
最近,我收到了用户的消息和评论,询问一个有趣的问题:当使用 spring-data-redis 与 lettuce 时,他们通过数据包捕获注意到 pipeline 操作实际上没有按预期工作。那么我们如何正确配置这个以使其工作?
首先,让我们回顾一下我们在之前的文章中讨论的关于 Spring-data-redis + Lettuce 的基本原理。在此设置中,RedisTemplate 使用的连接在内部包括:
- asyncSharedConn:这可以为 null,但如果启用了连接共享(默认情况下是启用的),它不会为空。这是所有 LettuceConnection 实例使用的共享 Redis 连接 - 它们实际上都在底层使用相同的连接。它用于执行简单命令,由于 Netty 的客户端架构和 Redis 的单线程处理特性,共享一个连接仍然相当快。如果禁用连接共享,此字段保持为空,并使用 asyncDedicatedConn 代替。
- asyncDedicatedConn:这是一个私有连接,当你需要维护会话状态、执行事务或使用固定连接运行 Pipeline 命令时必须使用。
execute(RedisCallback) 的流程如下:
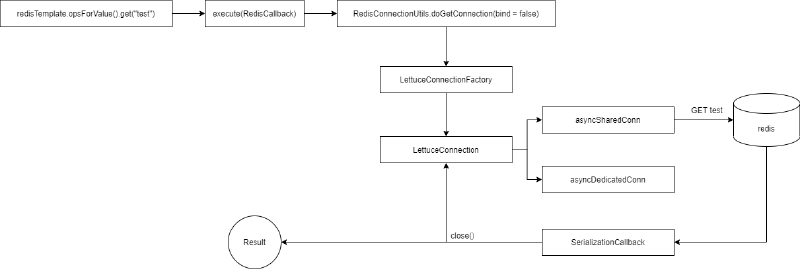
对于 executePipelined(RedisCallback),当正确使用时,它应该利用 asyncDedicatedConn 私有连接。但"正确使用"是什么意思?
你必须使用回调的连接进行 Redis 调用 - 你不能直接使用 redisTemplate 调用,否则 pipeline 不会工作:
Pipeline 正确工作:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.get("test".getBytes());
connection.get("test2".getBytes());
return null;
}
});
Pipeline 不工作:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
redisTemplate.opsForValue().get("test");
redisTemplate.opsForValue().get("test2");
return null;
}
});
这确保了我们在应用级别正确使用 pipeline API,但在默认配置下,底层 pipeline 仍然不执行。这里发生了什么?
Redis Pipeline vs Lettuce 的 AutoFlushCommands#
Redis Pipeline 是 Redis 的批量操作功能。它允许你将一组 Redis 命令打包在一起,一次性发送到 Redis,并返回结果集。这大大减少了如果单独发送命令所需的 RTT(往返时间) - 包括 Redis 客户端和服务器切换系统调用以发送/接收数据的时间,以及网络传输时间。
如果命令原本是这样发送的:
Client -> Server: INCR X\r\n
Server -> Client: 1
Client -> Server: INCR X\r\n
Server -> Client: 2
Client -> Server: INCR X\r\n
Server -> Client: 3
Client -> Server: INCR X\r\n
Server -> Client: 4
使用 PIPELINE,命令会这样发送:
Client -> Server: INCR X\r\nINCR X\r\nINCR X\r\nINCR X\r\n
Server -> Client: 1\r\n2\r\n3\r\n4
如你所见,原理是客户端首先将所有命令连接在一起并在本地缓存它们,然后一次性将它们全部发送到服务器。服务器执行所有命令并一起响应所有结果。
Lettuce 连接有一个 AutoFlushCommands 配置,它确定在此连接上执行的命令如何发送到服务器。默认情况下,它是 true,意味着每个命令在收到后立即发送到服务器。如果设置为 false,所有命令都被缓存,只有在手动调用 flushCommands 时才发送到服务器 - 这基本上实现了 Pipeline 功能。
配置 Spring-data-redis + Lettuce 用于 Pipeline#
从版本 2.3.0 开始,Spring-data-redis 为 Lettuce 添加了 Pipeline 配置支持。参考:
- DATAREDIS-1011 - Allow configuration of Lettuce pipelining flush behavior
- https://github.com/spring-projects/spring-data-redis/issues/1581
我们可以这样配置:
@Bean
public BeanPostProcessor lettuceConnectionFactoryBeanProcessor() {
return new BeanPostProcessor() {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
//在 LettuceConnectionFactory bean 初始化后,将 PipeliningFlushPolicy 设置为 flushOnClose
if (bean instanceof LettuceConnectionFactory) {
LettuceConnectionFactory lettuceConnectionFactory = (LettuceConnectionFactory) bean;
lettuceConnectionFactory.setPipeliningFlushPolicy(LettuceConnection.PipeliningFlushPolicy.flushOnClose());
//感谢评论者 [孤胆枪手](https://juejin.cn/user/2084329775180605) 的纠正,我之前忘记了这个配置
lettuceConnectionFactory.setShareNativeConnection(false);
}
return bean;
}
};
}
注意我们在这里将 shareNativeConnection 设置为 false。通常,基于 Lettuce 的 RedisTemplate 中的大多数请求可以通过连接共享共享相同的连接。禁用这意味着我们每次都获得专用连接。在这种情况下,我们需要小心使用连接池(以防止每次都创建新连接),并确保池大小大于可能的并发线程数,以防止在等待连接时阻塞。
为什么我们需要禁用连接共享?让我们看看源代码:
RedisClusterAsyncCommands<byte[], byte[]> getAsyncConnection() {
//仅对 Redis 事务为 true
if (this.isQueueing()) {
return this.getAsyncDedicatedConnection();
} else {
//如果有共享连接,返回它;否则返回专用连接。只有专用连接使 PipeliningFlushPolicy 生效 - PipeliningFlushPolicy 不会修改共享连接
return (RedisClusterAsyncCommands)(this.asyncSharedConn != null && this.asyncSharedConn instanceof StatefulRedisConnection ? ((StatefulRedisConnection)this.asyncSharedConn).async() : this.getAsyncDedicatedConnection());
}
}
由于我们想使用 PipeliningFlushPolicy,我们需要这返回专用连接,这意味着我们不能启用连接共享。
让我们看看 PipeliningFlushPolicy 源代码以了解 flushOnClose 的含义:
public interface PipeliningFlushPolicy {
//这是默认值 - 每个命令直接发送到 Redis Server
static PipeliningFlushPolicy flushEachCommand() {
return FlushEachCommand.INSTANCE;
}
//当连接关闭时,一起发送所有命令到 Redis
static PipeliningFlushPolicy flushOnClose() {
return FlushOnClose.INSTANCE;
}
//手动设置缓冲多少个命令后再发送到 Redis,但连接关闭也会触发发送
static PipeliningFlushPolicy buffered(int bufferSize) {
return () -> new BufferedFlushing(bufferSize);
}
}
所有三个类都实现 PipeliningFlushState 接口:
public interface PipeliningFlushState {
//对于 executePipelined,这通过 connection.openPipeline() 在开始时调用
void onOpen(StatefulConnection<?, ?> connection);
//为 executePipelined 中的每个命令调用
void onCommand(StatefulConnection<?, ?> connection);
//在 executePipelined 结束时通过 connection.closePipeline() 调用
void onClose(StatefulConnection<?, ?> connection);
}
直接向 Redis Server 发送每个命令的默认实现基本上在其方法中什么都不做:
private enum FlushEachCommand implements PipeliningFlushPolicy, PipeliningFlushState {
INSTANCE;
@Override
public PipeliningFlushState newPipeline() {
return INSTANCE;
}
@Override
public void onOpen(StatefulConnection<?, ?> connection) {}
@Override
public void onCommand(StatefulConnection<?, ?> connection) {}
@Override
public void onClose(StatefulConnection<?, ?> connection) {}
}
对于 flushOnClose:
private enum FlushOnClose implements PipeliningFlushPolicy, PipeliningFlushState {
INSTANCE;
@Override
public PipeliningFlushState newPipeline() {
return INSTANCE;
}
@Override
public void onOpen(StatefulConnection<?, ?> connection) {
//首先,将连接的 AutoFlushCommands 设置为 false,以便命令不会立即发送到 Redis
connection.setAutoFlushCommands(false);
}
@Override
public void onCommand(StatefulConnection<?, ?> connection) {
//接收命令时什么都不做
}
@Override
public void onClose(StatefulConnection<?, ?> connection) {
//当 pipeline 关闭时发送所有命令
connection.flushCommands();
//恢复默认配置,以便连接在返回到池时不影响未来使用
connection.setAutoFlushCommands(true);
}
}
对于 buffered:
private static class BufferedFlushing implements PipeliningFlushState {
private final AtomicLong commands = new AtomicLong();
private final int flushAfter;
public BufferedFlushing(int flushAfter) {
this.flushAfter = flushAfter;
}
@Override
public void onOpen(StatefulConnection<?, ?> connection) {
//首先,将连接的 AutoFlushCommands 设置为 false,以便命令不会立即发送到 Redis
connection.setAutoFlushCommands(false);
}
@Override
public void onCommand(StatefulConnection<?, ?> connection) {
//如果命令计数达到指定数量,发送到 Redis
if (commands.incrementAndGet() % flushAfter == 0) {
connection.flushCommands();
}
}
@Override
public void onClose(StatefulConnection<?, ?> connection) {
//当 pipeline 关闭时发送所有命令
connection.flushCommands();
//恢复默认配置,以便连接在返回到池时不影响未来使用
connection.setAutoFlushCommands(true);
}
}

