
解决分片 MySQL 表的性能下降:理解根本原因和解决方案#
当业务需求要求数据查询量和并发负载超过单个 MySQL 实例的限制时,数据库分片成为首选解决方案。当然,现在有许多 NewSQL 分布式数据库选项可用。如果你使用 MySQL,你可能想考虑 TiDB(它实现 MySQL 协议并与 MySQL 客户端和 SQL 语句兼容)。如果你使用 PostgreSQL,YugaByteDB 可能是你的解决方案(实现 PostgreSQL 协议,具有完整的客户端和 SQL 兼容性)。两个平台都提供自己的云部署解决方案,你可以探索:
然而,传统的分片项目仍然依赖 MySQL 和 PostgreSQL 等传统关系数据库作为基础。通常,当业务开始时,团队会考虑使用特定分片键在多个表之间分区数据。以订单表为例 - 我们可能估计用户主要需要查询过去一年的订单记录。对于超过一年的订单,我们将提供替代访问点,查询 HBase 等归档数据库,而不是运营业务数据库。
假设我们估计一年内的用户订单不会超过 10 亿条记录,更新并发(TPS,不是查询 QPS)保持在 100,000/秒以下。在这种情况下,我们可能考虑拆分为 64 个表(最好使用 2 的幂,因为与 2^n 的模运算可以优化为与 2^n - 1 的按位 AND 运算,减少分片键计算的计算开销)。我们还将实施定期归档过程,使用 delete from table 等语句删除一年前的数据以进行"完全删除"(注意删除周围的引号)。这种方法将业务表数据量保持在可管理的水平。
然而,随着时间的推移,你会注意到某些带有分片键(在这种情况下是 user_id)的查询开始变慢,一些错误地选择了本地索引。
为什么查询逐渐变慢#
考虑这个 SQL 示例:
select * from t_pay_record
WHERE
((
user_id = 'user_id1'
AND is_del = 0
))
ORDER BY
id DESC
LIMIT 20
这里,分片键是 user_id。
一个因素是数据量可能超过我们的预期,导致某些分片表增长超过最佳阈值。这导致 MySQL 索引的随机采样越来越不准确。统计不是实时更新的,而是仅在更新的行数超过一定百分比时更新。此外,这些统计使用采样而不是全表分析。当表变得非常大时,维护准确的统计变得具有挑战性。
依赖表的自动刷新机制使参数调整变得困难(主要是 STATS_SAMPLE_PAGES 参数 - 我们通常不修改 STATS_PERSISTENT,因为内存存储需要在数据库重启后重新分析表,减慢启动时间,我们也不禁用 STATS_AUTO_RECALC,因为这会使优化器分析越来越不准确)。预测最佳值几乎不可能,业务增长与用户行为模式相结合可能导致不可预测的数据倾斜。
当通过 ALTER TABLE 修改表的 STATS_SAMPLE_PAGES 时,它会触发与在表上运行 ANALYZE 相同的效果,获取阻止更新和事务的读锁。这使得它不适合关键在线业务表。理想情况下,我们应该从一开始就估计大表量,但这在实践中证明相当困难。
因此,对于具有大量数据的表,我们应该通过分片主动控制各个表的大小。然而,业务增长和产品需求不断演变并变得更加复杂,很难保证我们不会遇到具有复杂索引需求的大表。在这种情况下,我们需要适当增加 STATS_SAMPLE_PAGES 并使用 force index 引导关键用户触发的查询使用正确的索引。
但有时,即使使用了正确的索引,查询仍然有些慢。检查 SQL 扫描的行数,你会发现它并不是特别高。
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id | 32 | NULL | 16 | 0.01 | Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
你可能仍然会遇到偶尔的慢 SQL 查询,这些查询随着时间的推移变得更加频繁。这与 MySQL InnoDB 的删除机制有关。大多数业务表使用 InnoDB 引擎和默认的 Dynamic 行格式。当以这种格式插入数据时,结构大致如下:

记录头包含删除标志:

当发生改变记录长度的更新(例如可变长度字段变长)时,原始记录被标记为删除,并在末尾创建更新的记录。当删除记录时,只有记录头中的删除标志被标记。
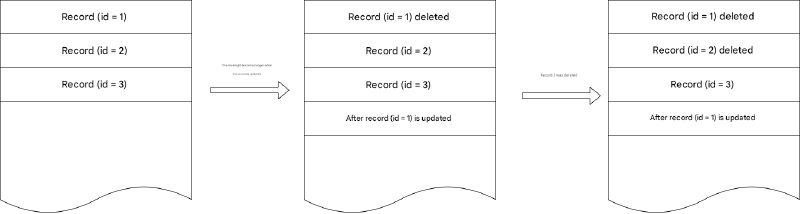
为了解决潜在的碎片,MySQL InnoDB 有期望和措施:InnoDB 引擎只存储占用每页空间 93% 的数据,留下其余部分以容纳长度变化的更新,而不会强制数据到其他页。然而,删除基本上完全浪费存储空间。
通常,这不会导致显著的性能下降,因为删除通常针对旧数据,而更新集中在最近的数据。例如,订单更新通常影响最近的订单,旧订单很少被更新,归档删除通常针对更旧的订单。然而,随着业务逻辑变得更加复杂,归档逻辑也变得更加复杂。不同的订单类型可能有不同的保留期 - 也许一年前的预订单仍未结算,无法归档。随着时间的推移,你的数据可能看起来像这样:
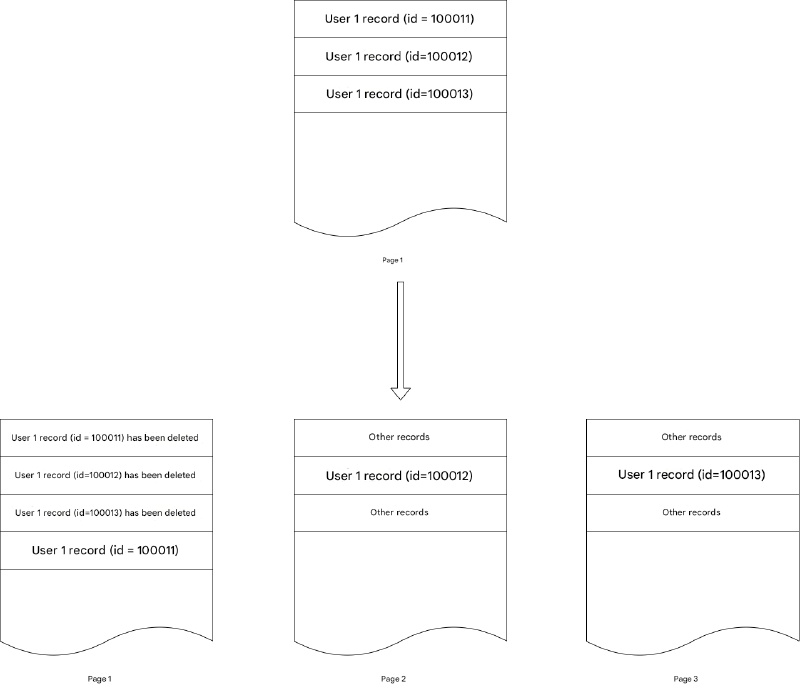
这导致原本需要扫描几页的内容逐渐需要扫描更多页,因为碎片增加,使 SQL 执行越来越慢。
以上描述了对表数据存储本身的影响。对于二级索引,MVCC 机制意味着对索引字段的频繁更新也会在索引中创建许多间隙。参考文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html
InnoDB 多版本并发控制(MVCC)对二级索引的处理与聚集索引不同。聚集索引中的记录就地更新,它们的隐藏系统列指向撤销日志条目,可以从中重建记录的早期版本。与聚集索引记录不同,二级索引记录不包含隐藏系统列,也不就地更新。
我们知道 MySQL InnoDB 就地更新聚集索引,但对于二级索引,当更新二级索引列时,原始记录被标记为删除,并在其他地方创建新记录。这创建了与我们之前描述的类似的存储碎片。
总结:
- MySQL InnoDB 的 Dynamic 行格式记录更新改变记录长度,以及 DELETE 语句,实际上标记原始记录为删除。虽然 MySQL InnoDB 用保留空间优化了这一点,但随着时间的推移累积的归档删除创建了内存碎片,降低了扫描效率。
- 二级索引列更新的 MVCC 机制标记原始记录为删除并在其他地方创建新记录,导致二级索引扫描效率随时间下降。
解决方案 - 表重建#
对于这种情况,我们可以通过表重建来解决。重建表实际上实现了两个目标:首先,它优化存储碎片并减少要扫描的行;其次,它重新分析数据以获得更准确的 SQL 优化器统计。
在 MySQL 5.6.17 之前,我们需要外部工具如 pt-online-schema-change 来帮助重建表。此工具通过内部创建新表,在原始表上添加触发器以在将数据复制到新表的同时将更新同步到新表,然后获取全局锁以将新表重命名为原始名称,然后删除原始表。在 MySQL 5.6.17 之后,OPTIMIZE TABLE 命令成为 Online DDL 操作,仅在准备和最终提交阶段需要锁,而不是在执行期间 - 这意味着它不会阻止业务 DML 操作。参考文档:https://dev.mysql.com/doc/refman/5.6/en/optimize-table.html
在 Mysql 5.6.17 之前,OPTIMIZE TABLE 不使用在线 DDL。因此,在 OPTIMIZE TABLE 运行时不允许在表上进行并发 DML(INSERT、UPDATE、DELETE),并且二级索引的创建效率不高。
从 MySQL 5.6.17 开始,OPTIMIZE TABLE 对常规和分区 InnoDB 表使用在线 DDL,这减少了并发 DML 操作的停机时间。OPTIMIZE TABLE 触发的表重建就地完成。独占表锁仅在操作的准备阶段和提交阶段短暂获取。在准备阶段,更新元数据并创建中间表。在提交阶段,提交表元数据更改。
在 InnoDB 表上使用 OPTIMIZE TABLE 时的关键考虑:
- 对于大多数 InnoDB 表,OPTIMIZE TABLE 本质上等于表重建 + ANALYZE 命令(等同于
ALTER TABLE ... FORCE),但与 ANALYZE 不同,OPTIMIZE TABLE 是具有优化机制的在线 DDL,仅在准备和最终提交阶段获取表锁,大大减少业务 DML 阻塞时间 - 使其成为在线执行的可行优化语句(适用于 MySQL 5.6.17 及更高版本)
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+-------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | status | OK |
+----------+----------+----------+-------------------------------------------------------------------+
- 尽管如此,在低业务流量期间执行 OPTIMIZE TABLE。与其他 Online DDL 操作一样,它创建并记录临时文件,记录 DDL 操作期间的所有 DML 插入、更新和删除。在高峰流量期间运行可能导致日志超过
innodb_online_alter_log_max_size限制:
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | error | Creating index 'PRIMARY' required more than 'innodb_online_alter_log_max_size' bytes of modification log. Please try again.|
| test.foo | optimize | status | OK |
+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------+
如果你在低流量期间遇到此错误,可以稍微增加
innodb_online_alter_log_max_size,但不要使其太大 - 建议以 128 MB 为增量增加(默认是 128 MB)。过大的大小可能导致两个问题:(1)由于大日志,最终阶段的提交时间延长,导致长时间锁定。(2)来自业务压力的临时文件持续写入永远无法赶上,导致语句仍在高峰流量期间执行。在评估对在线业务的影响时,监控锁
wait/synch/sxlock/innodb/dict_sys_lock和wait/synch/sxlock/innodb/dict_operation_lock。如果这些与锁相关的事件变得过多,并且你注意到在线有明显的慢 SQL 查询,考虑终止操作并重新安排 OPTIMIZE TABLE 到另一个时间。
select thread_id,event_id,event_name,timer_wait from events_waits_history where event_name Like "%dict%" order by thread_id;
SELECT event_name,COUNT_STAR FROM events_waits_summary_global_by_event_name
where event_name Like "%dict%" ORDER BY COUNT_STAR DESC;


