
解决 JVM Safepoint 延迟:从 EFS 集成到异步日志的探索之旅#
最近,我们升级到了 Java 17,我们的 k8s 运维团队进行了优化以集中应用日志收集。他们配置了所有 pod(可以理解为独立的 Java 微服务进程)将 JVM 日志收集到统一的 AWS EFS 服务(Elastic File System - 本质上是 NFS + S3 对象存储集群)。我们的 JVM 日志配置包括几个关键组件:
- GC 日志:
-Xlog:gc*=debug:file=${LOG_PATH}/gc%t.log:utctime,level,tags:filecount=50,filesize=100M - JIT 编译日志:
-Xlog:jit+compilation=info:file=${LOG_PATH}/jit_compile%t.log:utctime,level,tags:filecount=10,filesize=10M - Safepoint 日志:
-Xlog:safepoint=trace:file=${LOG_PATH}/safepoint%t.log:utctime,level,tags:filecount=10,filesize=10M - 禁用堆栈跟踪省略:这仅影响内部 JDK 异常,如 NullPointerException:
-XX:-OmitStackTraceInFastThrow(我们已经优化了应用以处理高错误量期间过多堆栈跟踪输出的性能压力)
实施这些更改后,我们遇到了一个特殊问题,有三种不同的表现,但都有一个共同症状:极其延长的 safepoint 持续时间。
1. Safepoint 日志显示所有线程到达 safepoint 的等待时间异常长(到达 safepoint:25+ 秒)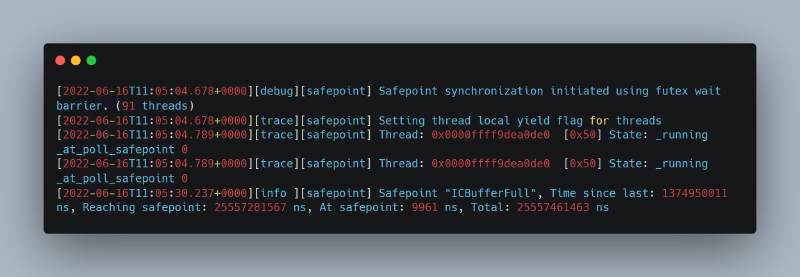
2. Safepoint 日志显示由于 GC 在 safepoint 花费的延长时间(在 safepoint:37+ 秒)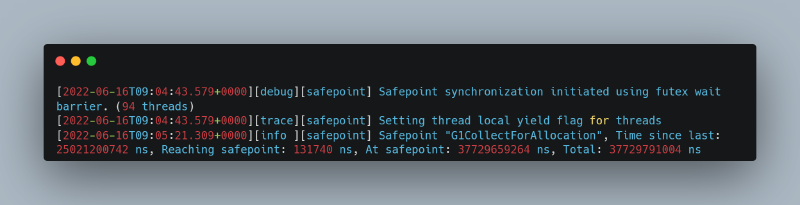
查看 GC 日志,Heap before GC invocations 和堆结构输出之间存在显著间隙: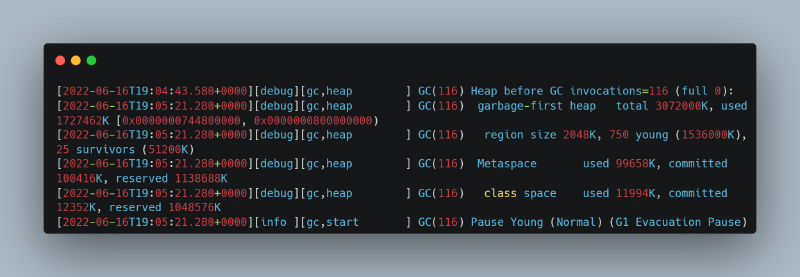
3. 另一个由于 GC 导致 safepoint 时间延长的实例,但在不同日志位置存在间隙(29+ 秒)
GC 日志显示堆结构输出之间存在大量间隔: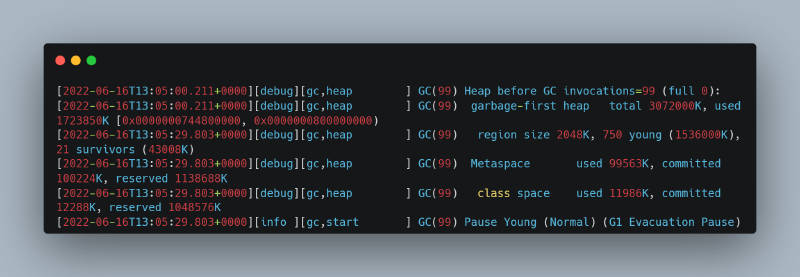
问题调查#
当 Java 应用线程集体处于 safepoint 时,它们实际上被冻结了 - 无法执行任何操作。这意味着依赖应用线程的监控(如 Spring Actuator 的 Prometheus 端点或 Skywalking 插桩等外部 JVM 监控)会变得盲目,只显示在 safepoint 期间调用的方法似乎花费了异常长的时间,而实际上这些方法并不是真正的瓶颈。
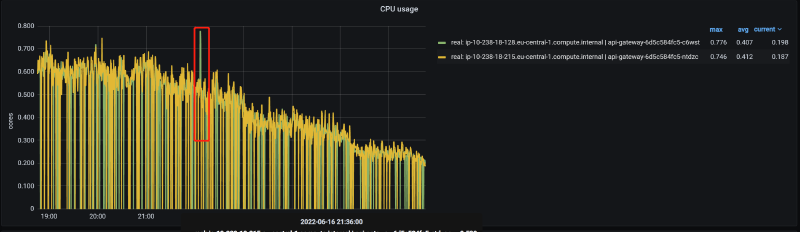
解决方案需要内部 JVM 线程监控机制,如 JVM 日志和 JFR(Java Flight Recording)。我们还使用了 async_profiler (https://github.com/jvm-profiling-tools/async-profiler/),因为在问题期间,我们注意到进程的 CPU 使用率(不是机器的,而是特指这个进程)会急剧飙升:
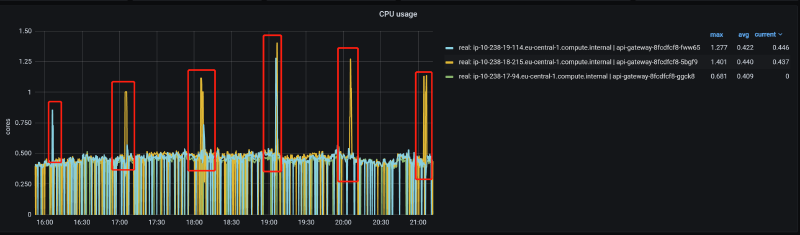
奇怪的是,在问题时间段通过 async_profiler 检查 CPU 使用率时,我们发现除了预期活动外:
在 safepoint 期间,日志记录似乎被中断了 - 这是一个非常不寻常的情况。这个观察很重要,原因如下:
对于第一种现象(等待所有线程进入 safepoint 的时间延长),我们通常期望看到连续输出显示哪些线程尚未进入 safepoint,如 JVM 源代码所示:
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/runtime/safepoint.cpp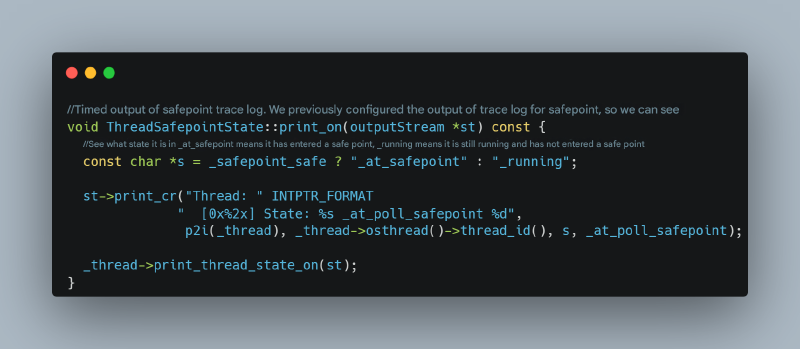
然而,在我们的第一种场景中,我们没有看到任何日志指示哪个特定线程导致了延迟。
对于第二种现象,JFR 没有显示任何特别耗时的 GC 阶段: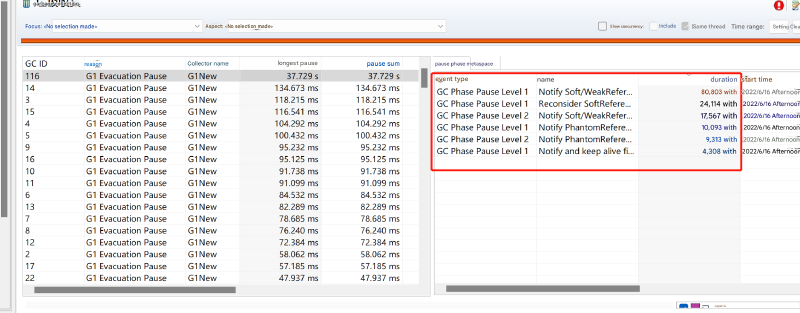
对于第三种现象,检查 JVM 源代码显示,在两个有显著间隙的日志之间,除了日志记录本身,几乎什么都没有发生。此外,所有问题事件都发生在每小时的 05 分钟标记附近。咨询我们的运维团队后,我们了解到这与每小时日志文件轮转和 EFS 同步同时发生(我们每小时生成一个日志文件),涉及大量文件 I/O(考虑到底层云服务架构,这可能涉及 EFS NFS 或网络对象存储,而不是传统的磁盘 I/O)。过多的文件 I/O 是否会阻塞 JVM 日志输出,从而冻结整个 JVM?
为什么 JVM 日志输出会阻塞所有应用线程?如果 JVM 线程在 safepoint 外输出日志时卡住,它只会影响自己,不会影响所有应用线程。然而,在 safepoint 期间,所有应用线程已经暂停。如果此时 JVM 线程在日志输出上被阻塞,它可能会阻止线程进入 safepoint 或导致 safepoint 持续时间延长。对于第一种现象,输出 JVM 日志的线程(不是应用日志 - 应用日志输出通常涉及原生文件 I/O 调用,这些调用被认为在 safepoint 中,不会造成问题)卡住,阻止该线程进入 safepoint。对于现象二和三,GC 线程在输出 JVM 日志时卡住,阻止 GC 完成。
让我们首先检查 JVM 源代码,确认阻塞的 JVM 日志输出是否确实会冻结 JVM。
JVM 日志输出源代码分析#
我们使用的是 Java 17,在此之前没有异步 JVM 日志输出。所以在以下源代码分析中,请忽略异步日志代码 - 这代表 Java 17 之前的日志输出行为:
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/logging/logFileStreamOutput.cpp
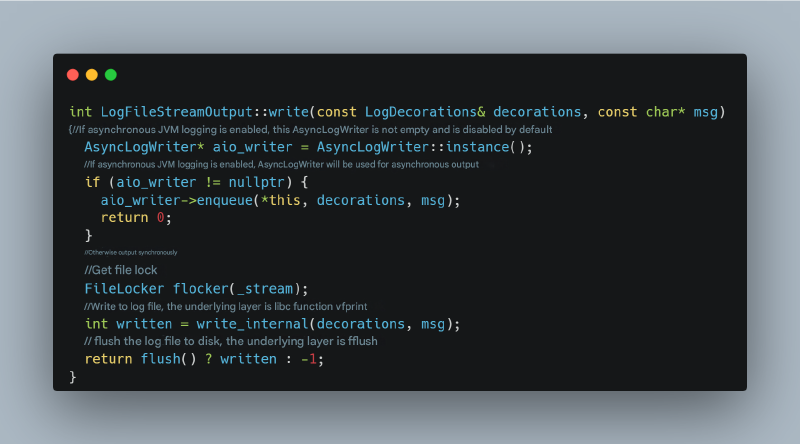
这段代码清楚地表明,如果文件 I/O 输出卡住,刷新操作将阻塞。此外,会有短暂的 CPU 峰值,因为刷新等待策略可能涉及 CPU 自旋一段时间,然后进入阻塞状态。
切换到异步日志怎么样?有哪些参数可用?JVM 异步日志在 Java 17 中引入,对应这个问题:https://bugs.openjdk.org/browse/JDK-8229517。关键在于这两个参数: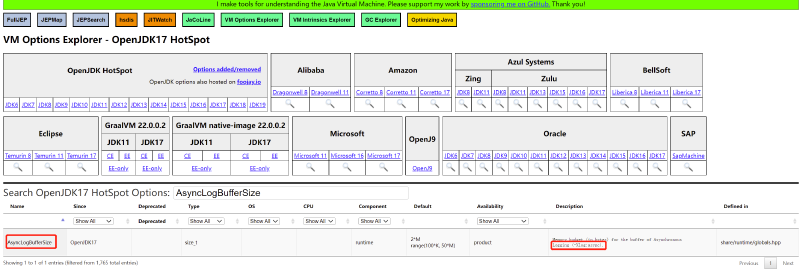
使用 -Xlog:async 启用 JVM 异步日志,并使用 -XX:AsyncLogBufferSize= 指定异步日志缓冲区大小(默认是 2097152,即 2MB)。异步日志原理如下:
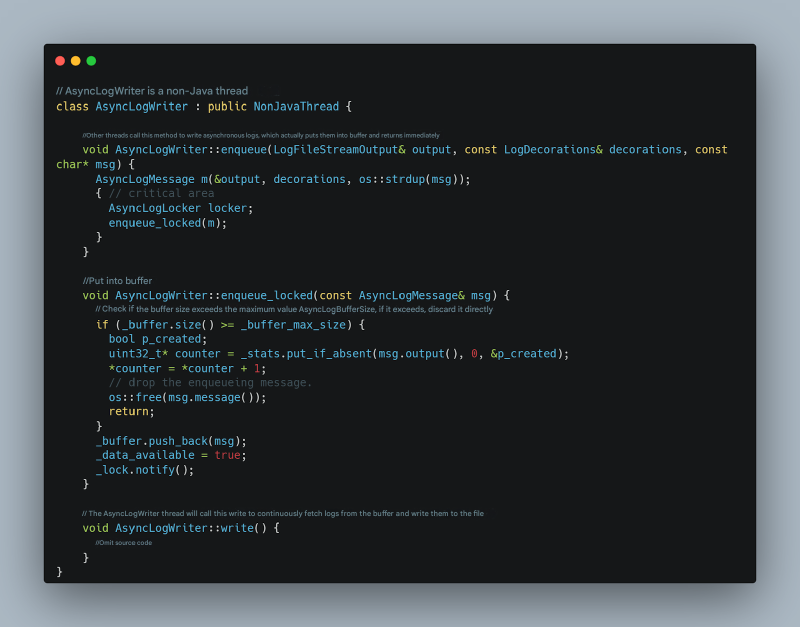
切换到异步日志:显著改善但未完全解决#
我们通过添加启动参数将日志修改为异步模式:-Xlog:async 和 -XX:AsyncLogBufferSize=4194304。观察后,问题显著缓解:
然而,一个实例仍然遇到问题,但症状与之前不同。Safepoint 日志显示一个线程持续运行并拒绝进入 safepoint:
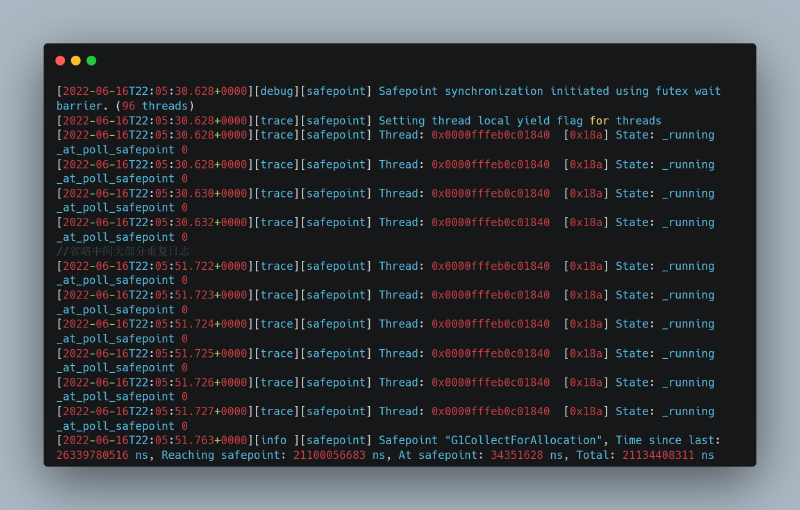
这个线程在做什么?我们使用 jstack 来识别它:
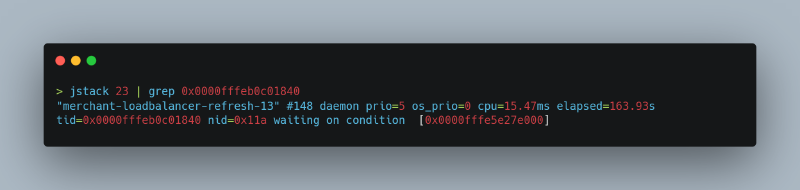
这是一个负责定期刷新微服务实例列表的线程,代码没有正确使用 WebFlux:
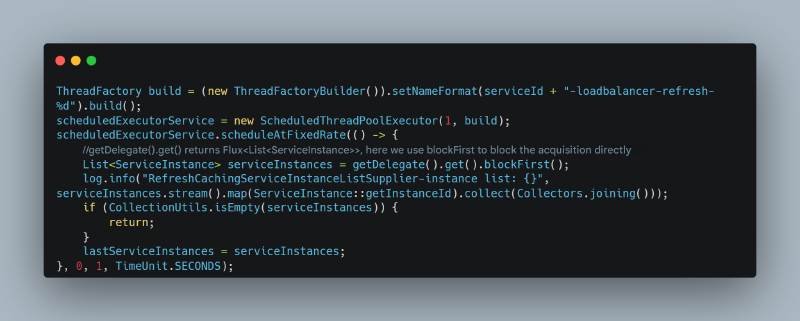
这种对异步代码的不当使用可能导致 JIT 优化错误(正确用法被频繁调用,这种错误用法也被频繁调用,导致持续的 JIT C2 优化和去优化)。JFR 显示在此期间有大量 JIT 去优化:
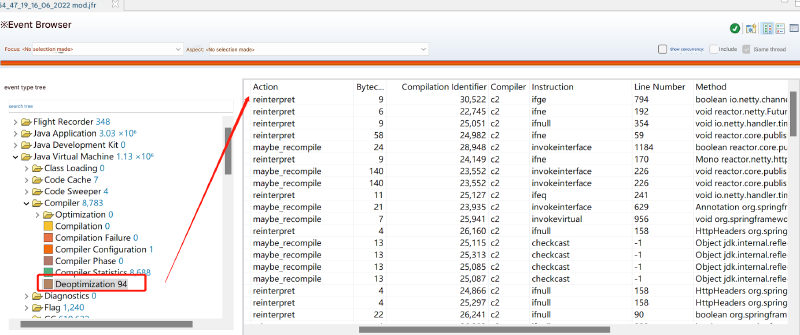
这可能导致 safepoint 间隙,导致 I/O 持续自旋并等待延长时间。解决方案是实现正确的使用模式:
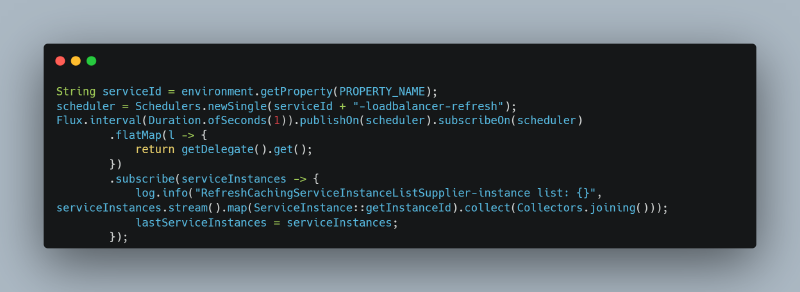
进行此修正后,线程拒绝进入 safepoint 的问题完全消失了。


