agent 在写库、发消息、调 API 时,符号护栏应落在哪一层?
Bradley P. Allen 的研究脉络(博士论文 Neurosymbolic Knowledge Engineering with Natural Language)把上述张力收束为一条工程命题:用神经网络处理开放域输入,用符号脚手架保留可审计的推理与治理。下文按机制拆解各层能力;凡未在 W3C 规范、论文或产品文档中逐条核对的主张,会标注为演讲者观点或开放问题。

知识图谱的形式化骨架:术语层、断言层与 subsumption#
为什么:若要把「类上的属性」自动传给「实例」,需要可计算的类层次与一致性检查,而非仅靠图数据库里的 HAS_TYPE 边。工业界常把知识图谱等同于「对象—类—关系」三元组视图;Allen 则强调其上是沿袭 Description Logic 传统的轻量逻辑叠层(logical overlay)——演讲者观点。
机制/约束:OWL 2 Primer 区分 terminological knowledge(术语/类定义)与 assertional knowledge(实例断言),对应 DL 社区惯称的 T-box 与 A-box。OWL 2 Direct Semantics 定义 Class Expression Subsumption:类表达式 (CE_1) 被 (CE_2) 蕴含,当且仅当其在所有解释下的扩展满足 ((CE_1)^C \subseteq (CE_2)^C)。OWL 2 Profiles Table 10 给出最坏情况复杂度——OWL 1 DL 的一致性、子类检查等为 NEXPTIME-complete。推理器因此侧重 modest inference(属性继承、子类推导),而非重型定理证明;Allen 肯定其二十年生物医学等领域工程价值,同时指出企业 ROI 论证仍是 heavy lift(演讲者观点)。
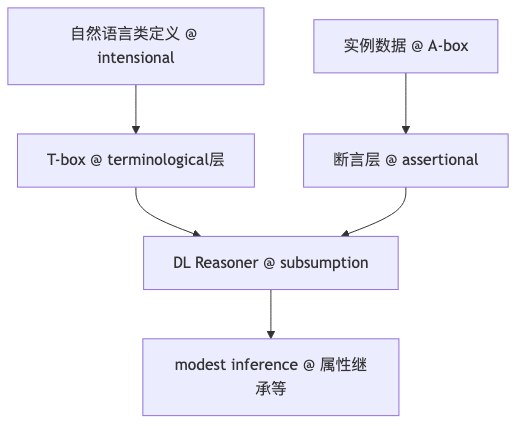
怎么做:以 SubClassOf(:Mother :Woman) 为起点,用 reasoner 验证 Mother 是否为 Person 子类;企业场景优先选定 OWL 2 EL / QL / RL profile 以控制推理成本,再决定是否引入更富表达力的构造。
常见误区:把图数据库的「类型边」等同于 OWL 子类关系——前者通常无全局一致性保证;Frank van Harmelen 被 Allen 引述的观点是,读者常把自然语言直觉「读进」图谱符号,造成符号义与形式义错位(引述学术观点;访谈未给出具体篇目 DOI,无法独立核验)。

描述逻辑的代价:expressiveness 与 tractability 的折中#
为什么:若允许任意一阶逻辑表达,推理可能不可判定或指数级爆炸;知识工程要在「能说清业务」与「算得完」之间取舍。
机制/约束:W3C Profiles 文档写明各 profile trades some expressive power for the efficiency of reasoning。Allen 将 90 年代 DL 社区的折中概括为 lossy formalization:自然语言概念中的细微差别在形式化时常被丢弃,以换取 soundness、completeness(在选定逻辑片段内)与 tractability——避免推理「等到热寂才返回」(演讲者观点;因果链为访谈归纳,非 W3C 原文)。
怎么做:选型时先问「需要哪类推理问题」——ontology consistency、class expression subsumption、instance checking——再对照 Profiles 复杂度表选 profile;对仅需层次分类的场景,不必上满 OWL DL。
常见误区:认为「上了知识图谱就有语义」——若 van Harmelen 式「读进」发生,形式推理再 sound 也可能与业务语义脱节。另一误区是期待 KG 原生处理 non-monotonic / defeasible 推理;Allen 指出该传统长期是符号路线的 showstopper,而生物医学等领域仍在几乎不解决可废止推理的情况下取得成果(演讲者观点)。
LLM 作为分类器:从内涵定义到边缘案例闭环#
为什么:经典知识工程要求专家把自然语言 intensional(内涵式,带 s)定义手工译为 DL 公理;Allen 认为 LLM 出现前,这一路径难以在实战中规模化(演讲者观点;未能从 ALLNKE.pdf 抓取全文以逐句证实实验细节——philpapers 链接返回挑战页)。
机制/约束:Allen 框架的核心动作是:用自然语言类规格直接生成 LLM-based classifier,输出带 rationale(分类理由),供人工或自动反馈以修订类定义;生成式路径成本高,可再蒸馏为 logistic regression 等轻量模型以规模化(字幕 ~12:32–12:52 可印证措辞,属访谈观点)。决策机制是概率性的,与人类 defeasible(可废止)推理更同构,而非经典单调演绎。
怎么做(极简示意):
1. 用 NL 写类定义:"重排器 = 对候选文档集合按相关性再排序的组件"
2. LLM 分类器对新对象(如某 multi-vector 模型)打标签 + 输出 rationale
3. 若 rationale 暴露定义漏洞 → 修订类定义 → 重新评估 held-out 边缘案例
常见误区:把一次 prompt 输出当作稳定本体——无 rationale 闭环则无法审计「为何归为此类」。另一误区是忽略蒸馏:全量调用 frontier LLM 做在线分类,成本与延迟通常不可接受。

向量检索、ColBERT 与动态类边界#
为什么:非结构化语料规模远超任何一次性能手工建模的覆盖范围;检索增强生成(RAG)把 parametric memory 与外部向量索引结合,成为 LM 社区与 KG 社区的事实交汇面。
机制/约束:ColBERT 以 late interaction 对 query/document 做 token 级多向量编码,经 MaxSim 聚合相似度。Khattab & Zaharia (2020) 给出两种部署:BM25 检索 top-1000 → ColBERT re-rank,或 ColBERT 端到端 full retrieval(经向量索引)。访谈中 Connor 口语化为「ColBERT 像 first-stage retriever 再 re-rank」(字幕 ~25:11);与论文默认 benchmark(BM25 一阶段)部分吻合,但并非「ColBERT 一阶段 + 另一重排器」的固定流水线——撰写架构文档时应以论文两种模式为准。Allen 认同的是更一般的 edge case → rationale → 修订类 闭环,而非为 ColBERT 背书具体 MRR 数字(演讲者观点)。

怎么做:生产环境常见 hybrid search(向量 + BM25)作一阶段,ColBERT 类模型作二阶段重排;类定义维护上,把「新检索架构是否仍算重排器」当作回归测试用例,而非静态枚举。
常见误区:把 ColBERT 同时当作一阶段与二阶段而无清晰索引策略——full retrieval 需专门多向量索引,与「拿 BM25 候选再重排」的运维成本不同。另一误区是认为检索指标可替代本体一致性检查——排序 MRR 与 OWL consistency 回答的是不同问题。
分布式语义:质心、主题建模与 LLM 的绕路#
为什么:在符号类不可用或维护成本过高时,工程师转向 distributional semantics——用共现统计或向量空间近似概念。
机制/约束:Word2vec 将词映射为连续向量;LDA 把文档建模为 topic 的有限混合。Allen 提出启发式:概念可视为其 extension(扩展)实例在向量空间中的质心;并可构造显式 范畴向量(二元 can-it-fly、数值 wheels、类别 maker 等)与对象嵌入对比(演讲者观点;非 LDA/Word2vec 论文标准术语)。纯聚类或 topic modeling 长期难点在于「簇是否有可命名的语义」——LDA 摘要强调 topic 的简短描述,并未解决自动语义标签问题。
怎么做:若需可解释范畴,维护显式特征向量并与 embedding 联合使用;若需开放域覆盖,以 LLM 生成簇标签或定义,但应保留人工抽检验证。
常见误区:把 topic 编号当作业务概念 ID——簇解释性不足会导致下游 Agent 误用。Allen 的条件判断是:LLM 把分布式表示与语言生成接口结合,似乎绕过了命名簇的难题,但是否兼得可解释性与覆盖度仍为 open question(演讲者观点)。

逻辑—语义传统与语用传统:LLM 所处的哲学位置#
为什么:工程师常在「模型输出是否真实」与「模型输出是否有用」之间摇摆;这对应哲学史上 逻辑—语义传统(真值、组合语义)与 语用传统(意义在用)的分野。
机制/约束:Frege 一脉经 Russell、Wittgenstein 至 Turing、Gödel,支撑了 自动定理证明 等「技术成功故事」——在需要 soundness 的封闭域推理中仍不可替代。Pragmatics 研究语境、用法与规约意义之外的传达。Allen 的诠释性框架是:LLM 生成流利语言但与经典 truth 脱节;若被正确引导,可成为语用传统「第一个可行的计算实现」(访谈观点;SEP 不会支持该强结论)。形式化应服务最终须人工「摇手柄」的严格推理,而非取代全程对话(演讲者观点)。
怎么做:Pipeline 分层——开放域对话用 LLM;涉及合规、权限、金融核算等步骤,将 LLM 输出译为可送入定理证明器或规则引擎的封闭片段(类型、单位、权限谓词)。
常见误区:用 chatbot 多轮闲聊替代结构化共识对话——Allen 认为当前交互缺乏服务于澄清概念、达成规范的结构,对话产出很少沉淀为可复用符号结构(演讲者观点)。

相关逻辑:paraconsistency、paracompleteness 与 LLM 输出#
为什么:LLM 常输出带概率、可撤回、彼此不完全一致的陈述;经典逻辑中矛盾 (A \land \neg A) 可推出任意 (B)(ECQ, ex contradictione quodlibet),与生产环境需求不符。
机制/约束:Paraconsistent logic 研究 non-explosive 后果关系,使矛盾不污染全部推理。Relevant logic 是其重要分支。Allen 在访谈中还提到 paracompleteness(容忍表示不完备)——该术语见于 annotated logic 文献,Allen 将其与 LLM「70% 可能」式陈述并置,设想嵌入符号推理流水线(演讲者观点;未找到 LLM+paracompleteness 主流产品实现文档)。
怎么做(概念层):将 LLM 输出标注置信度与来源,在矛盾检测时不立即 classical explode,而是隔离冲突命题、触发人工或高阶规则仲裁——工程上更接近 defeasible reasoning 与 truth maintenance 实践,而非直接部署 paraconsistent 演算。
常见误区:以为「容忍矛盾」等于「放弃一致性」——企业场景仍需对 写操作 与 权限决策 保持单调、可审计。另一误区是把认知主张(「人脑常带矛盾仍能推理」)当作可直接落地的逻辑定理。


神经搜索与企业 Agent:AlphaGo 类比的能指与边界#
为什么:企业知识 Agent 的工具调用循环可粗粒度看作状态转移;主持人将 MuZero 式「树搜索 + 学习到的世界模型」类比为企业写库、发消息等动作空间(主持人设问)。
机制/约束:AlphaGo 结合 value networks、policy networks 与 Monte Carlo tree search;AlphaZero 以 tabula rasa 自博弈统一多棋类;MuZero 在无环境动力学先验时仍用 tree-based search + learned model 达超人类水平。Allen 认同「搜索不仅适用于物理行动,也适用于推理空间」的类比,但承认对 RL 近期应用谱系「难以完全把握」;enterprise AI 架构如何落地仍是 excellent question——当前主流是 try and see what happens(演讲者观点)。三篇论文未讨论 Notion 写库、RBAC 等工作流。
怎么做:若借鉴搜索,优先在可模拟、可回放的子任务(查询规划、schema 导航)试 MCTS 或 beam search,而非一上来对世界模型全栈下注;Weaviate Query Agent 一类「无状态、自然语言写查询并导航 schema」产品与「带记忆、带规划的 Agent」形成形态对比(主持人产品描述;Query Agent 官方细节未验证)。
常见误区:把 MuZero 论文结果直接等同于企业 Agent ROI——棋类状态空间封闭、奖励稀疏清晰,与企业工作流不可比。另一误区是忽视 misalignment:Agent 目标与企业目标偏离时,搜索只会更高效地走向错误终点(演讲者观点)。

企业神经符号架构:神经弹性、符号护栏与问责#
为什么:神经网络擅长未见输入的泛化,企业却需要 norms、审计轨迹与权限边界——纯端到端模型难以单独承担。
机制/约束:Allen 倡导的 neurosymbolic 分工是:神经网络处理开放域感知与语言接口,符号脚手架承载 guardrails、governance、RBAC(NIST 将 RBAC 称为 advanced access control 的 predominant model 之一)。van Harmelen 等 A Boxology of Design Patterns for Hybrid Learning and Reasoning Systems 提供混合架构设计模式词汇,但未逐条映射到 Weaviate 对象级写权限(Connor 随口提及,非官方文档断言)。Allen 将当下称为 Cambrian explosion 式试错,架构问题「really need to be resolved」(演讲者观点)。
怎么做:至少分离三层——(1) 身份与角色层 RBAC;(2) 工具调用白名单与参数 schema 验证;(3) 高风险写操作的人工批准或回滚。神经部分负责提案,符号部分负责 allow/deny。
常见误区:把「加一段 system prompt 禁止越权」当作 RBAC——prompt 无执行层强制力。另一误区是认为更强基础模型会自然解决治理;Allen 最兴奋的走向反而是「如何问责地使用已出现的强大技术」(演讲者观点;核物理类比为修辞,非技术等价)。
两条个人主义路线的张力:先结构化 vs 按需结构化#
Allen 的个人知识管理是「大堆文件 + 搜索」,而非自建图谱(演讲者观点)——与其博士论文的高度形式化形成反差。Connor 转述 Groth / Bob van Luijt 路线:不预先结构化,由 LLM 结合上下文即时组织(主持人转述)。企业侧,Berners-Lee 式「全网结构化知识库」愿景未实现,而领域本体(如生物医学)仍成功;LLM 能否在保留语义的前提下动态结构化——Allen 明示为 open question。向量库支撑的 vector search 与持续索引更新,使知识系统更像 iterative, ongoing 过程,而非「一次建模、轻量维护」(演讲者观点);LLM 训练截止日期则放大持续修订压力。
对 AI 周期的判断上,Allen 认为历史常因高估能力而寒冬;深度学习 / LLM 后可能出现低估(Go 在 AlphaGo 前被估 20–25 年);短期内 AI winter 概率低,但是否泡沫仍为 open question(演讲者观点;scaling 边际递减对立面访谈未展开可复现实证)。
若你要落地#
- 先画推理问题清单:是要 subsumption / consistency,还是要语义检索 / 生成?再决定 OWL profile 与向量索引是否同库共存,避免用一种技术的指标伪装另一种需求。
- 把类定义当成可版本化的规格:用 NL 写清 intensional 定义,用 LLM 分类器 + rationale 回归边缘案例;检索组件(如 ColBERT 部署模式)变更时触发类定义复审。
- RAG 流水线写明两阶段角色:对照 ColBERT 论文区分 BM25→re-rank 与 full retrieval,勿把口语「一阶段检索」混为一谈。
- Agent 上线前先做符号护栏:RBAC、工具 schema 校验、写操作审计与回滚,比追加世界模型更紧迫;搜索/规划放在可回放子任务上试点。
- 标注开放域与封闭域边界:LLM 负责语用接口;涉及权限与核算的步骤,输出必须可译为封闭逻辑片段或显式 defeasible 规则集,并保留人工摇手柄环节。
参考与延伸阅读#
- OWL 2 入门:术语层与断言层划分
- OWL 2 直接语义:类表达式蕴含定义
- OWL 2 Profiles:表达力与推理复杂度表
- Allen 博士论文:神经符号知识工程(PDF)
- RAG 原始论文:检索增强生成架构
- ColBERT 论文:late interaction 多向量检索
- Weaviate 文档:hybrid search 概念
- Word2vec 论文:分布式词向量表示
- LDA 论文:主题建模与文档混合
- SEP:Frege 与形式逻辑起源
- SEP:语用学与意义理论
- SEP:次协调逻辑与 ECQ
- AlphaGo 论文:神经网络与树搜索结合
- MuZero 论文:无动力学先验的模型学习搜索
- NIST:RBAC 访问控制模型说明


