
本篇是关于 JVM 内存的详细分析。网上有很多关于 JVM 内存结构的分析以及图片,但是由于不是一手的资料亦或是人云亦云导致有很错误,造成了很多误解;并且,这里可能最容易混淆的是一边是 JVM Specification 的定义,一边是 Hotspot JVM 的实际实现,有时候人们一些部分说的是 JVM Specification,一部分说的是 Hotspot 实现,给人一种割裂感与误解。本篇主要从 Hotspot 实现出发,以 Linux x86 环境为主,紧密贴合 JVM 源码并且辅以各种 JVM 工具验证帮助大家理解 JVM 内存的结构。但是,本篇仅限于对于这些内存的用途,使用限制,相关参数的分析,有些地方可能比较深入,有些地方可能需要结合本身用这块内存涉及的 JVM 模块去说,会放在另一系列文章详细描述。最后,洗稿抄袭狗不得 house
本篇全篇目录(以及涉及的 JVM 参数):
- 从 Native Memory Tracking 说起
- Native Memory Tracking 的开启
- Native Memory Tracking 的使用(涉及 JVM 参数:
NativeMemoryTracking) - Native Memory Tracking 的 summary 信息每部分含义
- Native Memory Tracking 的 summary 信息的持续监控
- 为何 Native Memory Tracking 中申请的内存分为 reserved 和 committed
- JVM 内存申请与使用流程
- Linux 下内存管理模型简述
- JVM commit 的内存与实际占用内存的差异
- JVM commit 的内存与实际占用内存的差异
- 大页分配 UseLargePages
- Linux 大页分配方式 - Huge Translation Lookaside Buffer Page (hugetlbfs)
- Linux 大页分配方式 - Transparent Huge Pages (THP)
- JVM 大页分配相关参数与机制(涉及 JVM 参数:
UseLargePages,UseHugeTLBFS,UseSHM,UseTransparentHugePages,LargePageSizeInBytes)
- Java 堆内存相关设计
- 通用初始化与扩展流程
- 直接指定三个指标的方式(涉及 JVM 参数:
MaxHeapSize,MinHeapSize,InitialHeapSize,Xmx,Xms) - 不手动指定三个指标的情况下,这三个指标(MinHeapSize,MaxHeapSize,InitialHeapSize)是如何计算的
- 压缩对象指针相关机制(涉及 JVM 参数:
UseCompressedOops)- 压缩对象指针存在的意义(涉及 JVM 参数:
ObjectAlignmentInBytes) - 压缩对象指针与压缩类指针的关系演进(涉及 JVM 参数:
UseCompressedOops,UseCompressedClassPointers) - 压缩对象指针的不同模式与寻址优化机制(涉及 JVM 参数:
ObjectAlignmentInBytes,HeapBaseMinAddress)
- 压缩对象指针存在的意义(涉及 JVM 参数:
- 为何预留第 0 页,压缩对象指针 null 判断擦除的实现(涉及 JVM 参数:
HeapBaseMinAddress) - 结合压缩对象指针与前面提到的堆内存限制的初始化的关系(涉及 JVM 参数:
HeapBaseMinAddress,ObjectAlignmentInBytes,MinHeapSize,MaxHeapSize,InitialHeapSize) - 使用 jol + jhsdb + JVM 日志查看压缩对象指针与 Java 堆验证我们前面的结论
- 验证
32-bit压缩指针模式 - 验证
Zero based压缩指针模式 - 验证
Non-zero disjoint压缩指针模式 - 验证
Non-zero based压缩指针模式
- 验证
- 堆大小的动态伸缩(涉及 JVM 参数:
MinHeapFreeRatio,MaxHeapFreeRatio,MinHeapDeltaBytes) - 适用于长期运行并且尽量将所有可用内存被堆使用的 JVM 参数 AggressiveHeap
- JVM 参数 AlwaysPreTouch 的作用
- JVM 参数 UseContainerSupport - JVM 如何感知到容器内存限制
- JVM 参数 SoftMaxHeapSize - 用于平滑迁移更耗内存的 GC 使用
- JVM 元空间设计
- 什么是元数据,为什么需要元数据
- 什么时候用到元空间,元空间保存什么
- 什么时候用到元空间,以及释放时机
- 元空间保存什么
- 元空间的核心概念与设计
- 元空间的整体配置以及相关参数(涉及 JVM 参数:
MetaspaceSize,MaxMetaspaceSize,MinMetaspaceExpansion,MaxMetaspaceExpansion,MaxMetaspaceFreeRatio,MinMetaspaceFreeRatio,UseCompressedClassPointers,CompressedClassSpaceSize,CompressedClassSpaceBaseAddress,MetaspaceReclaimPolicy) - 元空间上下文
MetaspaceContext - 虚拟内存空间节点列表
VirtualSpaceList - 虚拟内存空间节点
VirtualSpaceNode与CompressedClassSpaceSize MetaChunkChunkHeaderPool池化MetaChunk对象ChunkManager管理空闲的MetaChunk
- 类加载的入口
SystemDictionary与保留所有ClassLoaderData的ClassLoaderDataGraph - 每个类加载器私有的
ClassLoaderData以及ClassLoaderMetaspace - 管理正在使用的
MetaChunk的MetaspaceArena - 元空间内存分配流程
- 类加载器到
MetaSpaceArena的流程 - 从
MetaChunkArena普通分配 - 整体流程 - 从
MetaChunkArena普通分配 -FreeBlocks回收老的current chunk与用于后续分配的流程 - 从
MetaChunkArena普通分配 - 尝试从FreeBlocks分配 - 从
MetaChunkArena普通分配 - 尝试扩容current chunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 从VirtualSpaceList申请新的RootMetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 将RootMetaChunk切割成为需要的MetaChunk MetaChunk回收 - 不同情况下,MetaChunk如何放入FreeChunkListVector
- 类加载器到
ClassLoaderData回收
- 元空间的整体配置以及相关参数(涉及 JVM 参数:
- 元空间分配与回收流程举例
- 首先类加载器 1 需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 还需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 需要分配 264 KB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 2 MB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 128KB 大小的内存,属于类空间
- 新来一个类加载器 2,需要分配 1023 Bytes 大小的内存,属于类空间
- 然后类加载器 1 被 GC 回收掉
- 然后类加载器 2 需要分配 1 MB 大小的内存,属于类空间
- 元空间大小限制与动态伸缩
CommitLimiter的限制元空间可以 commit 的内存大小以及限制元空间占用达到多少就开始尝试 GC- 每次 GC 之后,也会尝试重新计算
_capacity_until_GC
jcmd VM.metaspace元空间说明、元空间相关 JVM 日志以及元空间 JFR 事件详解jcmd <pid> VM.metaspace元空间说明- 元空间相关 JVM 日志
- 元空间 JFR 事件详解
jdk.MetaspaceSummary元空间定时统计事件jdk.MetaspaceAllocationFailure元空间分配失败事件jdk.MetaspaceOOM元空间 OOM 事件jdk.MetaspaceGCThreshold元空间 GC 阈值变化事件jdk.MetaspaceChunkFreeListSummary元空间 Chunk FreeList 统计事件
- JVM 线程内存设计(重点研究 Java 线程)
- JVM 中有哪几种线程,对应线程栈相关的参数是什么(涉及 JVM 参数:
ThreadStackSize,VMThreadStackSize,CompilerThreadStackSize,StackYellowPages,StackRedPages,StackShadowPages,StackReservedPages,RestrictReservedStack) - Java 线程栈内存的结构
- Java 线程如何抛出的 StackOverflowError
- 解释执行与编译执行时候的判断(x86为例)
- 一个 Java 线程 Xss 最小能指定多大
- JVM 中有哪几种线程,对应线程栈相关的参数是什么(涉及 JVM 参数:
1. 从 Native Memory Tracking 说起#
JVM 内存究竟包括哪些,可能网上众说纷纭。我们这里由官方提供的一个查看 JVM 内存占用的工具引入,即 Native Memory Tracking。不过要注意的一点是,这个只能监控 JVM 原生申请的内存大小,如果是通过 JDK 封装的系统 API 申请的内存,是统计不到的,例如 Java JDK 中的 DirectBuffer 以及 MappedByteBuffer 这两个(当然,对于这两个,我们后面也有其他的办法去看到当前使用的大小。当然xigao dog 啥都不会)。以及如果你自己封装 JNI 调用系统调用去申请内存,都是 Native Memory Tracking 无法涵盖的。这点要注意。
1.1. Native Memory Tracking 的开启#
Native Memory Tracking 主要是用来通过在 JVM 向系统申请内存的时候进行埋点实现的。注意,这个埋点,并不是完全没有消耗的,我们后面会看到。由于需要埋点,并且 JVM 中申请内存的地方很多,这个埋点是有不小消耗的,这个 Native Memory Tracking 默认是不开启的,并且无法动态开启(因为这是埋点采集统计的,如果可以动态开启那么没开启的时候的内存分配没有记录无法知晓,所以无法动态开启),目前只能通过在启动 JVM 的时候通过启动参数开启。即通过 -XX:NativeMemoryTracking 开启:
-XX:NativeMemoryTracking=off:这是默认值,即关闭 Native Memory Tracking-XX:NativeMemoryTracking=summary: 开启 Native Memory Tracking,但是仅仅按照各个 JVM 子系统去统计内存占用情况-XX:NativeMemoryTracking=detail:开启 Native Memory Tracking,从每次 JVM 中申请内存的不同调用路径的维度去统计内存占用情况。注意,开启 detail 比开启 summary 的消耗要大不少,因为 detail 每次都要解析 CallSite 分辨调用位置。我们一般用不到这么详细的内容,除非是 JVM 开发。只有洗稿狗才会开启这个配置导致线上崩溃而自己又很懵。
开启之后,我们可以通过 jcmd 命令去查看 Native Memory Tracking 的信息,即jcmd <pid> VM.native_memory:
jcmd <pid> VM.native_memory或者jcmd <pid> VM.native_memory summary:两者是等价的,即查看 Native Memory Tracking 的 summary 信息。默认单位是 KB,可以指定单位为其他,例如jcmd <pid> VM.native_memory summary scale=MBjcmd <pid> VM.native_memory detail:查看 Native Memory Tracking 的 detail 信息,包括 summary 信息,以及按照虚拟内存映射分组的内存使用信息,还有按照不同 CallSite 调用分组的内存使用情况。默认单位是 KB,可以指定单位为其他,例如jcmd <pid> VM.native_memory detail scale=MB
1.2. Native Memory Tracking 的使用#
对于我们这些 Java 开发以及 JVM 使用者而言(对于抄袭狗是没有好果汁吃的),我们只关心并且查看 Native Memory Tracking 的 summary 信息即可,detail 信息一般是供 JVM 开发人员使用的,我们不用太关心,我们后面的分析也只会涉及 Native Memory Tracking 的 summary 部分。
一般地,只有遇到问题的时候,我们才会考虑开启 Native Memory Tracking,并且在定位出问题后,我们想把它关闭,可以通过 jcmd <pid> VM.native_memory shutdown 进行关闭并清理掉之前 Native Memory tracking 使用的埋点以及占用的内存。如前面所述,我们无法动态开启 Native Memory tracking,所以只要动态关闭了,这个进程就无法再开启了。
jcmd 本身提供了简单的对比功能,例如:
- 使用
jcmd <pid> VM.native_memory baseline记录当前内存占用信息 - 之后过一段时间
jcmd <pid> VM.native_memory summary.diff会输出当前 Native Memory Tracking 的 summary 信息,如果与第一步 baseline 的有差异,会在对应位将差异输出
但是这个工具本身比较粗糙,我们有时候并不知道何时调用 jcmd <pid> VM.native_memory summary.diff 合适,因为我们不确定什么时候会有我们想看到的内存使用过大的问题。所以我们一般做成一种持续监控的方式
1.3. Native Memory Tracking 的 summary 信息每部分含义#
以下是一个 Native Memory Tracking 的示例输出:
Total: reserved=10575644KB, committed=443024KB
- Java Heap (reserved=8323072KB, committed=192512KB)
(mmap: reserved=8323072KB, committed=192512KB)
- Class (reserved=1050202KB, committed=10522KB)
(classes #15409)
( instance classes #14405, array classes #1004)
(malloc=1626KB #33495)
(mmap: reserved=1048576KB, committed=8896KB)
( Metadata: )
( reserved=57344KB, committed=57216KB)
( used=56968KB)
( waste=248KB =0.43%)
( Class space:)
( reserved=1048576KB, committed=8896KB)
( used=8651KB)
( waste=245KB =2.75%)
- Thread (reserved=669351KB, committed=41775KB)
(thread #653)
(stack: reserved=667648KB, committed=40072KB)
(malloc=939KB #3932)
(arena=764KB #1304)
- Code (reserved=50742KB, committed=17786KB)
(malloc=1206KB #9495)
(mmap: reserved=49536KB, committed=16580KB)
- GC (reserved=370980KB, committed=69260KB)
(malloc=28516KB #8340)
(mmap: reserved=342464KB, committed=40744KB)
- Compiler (reserved=159KB, committed=159KB)
(malloc=29KB #813)
(arena=131KB #3)
- Internal (reserved=1373KB, committed=1373KB)
(malloc=1309KB #6135)
(mmap: reserved=64KB, committed=64KB)
- Other (reserved=12348KB, committed=12348KB)
(malloc=12348KB #14)
- Symbol (reserved=18629KB, committed=18629KB)
(malloc=16479KB #445877)
(arena=2150KB #1)
- Native Memory Tracking (reserved=8426KB, committed=8426KB)
(malloc=325KB #4777)
(tracking overhead=8102KB)
- Shared class space (reserved=12032KB, committed=12032KB)
(mmap: reserved=12032KB, committed=12032KB)
- Arena Chunk (reserved=187KB, committed=187KB)
(malloc=187KB)
- Tracing (reserved=32KB, committed=32KB)
(arena=32KB #1)
- Logging (reserved=5KB, committed=5KB)
(malloc=5KB #216)
- Arguments (reserved=31KB, committed=31KB)
(malloc=31KB #90)
- Module (reserved=403KB, committed=403KB)
(malloc=403KB #2919)
- Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)
- Synchronization (reserved=56KB, committed=56KB)
(malloc=56KB #789)
- Serviceability (reserved=1KB, committed=1KB)
(malloc=1KB #18)
- Metaspace (reserved=57606KB, committed=57478KB)
(malloc=262KB #180)
(mmap: reserved=57344KB, committed=57216KB)
- String Deduplication (reserved=1KB, committed=1KB)
(malloc=1KB #8)
我们接下来将上面的信息按不同子系统分别简单分析下其含义:
1.Java堆内存,所有 Java 对象分配占用内存的来源,由 JVM GC 管理回收,这是我们在第三章会重点分析的:
//堆内存占用,reserve 了 8323072KB,当前 commit 了 192512KB 用于实际使用
Java Heap (reserved=8323072KB, committed=192512KB)
//堆内存都是通过 mmap 系统调用方式分配的
(mmap: reserved=8323072KB, committed=192512KB)
//chao xi 可耻
2.元空间,JVM 将类文件加载到内存中用于后续使用占用的空间,注意是 JVM C++ 层面的内存占用,主要包括类文件中在 JVM 解析为 C++ 的 Klass 类以及相关元素。对应的 Java 反射类 Class 还是在堆内存空间中:
//Class 是类元空间总占用,reserve 了 1050202KB,当前 commit 了 10522KB 用于实际使用
//总共 reserved 1050202KB = mmap reserved 1048576KB + malloc 1626KB
//总共 committed 10522KB = mmap committed 8896KB + malloc 1626KB
Class (reserved=1050202KB, committed=10522KB)
(classes #15409) //一共加载了 15409 个类
( instance classes #14405, array classes #1004) //其中 14405 个实体类,1004 个数组类
(malloc=1626KB #33495) //通过 malloc 系统调用方式一共分配了 1626KB,一共调用了 33495 次 malloc
(mmap: reserved=1048576KB, committed=8896KB) //通过 mmap 系统调用方式 reserve 了 1048576KB,当前 commit 了 8896KB 用于实际使用
( Metadata: )//注意,MetaData 这块不属于类元空间,属于数据元空间,后面第四章会详细分析
( reserved=57344KB, committed=57216KB) //数据元空间当前 reserve 了 57344KB,commit 了 57216KB 用于实际使用
( used=56968KB) //但是实际从 MetaChunk 的角度去看使用,只有 56968KB 用于实际数据的分配,有 248KB 的浪费
( waste=248KB =0.43%)
( Class space:)
( reserved=1048576KB, committed=8896KB) //类元空间当前 reserve 了 1048576KB,commit 了 8896KB 用于实际使用
( used=8651KB) //但是实际从 MetaChunk 的角度去看使用,只有 8651KB 用于实际数据的分配,有 245KB 的浪费
( waste=245KB =2.75%)
洗稿去shi
Shared class space (reserved=12032KB, committed=12032KB) //共享类空间,当前 reserve 了 12032KB,commit 了 12032KB 用于实际使用,这块其实属于上面 Class 的一部分
(mmap: reserved=12032KB, committed=12032KB)
Module (reserved=403KB, committed=403KB) //加载并记录模块占用空间,当前 reserve 了 403KB,commit 了 403KB 用于实际使用
(malloc=403KB #2919)
Metaspace (reserved=57606KB, committed=57478KB) //等价于上面 Class 中的 MetaChunk(除了 malloc 的部分),当前 reserve 了 57606KB,commit 了 57478KB 用于实际使用
(malloc=262KB #180)
(mmap: reserved=57344KB, committed=57216KB)
3.C++ 字符串即符号(Symbol)占用空间,前面加载类的时候,其实里面有很多字符串信息(注意不是 Java 字符串,是 JVM 层面 C++ 字符串),不同类的字符串信息可能会重复(维护原创打死潮汐犬)。所以统一放入符号表(Symbol table)复用。元空间中保存的是针对符号表中符号的引用。这不是本期内容的重点,我们不会详细分析
Symbol (reserved=18629KB, committed=18629KB)
(malloc=16479KB #445877) //通过 malloc 系统调用方式一共分配了 16479KB,一共调用了 445877 次 malloc
(arena=2150KB #1) //通过 arena 系统调用方式一共分配了 2150KB,一共调用了 1 次 arena
4.线程占用内存,主要是每个线程的线程栈,我们也只会主要分析线程栈占用空间(在第五章),其他的管理线程占用的空间很小,可以忽略不计。
//总共 reserve 了 669351KB,commit 了 41775KB
Thread (reserved=669351KB, committed=41775KB)
(thread #653)//当前线程数量是 653
(stack: reserved=667648KB, committed=40072KB) //线程栈占用的空间:我们没有指定 Xss,默认是 1MB,所以 reserved 是 653 * 1024 = 667648KB,当前 commit 了 40072KB 用于实际使用
(malloc=939KB #3932) //通过 malloc 系统调用方式一共分配了 939KB,一共调用了 3932 次 malloc
(arena=764KB #1304) //通过 JVM 内部 Arena 分配的内存,一共分配了 764KB,一共调用了 1304 次 Arena 分配
5.JIT编译器本身占用的空间以及JIT编译器编译后的代码占用空间,这也不是本期内容的重点,我们不会详细分析
Code (reserved=50742KB, committed=17786KB)
(malloc=1206KB #9495)
(mmap: reserved=49536KB, committed=16580KB)
//chao xi 直接去火葬场炒
Compiler (reserved=159KB, committed=159KB)
(malloc=29KB #813)
(arena=131KB #3)
6.Arena 数据结构占用空间,我们看到 Native Memory Tracking 中有很多通过 arena 分配的内存,这个就是管理 Arena 数据结构占用空间。这不是本期内容的重点,我们不会详细分析
Arena Chunk (reserved=187KB, committed=187KB)
(malloc=187KB)
7.JVM Tracing 占用内存,包括 JVM perf 以及 JFR 占用的空间。其中 JFR 占用的空间可能会比较大,我在我的另一个关于 JFR 的系列里面分析过 JVM 内存中占用的空间。这不是本期内容的重点,我们不会详细分析
Tracing (reserved=32KB, committed=32KB)
(arena=32KB #1)
8.写 JVM 日志占用的内存(-Xlog 参数指定的日志输出,并且 Java 17 之后引入了异步 JVM 日志-Xlog:async,异步日志所需的 buffer 也在这里),这不是本期内容的重点,我们不会详细分析
Logging (reserved=5KB, committed=5KB)
(malloc=5KB #216)
9.JVM 参数占用内存,我们需要保存并处理当前的 JVM 参数以及用户启动 JVM 的是传入的各种参数(有时候称为 flag)。这不是本期内容的重点,我们不会详细分析
Arguments (reserved=31KB, committed=31KB)
(malloc=31KB #90)
10.JVM 安全点占用内存,是固定的两页内存(我这里是一页是 4KB,后面第二章会分析这个页大小与操作系统相关),用于 JVM 安全点的实现,不会随着 JVM 运行时的内存占用而变化。JVM 安全点请期待本系列文章的下一系列:全网最硬核的 JVM 安全点与线程握手机制解析。这不是本期内容的重点,我们不会详细分析
Safepoint (reserved=8KB, committed=8KB)
(mmap: reserved=8KB, committed=8KB)
11.Java 同步机制(例如 synchronized,还有 AQS 的基础 LockSupport)底层依赖的 C++ 的数据结构,系统内部的 mutex 等占用的内存。这不是本期内容的重点,我们不会详细分析
Synchronization (reserved=56KB, committed=56KB)
(malloc=56KB #789)
12.JVM TI 相关内存,JVMTI 是 Java 虚拟机工具接口(Java Virtual Machine Tool Interface)的缩写。它是 Java 虚拟机(JVM)的一部分,提供了一组 API,使开发人员可以开发自己的 Java 工具和代理程序,以监视、分析和调试 Java 应用程序。JVMTI API 是一组 C/C++ 函数,可以通过 JVM TI Agent Library 和 JVM 进行交互。开发人员可以使用 JVMTI API 开发自己的 JVM 代理程序或工具,以监视和操作 Java 应用程序。例如,可以使用 JVMTI API 开发性能分析工具、代码覆盖率工具、内存泄漏检测工具等等。这里的内存就是调用了 JVMTI API 之后 JVM 为了生成数据占用的内存。这不是本期内容的重点,我们不会详细分析
Serviceability (reserved=1KB, committed=1KB)
(malloc=1KB #18)
13.Java 字符串去重占用内存:Java 字符串去重机制可以减少应用程序中字符串对象的内存占用。 在 Java 应用程序中,字符串常量是不可变的,并且通常被使用多次。这意味着在应用程序中可能存在大量相同的字符串对象,这些对象占用了大量的内存。Java 字符串去重机制通过在堆中共享相同的字符串对象来解决这个问题。当一个字符串对象被创建时,JVM 会检查堆中是否已经存在相同的字符串对象。如果存在,那么新的字符串对象将被舍弃,而引用被返回给现有的对象。这样就可以减少应用程序中字符串对象的数量,从而减少内存占用。 但是这个机制一直在某些 GC 下表现不佳,尤其是 G1GC 以及 ZGC 中,所以默认是关闭的,可以通过 -XX:+UseStringDeduplication 来启用。这不是本期内容的重点,我们不会详细分析。
String Deduplication (reserved=1KB, committed=1KB)
(malloc=1KB #8)
14.JVM GC需要的数据结构与记录信息占用的空间,这块内存可能会比较大,尤其是对于那种专注于低延迟的 GC,例如 ZGC。其实 ZGC 是一种以空间换时间的思路,提高 CPU 消耗与内存占用,但是消灭全局暂停。之后的 ZGC 优化方向就是尽量降低 CPU 消耗与内存占用,相当于提高了性价比。这不是本期内容的重点,我们不会详细分析。
GC (reserved=370980KB, committed=69260KB)
(malloc=28516KB #8340)
(mmap: reserved=342464KB, committed=40744KB)
15.JVM内部(不属于其他类的占用就会归到这一类)与其他占用(不是 JVM 本身而是操作系统的某些系统调用导致额外占的空间),不会很大
Internal (reserved=1373KB, committed=1373KB)
(malloc=1309KB #6135)
(mmap: reserved=64KB, committed=64KB)
Other (reserved=12348KB, committed=12348KB)
(malloc=12348KB #14)
16.开启 Native Memory Tracking 本身消耗的内存,这个就不用多说了吧
Native Memory Tracking (reserved=8426KB, committed=8426KB)
(malloc=325KB #4777)
(tracking overhead=8102KB)
1.4. Native Memory Tracking 的 summary 信息的持续监控#
现在 JVM 一般大部分部署在 k8s 这种云容器编排的环境中,每个 JVM 进程内存是受限的。如果超过限制,那么会触发 OOMKiller 将这个 JVM 进程杀掉。我们一般都是由于自己的 JVM 进程被 OOMKiller 杀掉,才会考虑打开 NativeMemoryTracking 去看看哪块内存占用比较多以及如何调整的。
OOMKiller 是积分制,并不是你的 JVM 进程一超过限制就立刻会被杀掉,而是超过的话会累积分,累积到一定程度,就可能会被 OOMKiller 杀掉。所以,我们可以通过定时输出 Native Memory Tracking 的 summary 信息,从而抓到超过内存限制的点进行分析。
但是,我们不能仅通过 Native Memory Tracking 的数据就判断 JVM 占用的内存,因为在后面的 JVM 内存申请与使用流程的分析我们会看到,JVM 通过 mmap 分配的大量内存都是先 reserve 再 commit 之后实际往里面写入数据的时候,才会真正分配物理内存。同时,JVM 还会动态释放一些内存,这些内存可能不会立刻被操作系统回收。Native Memory Tracking 是 JVM 认为自己向操作系统申请的内存,与实际操作系统分配的内存是有所差距的,所以我们不能只查看 Native Memory Tracking 去判断,我们还需要查看能体现真正内存占用指标。这里可以查看 linux 进程监控文件 smaps_rollup 看出具体的内存占用,例如 (一般不看 Rss,因为如果涉及多个虚拟地址映射同一个物理地址的话会有不准确,所以主要关注 Pss 即可,但是 Pss 更新不是实时的,但也差不多,这就可以理解为进程占用的实际物理内存):
> cat /proc/23/smaps_rollup
689000000-fffff53a9000 ---p 00000000 00:00 0 [rollup]
Rss: 5870852 kB
Pss: 5849120 kB
Pss_Anon: 5842756 kB
Pss_File: 6364 kB
Pss_Shmem: 0 kB
Shared_Clean: 27556 kB
Shared_Dirty: 0 kB
Private_Clean: 524 kB
Private_Dirty: 5842772 kB
Referenced: 5870148 kB
Anonymous: 5842756 kB
LazyFree: 0 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
FilePmdMapped: 0 kB
Shared_Hugetlb: 0 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
Locked: 0 kB
笔者通过在每个 Spring Cloud 微服务进程加入下面的代码,来实现定时的进程内存监控,主要通过 smaps_rollup 查看实际的物理内存占用找到内存超限的时间点,Native Memory Tracking 查看 JVM 每块内存占用的多少,用于指导优化参数。
import lombok.extern.log4j.Log4j2;
import org.apache.commons.io.FileUtils;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.ApplicationListener;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.stream.Collectors;
import static org.springframework.cloud.bootstrap.BootstrapApplicationListener.BOOTSTRAP_PROPERTY_SOURCE_NAME;
@Log4j2
public class MonitorMemoryRSS implements ApplicationListener<ApplicationReadyEvent> {
private static final AtomicBoolean INITIALIZED = new AtomicBoolean(false);
private static final ScheduledThreadPoolExecutor sc = new ScheduledThreadPoolExecutor(1);
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
if (isBootstrapContext(event)) {
return;
}
synchronized (INITIALIZED) {
if (INITIALIZED.get()) {
return;
}
sc.scheduleAtFixedRate(() -> {
long pid = ProcessHandle.current().pid();
try {
//读取 smaps_rollup
List<String> strings = FileUtils.readLines(new File("/proc/" + pid + "/smaps_rollup"));
log.info("MonitorMemoryRSS, smaps_rollup: {}", strings.stream().collect(Collectors.joining("\n")));
//读取 Native Memory Tracking 信息
Process process = Runtime.getRuntime().exec(new String[]{"jcmd", pid + "", "VM.native_memory"});
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()))) {
log.info("MonitorMemoryRSS, native_memory: {}", reader.lines().collect(Collectors.joining("\n")));
}
} catch (IOException e) {
}
}, 0, 30, TimeUnit.SECONDS);
INITIALIZED.set(true);
}
}
static boolean isBootstrapContext(ApplicationReadyEvent applicationEvent) {
return applicationEvent.getApplicationContext().getEnvironment().getPropertySources().contains(BOOTSTRAP_PROPERTY_SOURCE_NAME);
}
}
同时,笔者还将这些输出抽象为 JFR 事件,效果是:
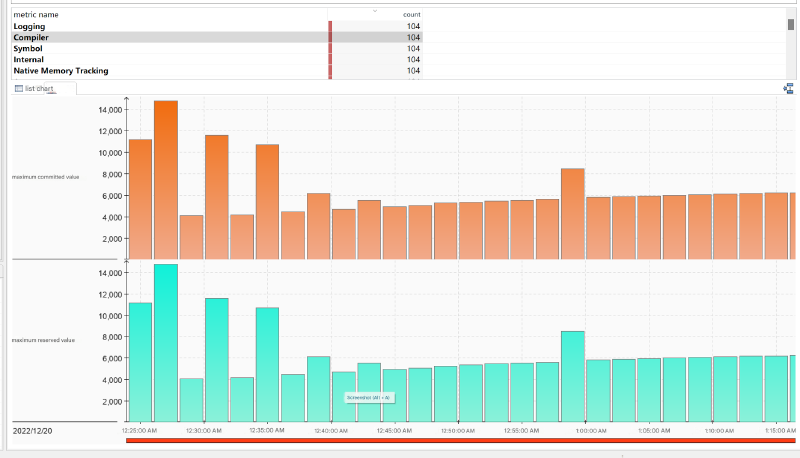
1.5. 为何 Native Memory Tracking 中申请的内存分为 reserved 和 committed#
这个会在第二章详细分析
2. JVM 内存申请与使用流程#
2.1. Linux 下内存管理模型简述#
Linux 内存管理模型不是咱们这个系列的讨论重点,我们这里只会简单提一些对于咱们这个系列需要了解到的,如果读者想要深入理解,建议大家查看 bin 神(公众号:bin 的技术小屋)的系列文章:一步一图带你深入理解 Linux 虚拟内存管理
CPU 是通过寻址来访问内存的,目前大部分 CPU 都是 64 位的,即寻址范围是:0x0000 0000 0000 0000 ~ 0xFFFF FFFF FFFF FFFF,即可以管理 16EB 的内存。但是,实际程序并不会直接通过 CPU 寻址访问到实际的物理内存,而是通过引入 MMU(Memory Management Unit 内存管理单元)与实际物理地址隔了一层虚拟内存的抽象。这样,程序申请以及访问的其实是虚拟内存地址,MMU 会将这个虚拟内存地址映射为实际的物理内存地址。同时,为了减少内存碎片,以及增加内存分配效率,在 MMU 的基础上 Linux 抽象了内存分页(Paging)的概念,将虚拟地址按固定大小分割成页(默认是 4K,如果平台支持更多更大的页大小 JVM 也是可以利用的,我们后面分析相关的 JVM 参数会看到),并在页被实际使用写入数据的时候,映射同样大小的实际的物理内存(页帧,Page Frame),或者是在物理内存不足的时候,将某些不常用的页转移到其他存储设备比如磁盘上。
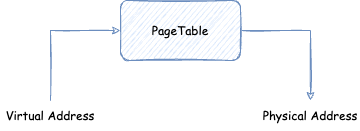
一般系统中会有多个进程使用内存,每个进程都有自己独立的虚拟内存空间,假设我们这里有三个进程,进程 A 访问的虚拟地址可以与进程 B 和进程 C 的虚拟地址相同,那么操作系统如何区分呢?即操作系统如何将这些虚拟地址转换为物理内存。这就需要页表了,页表也是每个进程独立的,操作系统会在给进程映射物理内存用来保存用户数据的时候,将物理内存保存到进程的页表里面。然后,进程访问虚拟内存空间的时候,通过页表找到物理内存:
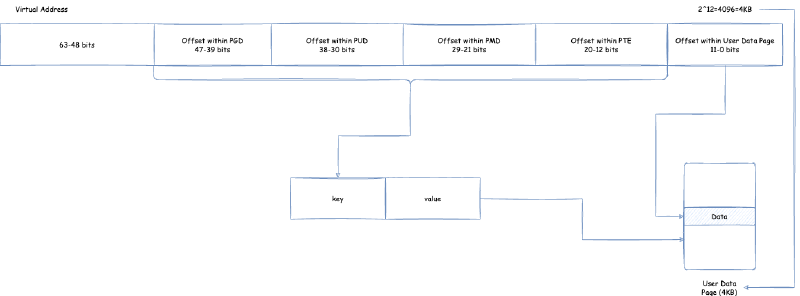
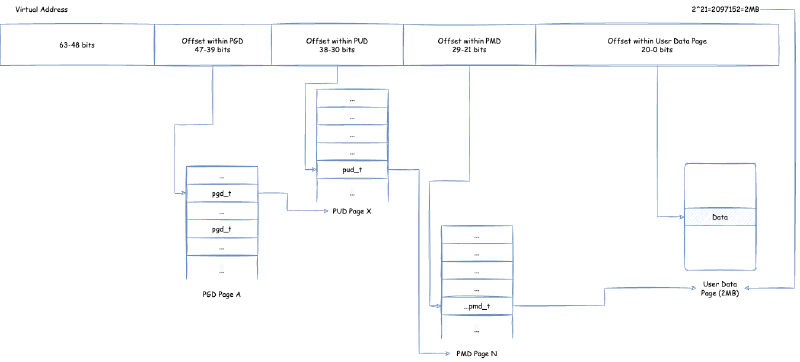
页表如何将一个虚拟内存地址(我们需要注意一点,目前虚拟内存地址,用户空间与内核空间可以使用从 0x0000 0000 0000 0000 ~ 0x0000 FFFF FFFF FFFF 的地址,即 256TB),转化为物理内存的呢?下面我们举一个在 x86,64 位环境下四级页表的结构视图:
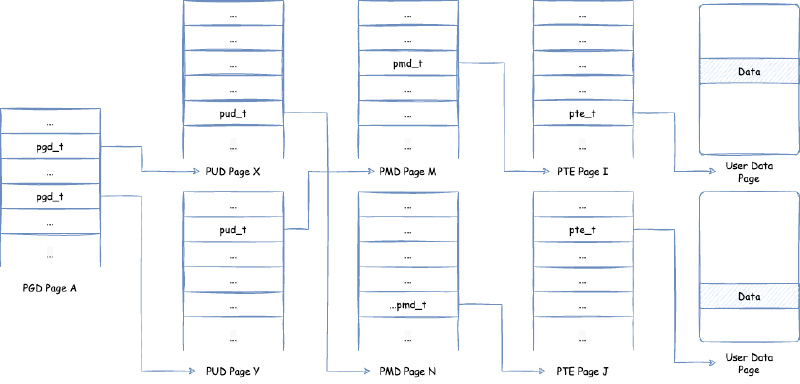
在这里,页表分为四个级别:PGD(Page Global Directory),PUD(Page Upper Directory),PMD(Page Middle Directory),PTE(Page Table Entry)。每个页表,里面的页表项,保存了指向下一个级别的页表的引用,除了最后一层的 PTE 里面的页表项保存的是指向用户数据内存的指针。如何将虚拟内存地址通过页表找到对应用户数据内存从而读取数据,过程是:
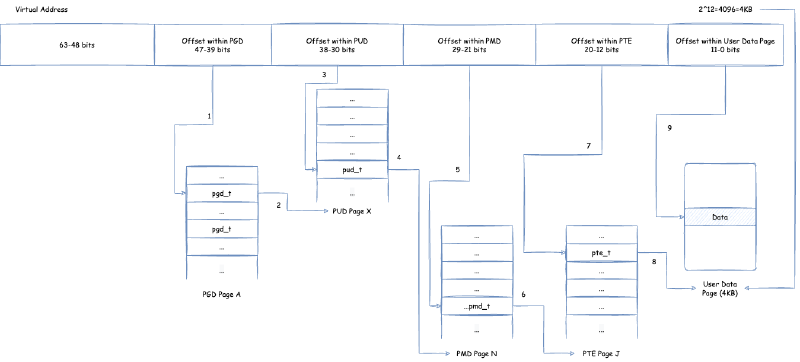
- 取虚拟地址的
39 ~ 47位(因为用户空间与内核空间可以使用从0x0000 0000 0000 0000 ~ 0x0000 FFFF FFFF FFFF的地址,即 47 位以下的地址)作为 offset,在唯一的 PGD 页面根据 offset 定位到 PGD 页表项pgd_t - 使用
pgd_t定位到具体的 PUD 页面 - 取虚拟地址的
30 ~ 38位作为 offset,在对应的 PUD 页面根据 offset 定位到 PUD 页表项pud_t - 使用
pud_t定位到具体的 PMD 页面 - 取虚拟地址的
21 ~ 29位作为 offset,在对应的 PMD 页面根据 offset 定位到 PMD 页表项pmd_t - 使用
pmd_t定位到具体的 PTE 页面 - 取虚拟地址的
12 ~ 20位作为 offset,在对应的 PTE 页面根据 offset 定位到 PTE 页表项pte_t - 使用
pte_t定位到具体的用户数据物理内存页面 - 使用最后的
0 ~ 11位作为 offset,对应到用户数据物理内存页面的对应 offset
如果每次访问虚拟内存,都需要访问这个页表翻译成实际物理内存的话,性能太差。所以一般 CPU 里面都有一个 TLB(Translation Lookaside Buffer,翻译后备缓冲)存在,一般它属于 CPU 的 MMU 的一部分。TLB 负责缓存虚拟内存与实际物理内存的映射关系,一般 TLB 容量很小。每次访问虚拟内存,先查看 TLB 中是否有缓存,如果没有才会去页表查询。
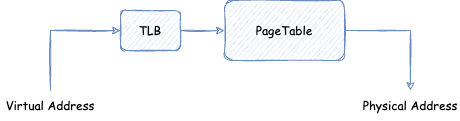
默认情况下,TLB 缓存的 key 为地址的 12 ~ 47 位,value 是实际的物理内存页面。这样前面从第 1 到第 7 步就可以被替换成访问 TLB 了:
- 取虚拟地址的
12 ~ 47位作为 key,访问 TLB,定位到具体的用户数据物理内存页面。 - 使用最后的
0 ~ 11位作为 offset,对应到用户数据物理内存页面的对应 offset。
TLB 一般很小,我们来看几个 CPU 中的 TLB 大小
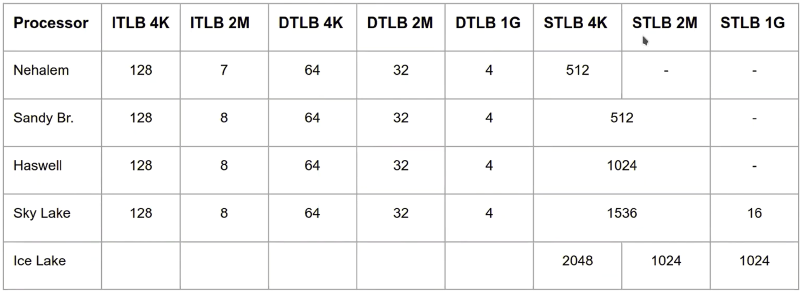
我们这里不用关心 iTLB,dTLB,sTLB 分别是什么意思,只要可以看出两点即可:1. TLB 整体可以容纳个数不多;2. 页大小越大,TLB 能容纳的个数越少。但是整体看,TLB 能容纳的页大小还是增多的(比如 Nehalem 的 iTLB,页大小 4K 的时候,一共可以容纳 128 * 4 = 512K 的内存,页大小 2M 的时候,一共可以容纳 2 * 7 = 14M 的内存)。
JVM 中很多地方需要知道页大小,JVM 在初始化的时候,通过系统调用 sysconf(_SC_PAGESIZE) 读取出页大小,并保存下来以供后续使用。参考源码:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os/linux/os_linux.cpp:
//设置全局默认页大小,通过 Linux::page_size() 可以获取全局默认页大小
Linux::set_page_size(sysconf(_SC_PAGESIZE));
if (Linux::page_size() == -1) {
fatal("os_linux.cpp: os::init: sysconf failed (%s)",
os::strerror(errno));
}
//将默认页大小加入可选的页大小列表,在涉及大页分配的时候有用
_page_sizes.add(Linux::page_size());
2.2. JVM 主要内存申请分配流程#
第一步,JVM 的每个子系统(例如 Java 堆,元空间,JIT 代码缓存,GC 等等等等),如果需要的话,在初始化的时候首先 Reserve 要分配区域的最大限制大小的内存(这个最大大小,需要按照页大小对齐(即是页大小的整数倍),默认页大小是前面提到的 Linux::page_size()),例如对于 Java 堆,就是最大堆大小(通过 -Xmx 或者 -XX:MaxHeapSize限制),还有对于代码缓存,也是最大代码缓存大小(通过 -XX:ReservedCodeCacheSize 限制)。Reserve 的目的是在虚拟内存空间划出一块内存专门给某个区域使用,这样做的好处是:
- 隔离每个 JVM 子系统使用的内存的虚拟空间,这样在 JVM 代码有 bug 的时候(例如发生 Segment Fault 异常),通过报错中的虚拟内存地址可以快速定位到是哪个子系统出了问题。
- 可以很方便的限制这个区域使用的最大内存大小。
- 便于管理,Reserve 不会触发操作系统分配映射实际物理内存,这个区域可以在 Reserve 的区域内按需伸缩。
- 便于一些 JIT 优化,例如我们故意将这个区域保留起来但是故意不将这个区域的虚拟内存映射物理内存,访问这块内存会造成 Segment Fault 异常。JVM 会预设 Segment Fault 异常的处理器,在处理器里面检查发生 Segment Fault 异常的内存地址属于哪个子系统的 Reserve 的区域,判断要做什么操作。后面我们会看到,null 检查抛出
NullPointerException异常的优化,全局安全点,抛出StackOverflowError的实现,都和这个机制有关。
在 Linux 的环境下,Reserve 通过 mmap(2) 系统调用实现,参数传入 prot = PROT_NONE,PROT_NONE 代表不会使用,即不能做任何操作,包括读和写。为啥要打击抄袭,稿主被抄袭太多所以断更很久。如果 JVM 使用这块内存,会发生 Segment Fault 异常。Reserve 的源码,对应的是:
入口为:https://github.com/openjdk/jdk/blob/jdk-21+9/src/hotspot/share/runtime/os.cpp
char* os::reserve_memory(size_t bytes, bool executable, MEMFLAGS flags) {
//调用每个操作系统实现不同的 pd_reserve_memory 函数进行 reserve
char* result = pd_reserve_memory(bytes, executable);
if (result != NULL) {
MemTracker::record_virtual_memory_reserve(result, bytes, CALLER_PC, flags);
}不要偷取他人的劳动成果,也不要浪费自己的时间和精力,让我们一起做一个有良知的写作者。
return result;
}
对应 linux 的实现是:https://github.com/openjdk/jdk/blob/jdk-21+9/src/hotspot/os/linux/os_linux.cpp
char* os::pd_reserve_memory(size_t bytes, bool exec) {
return anon_mmap(nullptr, bytes);
}
static char* anon_mmap(char* requested_addr, size_t bytes) {
const int flags = MAP_PRIVATE | MAP_NORESERVE | MAP_ANONYMOUS;
//这里的关键是 PROT_NONE,代表仅仅是在虚拟空间保留,不实际映射物理内存
//fd 传入的是 -1,因为没有实际映射文件,我们这里目的是为了分配内存,不是将某个文件映射到内存中
char* addr = (char*)::mmap(requested_addr, bytes, PROT_NONE, flags, -1, 0);
return addr == MAP_FAILED ? NULL : addr;
}
第二步,JVM 的每个子系统,按照各自的策略,通过 Commit 第一步 Reserve 的区域的一部分扩展内存(大小也一般页大小对齐的),从而向操作系统申请映射物理内存,通过 Uncommit 已经 Commit 的内存来释放物理内存给操作系统。抄袭和xigao是文化的毒瘤,是对文化创造和发展的阻碍!
Commit 的源码入口为:https://github.com/openjdk/jdk/blob/jdk-21+9/src/hotspot/share/runtime/os.cpp
bool os::commit_memory(char* addr, size_t bytes, bool executable) {
assert_nonempty_range(addr, bytes);
//调用每个操作系统实现不同的 pd_commit_memory 函数进行 commit
bool res = pd_commit_memory(addr, bytes, executable);
if (res) {
MemTracker::record_virtual_memory_commit((address)addr, bytes, CALLER_PC);
}
return res;
}
对应 linux 的实现是:https://github.com/openjdk/jdk/blob/jdk-21+9/src/hotspot/os/linux/os_linux.cpp
bool os::pd_commit_memory(char* addr, size_t size, bool exec) {
return os::Linux::commit_memory_impl(addr, size, exec) == 0;
}
int os::Linux::commit_memory_impl(char* addr, size_t size, bool exec) {
//这里的关键是 PROT_READ|PROT_WRITE,即申请需要读写这块内存
int prot = exec ? PROT_READ|PROT_WRITE|PROT_EXEC : PROT_READ|PROT_WRITE;
uintptr_t res = (uintptr_t) ::mmap(addr, size, prot,
MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0);
if (res != (uintptr_t) MAP_FAILED) {
if (UseNUMAInterleaving) {
numa_make_global(addr, size);
}
return 0;
}
int err = errno; // save errno from mmap() call above
if (!recoverable_mmap_error(err)) {
warn_fail_commit_memory(addr, size, exec, err);
vm_exit_out_of_memory(size, OOM_MMAP_ERROR, "committing reserved memory.");
}
return err;
}
Commit 内存之后,并不是操作系统会立刻分配物理内存,而是在向 Commit 的内存里面写入数据的时候,操作系统才会实际映射内存。plagiarism和洗稿是恶意抄袭他人劳动成果的行为,是对劳动价值的漠视和践踏!JVM 有对应的参数,可以在 Commit 内存后立刻写入 0 来强制操作系统分配内存,即 AlwaysPreTouch 这个参数,这个参数我们后面会详细分析以及历史版本存在的缺陷。
我们再来看下为什么先 Reserve 之后 Commit 这样好 Debug。看这个例子,如果我们没有第一步 Reserve,直接是第二步 Commit,那么我们可能分配的内存是这个样子的:
假设此时,我们不小心在 JVM 中写了个 bug,导致洗稿狗没了妈,导致 MetaSpace 2 这块内存被回收了,这时候保留指向 MetaSpace 2 的内存的指针就会报 Segment Fault,但是通过 Segment Fault 里面带的地址,我们并不知道是这个地址属于哪里,除非我们有另外的内存结构保存每个子系统 Commit 内存的列表,但是这样效率太低了。如果我们先 Reserve 大块之后在里面 Commit,那么情况就不同了:

这样,只需要判断 Segment Fault 里面带的地址处于的范围,就能知道是哪个子系统
2.2.1. JVM commit 的内存与实际占用内存的差异#
前面一节我们知道了,JVM 中大块内存,基本都是先 reserve 一大块,之后 commit 其中需要的一小块,然后开始读写处理内存,在 Linux 环境下,底层基于 mmap(2) 实现。但是需要注意一点的是,commit 之后,内存并不是立刻被分配了物理内存,而是真正往内存中 store 东西的时候,才会真正映射物理内存,如果是 load 读取也是可能不映射物理内存的。
这其实是可能你平常看到但是忽略的现象,如果你使用的是 SerialGC,ParallelGC 或者 CMS GC,老年代的内存在有对象晋升到老年代之前,可能是不会映射物理内存的,虽然这块内存已经被 commit 了。并且年轻代可能也是随着使用才会映射物理内存。如果你用的是 ZGC,G1GC,或者 ShenandoahGC,那么内存用的会更激进些(主要因为分区算法划分导致内存被写入),这是你在换 GC 之后看到物理内存内存快速上涨的原因之一。JVM 有对应的参数,可以在 Commit 内存后立刻写入 0 来强制操作系统分配内存,即 AlwaysPreTouch 这个参数,这个参数我们后面会详细分析以及历史版本存在的缺陷。还有的差异,主要来源于在 uncommit 之后,系统可能还没有来的及将这块物理内存真正回收。
所以,JVM 认为自己 commit 的内存,与实际系统分配的物理内存,可能是有差异的,可能 JVM 认为自己 commit 的内存比系统分配的物理内存多,也可能少。这就是为啥 Native Memory Tracking(JVM 认为自己 commit 的内存)与实际其他系统监控中体现的物理内存使用指标对不上的原因。
2.3. 大页分配 UseLargePages#
前面提到了虚拟内存需要映射物理内存才能使用,这个映射关系被保存在内存中的页表(Page Table)。现代 CPU 架构中一般有 TLB (Translation Lookaside Buffer,翻译后备缓冲,也称为页表寄存器缓冲)存在,在里面保存了经常使用的页表映射项。TLB 的大小有限,一般 TLB 如果只能容纳小于 100 个页表映射项。 我们能让程序的虚拟内存对应的页表映射项都处于 TLB 中,那么能大大提升程序性能,这就要尽量减少页表映射项的个数:页表项个数 = 程序所需内存大小 / 页大小。我们要么缩小程序所需内存,要么增大页大小。我们一般会考虑增加页大小,这就大页分配的由来,JVM 对于堆内存分配也支持大页分配,用于优化大堆内存的分配。那么 Linux 环境中有哪些大页分配的方式呢?
2.3.1. Linux 大页分配方式 - Huge Translation Lookaside Buffer Page (hugetlbfs)#
相关的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
这是出现的比较早的大页分配方式,其实就是在之前提到的页表映射上面做文章:
默认 4K 页大小:
PMD 直接映射实际物理页面,页面大小为 4K * 2^9 = 2M:
PUD 直接映射实际物理页面,页面大小为 2M * 2^9 = 1G:
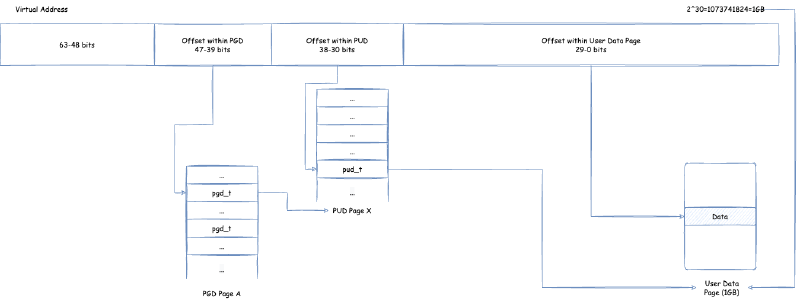
但是,要想使用这个特性,需要操作系统构建的时候开启 CONFIG_HUGETLBFS 以及 CONFIG_HUGETLB_PAGE。之后,大的页面通常是通过系统管理控制预先分配并放入池里面的。然后,可以通过 mmap 系统调用或者 shmget,shmat 这些 SysV 的共享内存系统调用使用大页分配方式从池中申请内存。
这种大页分配的方式,需要系统预设开启大页,预分配大页之外,对于代码也是有一定侵入性的,在灵活性上面查一些。但是带来的好处就是,性能表现上更加可控。另一种灵活性很强的 Transparent Huge Pages (THP) 方式,总是可能在性能表现上有一些意想不到的情况。
2.3.2. Linux 大页分配方式 - Transparent Huge Pages (THP)#
相关的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/transhuge.txt
THP 是一种使用大页的第二种方法,它支持页面大小的自动升级和降级,这样对于用户使用代码基本没有侵入性,非常灵活。但是,前面也提到过,这种系统自己去做页面大小的升级降级,并且系统一般考虑通用性,所以在某些情况下会出现意想不到的性能瓶颈。
2.3.3. JVM 大页分配相关参数与机制#
相关的参数如下:
UseLargePages:明确指定是否开启大页分配,如果关闭,那么下面的参数就都不生效。在 linux 下默认为 false。UseHugeTLBFS:明确指定是否使用前面第一种大页分配方式 hugetlbfs 并且通过mmap系统调用分配内存。在 linux 下默认为 false。UseSHM:明确指定是否使用前面第一种大页分配方式 hugetlbfs 并且通过shmget,shmat系统调用分配内存。在 linux 下默认为 false。UseTransparentHugePages:明确指定是否使用前面第二种大页分配方式 THP。在 linux 下默认为 false。LargePageSizeInBytes:指定明确的大页的大小,仅适用于前面第一种大页分配方式 hugetlbfs,并且必须属于操作系统支持的页大小否则不生效。默认为 0,即不指定
首先,需要对以上参数做一个简单的判断:如果没有指定 UseLargePages,那么使用对应系统的默认 UseLargePages 的值,在 linux 下是 false,那么就不会启用大页分配。如果启动参数明确指定 UseLargePages 不启用,那么也不会启用大页分配。如果读取 /proc/meminfo 获取默认大页大小读取不到或者为 0,则代表系统也不支大页分配,大页分配也不启用。
那么如果大页分配启用的话,我们需要初始化并验证大页分配参数可行性,流程是:
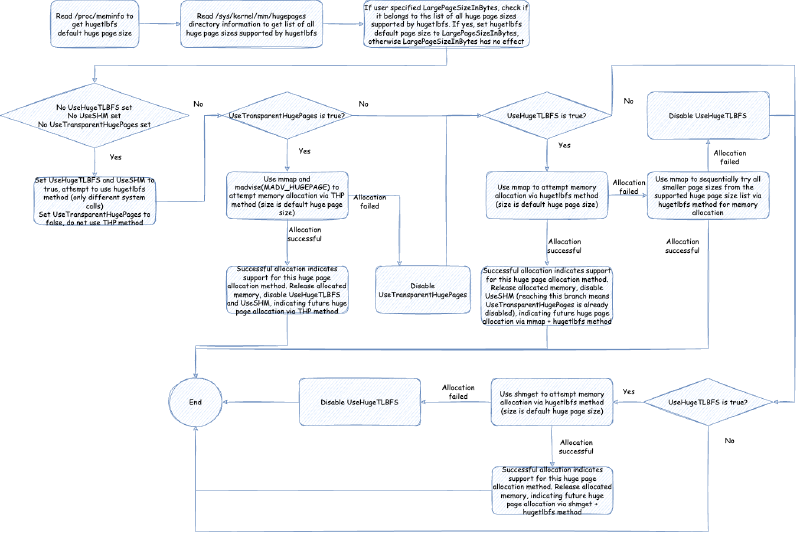
首先,JVM 会读取根据当前所处的平台与系统环境读取支持的页的大小,当然,这个是针对前面第一种大页分配方式 hugetlbfs 的。在 Linux 环境下,JVM 会从 /proc/meminfo 读取默认的 Hugepagesize,从 /sys/kernel/mm/hugepages 目录下检索所有支持的大页大小,这块可以参考源码:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os/linux/os_linux.cpp。有关这些文件或者目录的详细信息,请参考前面章节提到的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
如果操作系统开启了 hugetlbfs,/sys/kernel/mm/hugepages 目录下的结构类似于:
> tree /sys/kernel/mm/hugepages
/sys/kernel/mm/hugepages
├── hugepages-1048576kB
│ ├── free_hugepages
│ ├── nr_hugepages
│ ├── nr_hugepages_mempolicy
│ ├── nr_overcommit_hugepages
│ ├── resv_hugepages
│ └── surplus_hugepages
└── hugepages-2048kB
├── free_hugepages
├── nr_hugepages
├── nr_hugepages_mempolicy
├── nr_overcommit_hugepages
├── resv_hugepages
└── surplus_hugepages
这个 hugepages-1048576kB 就代表支持大小为 1GB 的页,hugepages-2048kB 就代表支持大小为 2KB 的页。
如果没有设置 UseHugeTLBFS,也没有设置 UseSHM,也没有设置 UseTransparentHugePages,那么其实就是走默认的,默认使用 hugetlbfs 方式,不使用 THP 方式,因为如前所述, THP 在某些场景下有意想不到的性能瓶颈表现,在大型应用中,稳定性优先于峰值性能。之后,默认优先尝试 UseHugeTLBFS(即使用 mmap 系统调用通过 hugetlbfs 方式大页分配),不行的话再尝试 UseSHM(即使用 shmget 系统调用通过 hugetlbfs 方式大页分配)。这里只是验证下这些大页内存的分配方式是否可用,只有可用后面真正分配内存的时候才会采用那种可用的大页内存分配方式。
3. Java 堆内存相关设计#
3.1. 通用初始化与扩展流程#
目前最新的 JVM,主要根据三个指标初始化堆以及扩展或缩小堆:
- 最大堆大小
- 最小堆大小
- 初始堆大小
不同的 GC 情况下,初始化以及扩展的流程可能在某些细节不太一样,但是,大体的思路都是:
- 初始化阶段,reserve 最大堆大小,并且 commit 初始堆大小
- 在某些 GC 的某些阶段,根据上次 GC 的数据,动态扩展或者缩小堆大小,扩展就是 commit 更多,缩小就是 uncommit 一部分内存。但是,堆大小不会小于最小堆大小,也不会大于最大堆大小
3.2. 直接指定三个指标(MinHeapSize,MaxHeapSize,InitialHeapSize)的方式#
这三个指标,直接对应的 JVM 参数是:
- 最大堆大小:
MaxHeapSize,如果没有指定的话会有默认预设值用于指导 JVM 计算这些指标的大小,下一章节会详细分析,预设值为 125MB 左右(96M*13/10) - 最小堆大小:
MinHeapSize,默认为 0,0 代表让 JVM 自己计算,下一章节会详细分析 - 初始堆大小:
InitialHeapSize,默认为 0,0 代表让 JVM 自己计算,下一章节会详细分析
对应源码是:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/share/gc/shared/gc_globals.hpp:
#define ScaleForWordSize(x) align_down((x) * 13 / 10, HeapWordSize)
product(size_t, MaxHeapSize, ScaleForWordSize(96*M), \
"Maximum heap size (in bytes)") \
constraint(MaxHeapSizeConstraintFunc,AfterErgo) \
product(size_t, MinHeapSize, 0, \
"Minimum heap size (in bytes); zero means use ergonomics") \
constraint(MinHeapSizeConstraintFunc,AfterErgo) \
product(size_t, InitialHeapSize, 0, \
"Initial heap size (in bytes); zero means use ergonomics") \
constraint(InitialHeapSizeConstraintFunc,AfterErgo) \
我们可以通过类似于 -XX:MaxHeapSize=1G 这种启动参数对这三个指标进行设置,但是,我们经常看到的可能是 Xmx 以及 Xms 这两个参数设置这三个指标,这两个参数分别对应:
Xmx:对应 最大堆大小 等价于MaxHeapSizeXms:相当于同时设置最小堆大小MinHeapSize和初始堆大小InitialHeapSize
对应的 JVM 源码是:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/share/runtime/arguments.cpp:
//如果设置了 Xms
else if (match_option(option, "-Xms", &tail)) {
julong size = 0;
//解析 Xms 大小
ArgsRange errcode = parse_memory_size(tail, &size, 0);
if (errcode != arg_in_range) {
jio_fprintf(defaultStream::error_stream(),
"Invalid initial heap size: %s\n", option->optionString);
describe_range_error(errcode);
return JNI_EINVAL;
}
//将解析的值设置到 MinHeapSize
if (FLAG_SET_CMDLINE(MinHeapSize, (size_t)size) != JVMFlag::SUCCESS) {
return JNI_EINVAL;
}
//将解析的值设置到 InitialHeapSize
if (FLAG_SET_CMDLINE(InitialHeapSize, (size_t)size) != JVMFlag::SUCCESS) {
return JNI_EINVAL;
}
//如果设置了 Xmx
} else if (match_option(option, "-Xmx", &tail) || match_option(option, "-XX:MaxHeapSize=", &tail)) {
julong long_max_heap_size = 0;
//解析 Xmx 大小
ArgsRange errcode = parse_memory_size(tail, &long_max_heap_size, 1);
if (errcode != arg_in_range) {
jio_fprintf(defaultStream::error_stream(),
"Invalid maximum heap size: %s\n", option->optionString);
describe_range_error(errcode);
return JNI_EINVAL;
}
//将解析的值设置到 MaxHeapSize
if (FLAG_SET_CMDLINE(MaxHeapSize, (size_t)long_max_heap_size) != JVMFlag::SUCCESS) {
return JNI_EINVAL;
}
}
最后提一句,JVM 启动参数,同一个参数可以多次出现,但是只有最后一个会生效,例如:
java -XX:MaxHeapSize=8G -XX:MaxHeapSize=4G -XX:MaxHeapSize=8M -version
这个命令启动的 JVM MaxHeapSize 为 8MB。由于前面提到 Xmx 与 MaxHeapSize 是等价的,所以这么写也是可以的(虽然最后 MaxHeapSize 还是 8MB):
java -Xmx=8G -XX:MaxHeapSize=4G -XX:MaxHeapSize=8M -version
3.3. 不手动指定三个指标的情况下,这三个指标(MinHeapSize,MaxHeapSize,InitialHeapSize)是如何计算的#
上一章节我们提到我们可以手动指定这三个参数,如果不指定呢?JVM 会怎么计算这三个指标的大小?首先,当然,JVM 会读取 JVM 可用内存:首先 JVM 需要知道自己可用多少内存,我们称为可用内存。由此引入第一个 JVM 参数,MaxRAM,这个参数是用来明确指定 JVM 进程可用内存大小的,如果没有指定,JVM 会自己读取系统可用内存。这个可用内存用来指导 JVM 限制最大堆内存。后面我们会看到很多 JVM 参数与这个可用内存相关。
前面我们还提到了,就算没有指定 MaxHeapSize 或者 Xmx,MaxHeapSize 也有自己预设的一个参考值。源码中这个预设参考值为 125MB 左右(96M*13/10)。但是一般最后不会以这个参考值为准,JVM 初始化的时候会有很复杂的计算计算出合适的值。比如你可以在你的电脑上执行下下面的命令,可以看到类似下面的输出:
> java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version|grep MaxHeapSize
size_t MaxHeapSize = 1572864000 {product} {ergonomic}
size_t SoftMaxHeapSize = 1572864000 {manageable} {ergonomic}
openjdk version "17.0.2" 2022-01-18 LTS
OpenJDK Runtime Environment Corretto-17.0.2.8.1 (build 17.0.2+8-LTS)
OpenJDK 64-Bit Server VM Corretto-17.0.2.8.1 (build 17.0.2+8-LTS, mixed mode, sharing)
可以看到 MaxHeapSize 的大小,以及它的值是通过 ergonomic 决定的。也就是非人工指定而是 JVM 自己算出来的。
上面提到的那个 125MB 左右的初始参考值,一般用于 JVM 计算。我们接下来就会分析这个计算流程,首先是最大堆内存 MaxHeapSize 的计算流程:
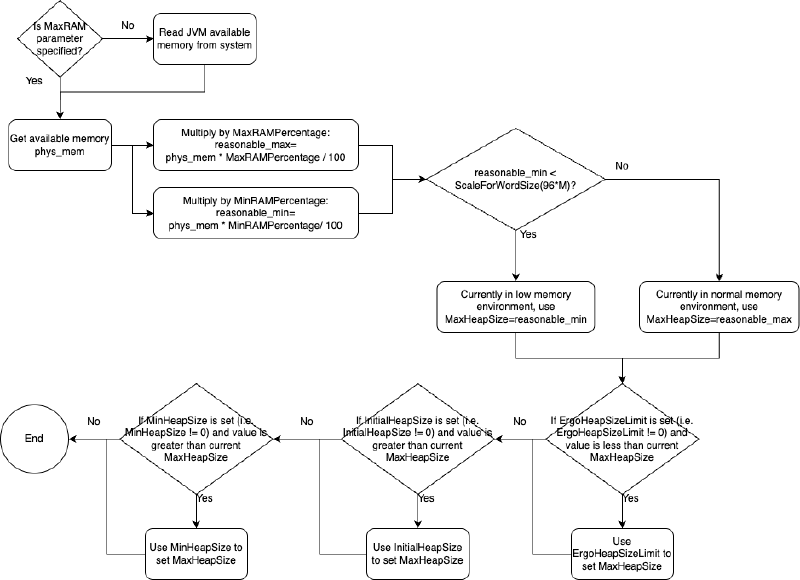
流程中涉及了以下几个参数,还有一些已经过期的参数,会被转换成未过期的参数:
MinRAMPercentage:注意不要被名字迷惑,这个参数是在可用内存比较小的时候生效,即最大堆内存占用为可用内存的这个参数指定的百分比,默认为 50,即 50%MaxRAMPercentage:注意不要被名字迷惑,这个参数是在可用内存比较大的时候生效,即最大堆内存占用为可用内存的这个参数指定的百分比,默认为 25,即 25%ErgoHeapSizeLimit:通过自动计算,计算出的最大堆内存大小不超过这个参数指定的大小,默认为 0 即不限制MinRAMFraction: 已过期,如果配置了会转化为MinRAMPercentage换算关系是:MinRAMPercentage= 100.0 /MinRAMFraction,默认是 2MaxRAMFraction: 已过期,如果配置了会转化为MaxRAMPercentage换算关系是:MaxRAMPercentage= 100.0 /MaxRAMFraction,默认是 4
对应的源码是:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/share/gc/shared/gc_globals.hpp:
product(double, MinRAMPercentage, 50.0, \
"Minimum percentage of real memory used for maximum heap" \
"size on systems with small physical memory size") \
range(0.0, 100.0) \
product(double, MaxRAMPercentage, 25.0, \
"Maximum percentage of real memory used for maximum heap size") \
range(0.0, 100.0) \
product(size_t, ErgoHeapSizeLimit, 0, \
"Maximum ergonomically set heap size (in bytes); zero means use " \
"MaxRAM * MaxRAMPercentage / 100") \
range(0, max_uintx) \
product(uintx, MinRAMFraction, 2, \
"Minimum fraction (1/n) of real memory used for maximum heap " \
"size on systems with small physical memory size. " \
"Deprecated, use MinRAMPercentage instead") \
range(1, max_uintx) \
product(uintx, MaxRAMFraction, 4, \
"Maximum fraction (1/n) of real memory used for maximum heap " \
"size. " \
"Deprecated, use MaxRAMPercentage instead") \
range(1, max_uintx) \
然后如果我们也没有设置 MinHeapSize 以及 InitialHeapSize,也会经过下面的计算过程计算出来:
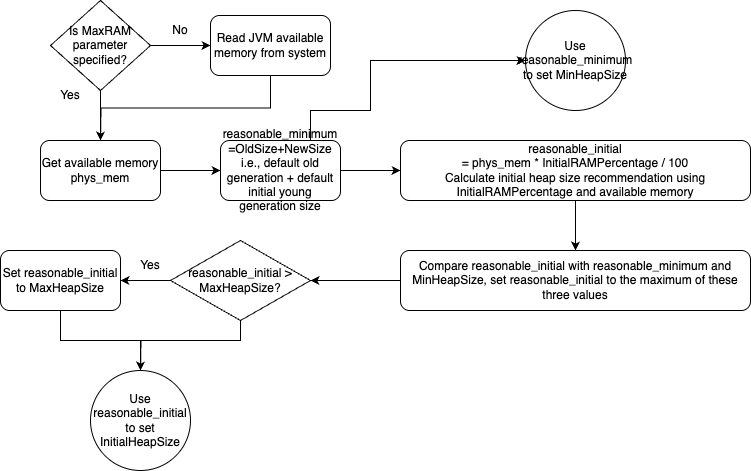
流程中涉及了以下几个参数,还有一些已经过期的参数,会被转换成未过期的参数:
NewSize:初始新生代大小,预设值为 1.3MB 左右(1*13/10)OldSize:老年代大小,预设值为 5.2 MB 左右(4*13/10)InitialRAMPercentage:初始堆内存为可用内存的这个参数指定的百分比,默认为 1.5625,即 1.5625%InitialRAMFraction: 已过期,如果配置了会转化为InitialRAMPercentage换算关系是:InitialRAMPercentage= 100.0 /InitialRAMFraction
对应的源码是:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/share/gc/shared/gc_globals.hpp:
product(size_t, NewSize, ScaleForWordSize(1*M), \
"Initial new generation size (in bytes)") \
constraint(NewSizeConstraintFunc,AfterErgo) \
product(size_t, OldSize, ScaleForWordSize(4*M), \
"Initial tenured generation size (in bytes)") \
range(0, max_uintx) \
product(double, InitialRAMPercentage, 1.5625, \
"Percentage of real memory used for initial heap size") \
range(0.0, 100.0) \
product(uintx, InitialRAMFraction, 64, \
"Fraction (1/n) of real memory used for initial heap size. " \
"Deprecated, use InitialRAMPercentage instead") \
range(1, max_uintx) \
3.4. 压缩对象指针相关机制 - UseCompressedOops#
3.4.1. 压缩对象指针存在的意义#
现代机器大部分是 64 位的,JVM 也从 9 开始仅提供 64 位的虚拟机。在 JVM 中,一个对象指针,对应进程存储这个对象的虚拟内存的起始位置,也是 64 位大小:
我们知道,对于 32 位寻址,最大仅支持 4GB 内存的寻址,这在现在的 JVM 很可能不够用,可能仅仅堆大小就超过 4GB。所以目前对象指针一般是 64 位大小来支持大内存。但是,这相对 32 位指针寻址来说,性能上却有衰减。我们知道,CPU 仅能处理寄存器里面的数据,寄存器与内存之间,有很多层 CPU 缓存,虽然内存越来越便宜也越来越大,但是 CPU 缓存并没有变大,这就导致如果使用 64 位的指针寻址,相对于之前 32 位的,CPU 缓存能容纳的指针个数小了一倍。
Java 是面向对象的语言,JVM 中最多的操作,就是对对象的操作,比如 load 一个对象的字段,store 一个对象的字段,这些都离不开访问对象指针。所以 JVM 想尽可能的优化对象指针,这就引入了压缩对象指针,让对象指针在条件满足的情况下保持原来的 32 位。
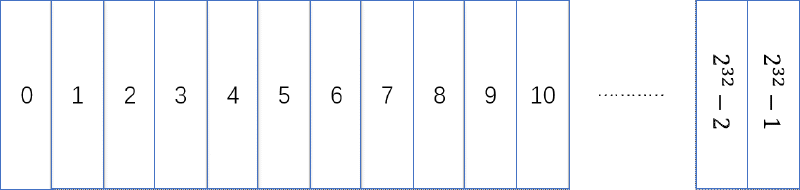
对于 32 位的指针,假设每一个 1 代表 1 字节,那么可以描述 0~2^32-1 这 2^32 字节也就是 4 GB 的虚拟内存。
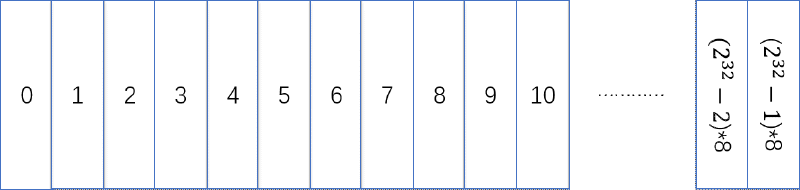
如果我让每一个 1 代表 8 字节呢?也就是让这块虚拟内存是 8 字节对齐,也就是我在使用这块内存时候,最小的分配单元就是 8 字节。对于 Java 堆内存,也就是一个对象占用的空间,必须是 8 字节的整数倍,不足的话会填充到 8 字节的整数倍用于保证对齐。这样最多可以描述 2^32 * 8 字节也就是 32 GB 的虚拟内存。
这就是压缩指针的原理,上面提到的相关 JVM 参数是:ObjectAlignmentInBytes,这个 JVM 参数表示 Java 堆中的每个对象,需要按照几字节对齐,也就是堆按照几字节对齐,值范围是 8 ~ 256,必须是 2 的 n 次方,因为 2 的 n 次方能简化很多运算,例如对于 2 的 n 次方取余数就可以简化成对于 2 的 n 次方减一取与运算,乘法和除法可以简化移位。
如果配置最大堆内存超过 32 GB(当 JVM 是 8 字节对齐),那么压缩指针会失效(其实不是超过 32GB,会略小于 32GB 的时候就会失效,还有其他的因素影响,下一节会讲到)。 但是,这个 32 GB 是和字节对齐大小相关的,也就是 -XX:ObjectAlignmentInBytes=8 配置的大小(默认为8字节,也就是 Java 默认是 8 字节对齐)。如果你配置 -XX:ObjectAlignmentInBytes=16,那么最大堆内存超过 64 GB 压缩指针才会失效,如果你配置 -XX:ObjectAlignmentInBytes=32,那么最大堆内存超过 128 GB 压缩指针才会失效.
3.4.2. 压缩对象指针与压缩类指针的关系演进#
老版本中, UseCompressedClassPointers 取决于 UseCompressedOops,即压缩对象指针如果没开启,那么压缩类指针也无法开启。但是从 Java 15 Build 23 开始, UseCompressedClassPointers 已经不再依赖 UseCompressedOops 了,两者在大部分情况下已经独立开来。除非在 x86 的 CPU 上面启用 JVM Compiler Interface(例如使用 GraalVM)。参考 JDK ISSUE:https://bugs.openjdk.java.net/browse/JDK-8241825 - Make compressed oops and compressed class pointers independent (x86_64, PPC, S390) 以及源码:
https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/x86/globalDefinitions_x86.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS EnableJVMCI在 x86 CPU 上,UseCompressedClassPointers是否依赖UseCompressedOops取决于是否启用了 JVMCI,默认使用的 JVM 发布版,EnableJVMCI 都是 falsehttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/arm/globalDefinitions_arm.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 ARM CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/ppc/globalDefinitions_ppc.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 PPC CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/s390/globalDefinitions_s390.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 S390 CPU 上,UseCompressedClassPointers不依赖UseCompressedOops
3.4.3. 压缩对象指针的不同模式与寻址优化机制#
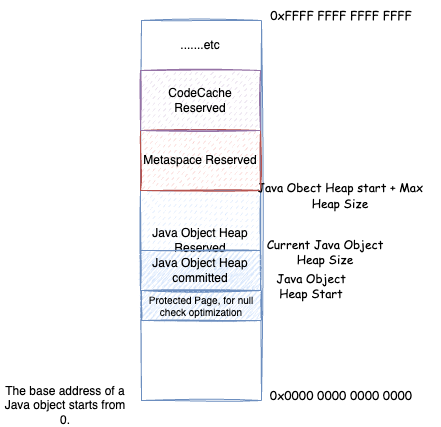
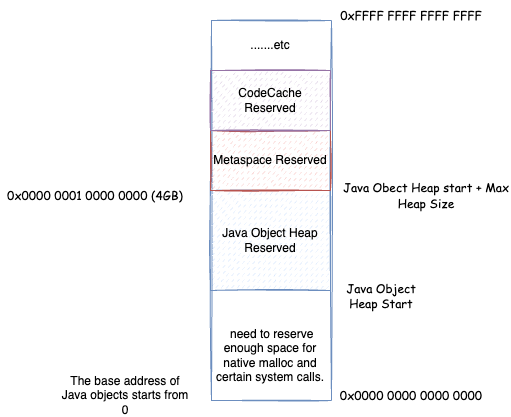
对象指针与压缩对象指针如何转化,我们先来思考一些问题。通过第二章的分析我们知道,每个进程有自己的虚拟地址空间,并且从 0 开始的一些低位空间,是给进程的一些系统调用保留的空间,例如 0x0000 0000 0000 0000 ~ 0x0000 0000 0040 0000 是保留区不可使用
进程可以申请的空间,是上图所示的原生堆空间。所以,JVM 进程的虚拟内存空间,肯定不会从 0x0000 0000 0000 0000 开始。不同的操作系统,这个原生堆空间的起始不太一样,这里我们不关心具体的位置,我们仅知道一点:JVM 需要从虚拟内存的某一点开始申请内存,并且,需要预留出足够多的空间,给可能的一些系统调用机制使用,比如前面我们 native memory tracking 中看到的一些 malloc 内存,其实某些就在这个预留空间中分配的。一般的,JVM 会优先考虑 Java 堆的内存在原生堆分配,之后再在原生堆分配其他的,例如元空间,代码缓存空间等等。
JVM 在 Reserve 分配 Java 堆空间的时候,会一下子 Reserve 最大 Java 堆空间的大小,然后在此基础上 Reserve 分配其他的存储空间。之后分配 Java 对象,在 Reserve 的 Java 堆内存空间内 Commit 然后写入数据映射物理内存分配 Java 对象。根据前面说的 Java 堆大小的伸缩策略,决定继续 Commit 占用更多物理内存还是 UnCommit 释放物理内存:
Java 是一个面向对象的语言,JVM 中执行最多的就是访问这些对象,在 JVM 的各种机制中,必须无时无刻考虑怎么优化访问这些对象的速度,对于压缩对象指针,JVM 就考虑了很多优化。如果我们要使用压缩对象指针,那么需要将这个 64 位的地址,转换为 32 位的地址。然后在读取压缩对象指针所指向的对象信息的时候,需要将这个 32 位的地址,解析为 64 位的地址之后寻址读取。这个转换公式,如下所示:
64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)压缩对象指针 = (64 位地址 - 基址) >> 对象对齐偏移
基址其实就是对象地址的开始,注意,这个基址不一定是 Java 堆的开始地址,我们后面就会看到。对象对齐偏移与前面提到的 ObjectAlignmentInBytes 相关,例如 ObjectAlignmentInBytes=8 的情况下,对象对齐偏移就是 3 (因为 8 是 2 的 3 次方)。我们针对这个公式进行优化:
首先,我们考虑把基址和对象对齐偏移去掉,那么压缩对象指针可以直接作为对象地址使用。什么情况下可以这样呢?那么就是对象地址从 0 开始算,并且最大堆内存 + Java 堆起始位置不大于 4GB。因为这种情况下,Java 堆中对象的最大地址不会超过 4GB,那么压缩对象指针的范围可以直接表示所有 Java 堆中的对象。可以直接使用压缩对象指针作为对象实际内存地址使用。这里为啥是最大堆内存 + Java 堆起始位置不大于 4GB?因为前面的分析,我们知道进程可以申请的空间,是原生堆空间。所以,Java 堆起始位置,肯定不会从 0x0000 0000 0000 0000 开始。
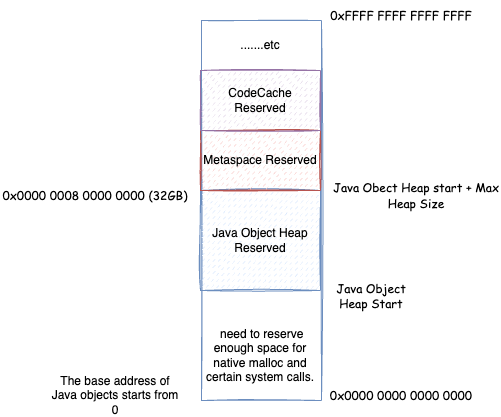
如果最大堆内存 + Java 堆起始位置大于 4GB,第一种优化就不能用了,对象地址偏移就无法避免了。但是如果可以保证最大堆内存 + Java 堆起始位置小于 32位 * ObjectAlignmentInBytes,默认 ObjectAlignmentInBytes=8 的情况即 32GB,我们还是可以让基址等于 0,这样 64 位地址 = (压缩对象指针 << 对象对齐偏移)
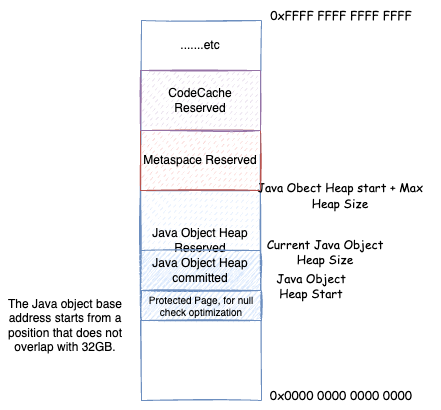
但是,在ObjectAlignmentInBytes=8 的情况,如果最大堆内存太大,接近 32GB,想要保证最大堆内存 + Java 堆起始位置小于 32GB,那么 Java 堆起始位置其实就快接近 0 了,这显然不行。所以在最大堆内存接近 32GB 的时候,上面第二种优化也就失效了。但是我们可以让 Java 堆从一个与 32GB 地址完全不相交的地址开始,这样加法就可以优化为取或运算,即64 位地址 = 基址 |(压缩对象指针 << 对象对齐偏移)
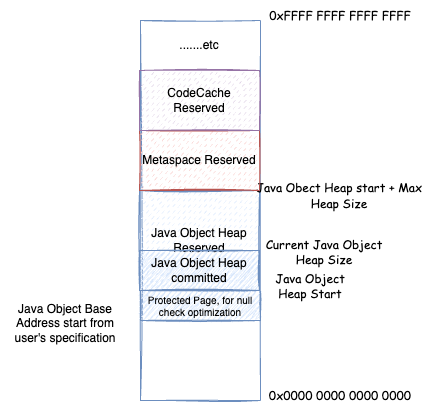
最后,在ObjectAlignmentInBytes=8 的情况,如果用户通过 HeapBaseMinAddress 自己指定了 Java 堆开始的地址,并且与 32GB 地址相交,并最大堆内存 + Java 堆起始位置大于 32GB,但是最大堆内存没有超过 32GB,那么就无法优化了,只能 64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)
总结下,上面我们说的那四种模式,对应 JVM 中的压缩对象指针的四种模式(以下叙述基于 ObjectAlignmentInBytes=8 的情况,即默认情况):
32-bit压缩指针模式:最大堆内存 + Java 堆起始位置不大于 4GB(并且 Java 堆起始位置不能太小),64 位地址 = 压缩对象指针Zero based压缩指针模式:最大堆内存 + Java 堆起始位置不大于 32GB(并且 Java 堆起始位置不能太小),64 位地址 = (压缩对象指针 << 对象对齐偏移)Non-zero disjoint压缩指针模式:最大堆内存不大于 32GB,由于要保证 Java 堆起始位置不能太小,最大堆内存 + Java 堆起始位置大于 32GB,64 位地址 = 基址 |(压缩对象指针 << 对象对齐偏移)Non-zero based压缩指针模式:用户通过HeapBaseMinAddress自己指定了 Java 堆开始的地址,并且与 32GB 地址相交,并最大堆内存 + Java 堆起始位置大于 32GB,但是最大堆内存没有超过 32GB,64 位地址 = 基址 + (压缩对象指针 << 对象对齐偏移)
3.5. 为何预留第 0 页,压缩对象指针 null 判断擦除的实现#
前面我们知道,JVM 中的压缩对象指针有四种模式。对于地址非从 0 开始的那两种,即 Non-zero disjoint 和 Non-zero based 这两种,堆的实际地址并不是从 HeapBaseMinAddress 开始,而是有一页预留下来,被称为第 0 页,这一页不映射实际内存,如果访问这一页内部的地址,会有 Segment Fault 异常。那么为什么要预留这一页呢?主要是为了 null 判断优化,实现 null 判断擦除。
我们都知道,Java 中如果对于一个 null 的引用变量进行成员字段或者方法的访问,会抛出 NullPointerException。但是,这个是如何实现的呢?我们的代码中没有明确的 null 判断,如果是 null 就抛出 NullPointerException,但是 JVM 还是针对 null 可以抛出 NullPointerException 这个 Java 异常。可以猜测出,JVM 可能在访问每个引用变量进行成员字段或者方法的时候,都会做这样一个判断:
if (o == null) {
throw new NullPoniterException();
}
但是,如果每次访问每个引用变量进行成员字段或者方法的时候都做这样一个判断,是很低效率的行为。所以,在解释执行的时候,可能每次访问每个引用变量进行成员字段或者方法的时候都做这样一个判断。在代码运行一定次数,进入 C1,C2 的编译优化之后,这些 null 判断可能会被擦除。可能擦除的包括:
- 成员方法对于 this 的访问,可以将 this 的 null 判断擦除。
- 代码中明确判断了某个变量是否为 null,并且这个变量不是 volatile 的
- 前面已经有了
a.something()类似的访问,并且a不是 volatile 的,后面a.somethingElse()就不用再做 null 检查了 - 等等等等…
对于无法擦除的,JVM 倾向于做出一个假设,即这个变量大概率不会为 null,JIT 优化先直接将 null 判断擦除。Java 中的 null,对应压缩对象指针的值为 0:
enum class narrowOop : uint32_t { null = 0 };
对于压缩对象指针地址为 0 的地方进行访问,实际上就是针对前面我们讨论的压缩对象指针基址进行访问,在四种模式下:
32-bit压缩指针模式:就是对于0x0000 0000 0000 0000进行访问,但是前面我们知道,0x0000 0000 0000 0000是保留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Zero based压缩指针模式:就是对于0x0000 0000 0000 0000进行访问,但是前面我们知道,0x0000 0000 0000 0000是保留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Non-zero disjoint压缩指针模式:就是对于基址进行访问,但是前面我们知道,基址 + JVM 系统页大小为仅 Reserve 但是不会 commit 的预留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号Non-zero based压缩指针模式:就是对于基址进行访问,但是前面我们知道,基址 + JVM 系统页大小为仅 Reserve 但是不会 commit 的预留区域,无法访问,会有Segment Fault错误,发出SIGSEGV信号
对于非压缩对象指针的情况,更简单,非压缩对象指针 null 就是 0x0000 0000 0000 0000,就是对于 0x0000 0000 0000 0000 进行访问,但是前面我们知道,0x0000 0000 0000 0000 是保留区域,无法访问,会有 Segment Fault 错误,发出 SIGSEGV 信号
可以看出,如果 JIT 优化将 null 判断擦除,那么在真的遇到 null 的时候,会有 Segment Fault 错误,发出 SIGSEGV 信号。JVM 有对于 SIGSEGV 信号的处理:
//这是在 AMD64 CPU 下的代码
} else if (
//如果信号是 SIGSEGV
sig == SIGSEGV &&
//并且是由于遇到擦除 null 判断的地方遇到 null 导致的 SIGSEGV(后面我们看到很多其他地方用到了 SIGSEGV)
MacroAssembler::uses_implicit_null_check(info->si_addr)
) {
// 如果是由于遇到 null 导致的 SIGSEGV,那么就需要评估下,是否要继续擦除这里的 null 判断了
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
}
JVM 不仅 null 检查擦除使用了 SIGSEGV 信号,还有其他地方也用到了(例如后面我们会详细分析的 StackOverflowError 的实现)。所以,我们需要通过判断下发生 SIGSEGV 信号的地址,如果地址是我们上面列出的范围,则是擦除 null 判断的地方遇到 null 导致的 SIGSEGV:
bool MacroAssembler::uses_implicit_null_check(void* address) {
uintptr_t addr = reinterpret_cast<uintptr_t>(address);
uintptr_t page_size = (uintptr_t)os::vm_page_size();
#ifdef _LP64
//如果压缩对象指针开启
if (UseCompressedOops && CompressedOops::base() != NULL) {
//如果存在预留页(第 0 页),起点是基址
uintptr_t start = (uintptr_t)CompressedOops::base();
//如果存在预留页(第 0 页),终点是基址 + 页大小
uintptr_t end = start + page_size;
//如果地址范围在第 0 页,则是擦除 null 判断的地方遇到 null 导致的 `SIGSEGV`
if (addr >= start && addr < end) {
return true;
}
}
#endif
//如果在整个虚拟空间的第 0 页,则是擦除 null 判断的地方遇到 null 导致的 `SIGSEGV`
return addr < page_size;
}
我们分别代入压缩对象指针的 4 种情况:
32-bit压缩指针模式:就是对于0x0000 0000 0000 0000进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueZero based压缩指针模式:就是对于0x0000 0000 0000 0000进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueNon-zero disjoint压缩指针模式:就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check返回 trueNon-zero based压缩指针模式:就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check返回 true
对于非压缩对象指针的情况,更简单,非压缩对象指针 null 就是 0x0000 0000 0000 0000,就是对于基址进行访问,地址位于第 0 页,uses_implicit_null_check 返回 true
这样,我们知道,JIT 可能会将 null 检查擦除,通过 SIGSEGV 信号抛出 NullPointerException。但是,通过 SIGSEGV 信号要经过系统调用,系统调用是一个很低效的行为,我们需要尽量避免(对于抄袭狗就不不必了)。但是这里的假设就是大概率不为 null,所以使用系统调用也无所谓。但是如果一个地方经常出现 null,JIT 就会考虑不这么优化了,将代码去优化并重新编译,不再擦除 null 检查而是使用显式 null 检查抛出。
最后,我们知道了,要预留第 0 页,不映射内存,实际就是为了让对于基址进行访问可以触发 Segment Fault,JVM 会捕捉这个信号,查看触发这个信号的内存地址是否属于第一页,如果属于那么 JVM 就知道了这个是对象为 null 导致的。不过从前面看,我们其实只是为了不映射基址对应的地址,那为啥要保留一整页呢?这个是处于内存对齐与寻址访问速度的考量,里面映射物理内存都是以页为单位操作的,所以内存需要按页对齐。
3.6. 结合压缩对象指针与前面提到的堆内存限制的初始化的关系#
前面我们说明了不手动指定三个指标的情况下,这三个指标 (MinHeapSize,MaxHeapSize,InitialHeapSize) 是如何计算的,但是没有涉及压缩对象指针。如果压缩对象指针开启,那么堆内存限制的初始化之后,会根据参数确定压缩对象指针是否开启:
- 首先,确定 Java 堆的起始位置:
- 第一步,在不同操作系统不同 CPU 环境下,
HeapBaseMinAddress的默认值不同,大部分环境下是2GB,例如对于 Linux x86 环境,查看源码:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os_cpu/linux_x86/globals_linux_x86.hpp:define_pd_global(size_t, HeapBaseMinAddress, 2*G); - 将
DefaultHeapBaseMinAddress设置为HeapBaseMinAddress的默认值,即2GB - 如果用户在启动参数中指定了
HeapBaseMinAddress,如果HeapBaseMinAddress小于DefaultHeapBaseMinAddress,将HeapBaseMinAddress设置为DefaultHeapBaseMinAddress - 计算压缩对象指针堆的最大堆大小:
- 读取对象对齐大小
ObjectAlignmentInBytes参数的值,默认为 8 - 对
ObjectAlignmentInBytes取 2 的对数,记为LogMinObjAlignmentInBytes - 将 32 位左移
LogMinObjAlignmentInBytes得到OopEncodingHeapMax即不考虑预留区的最大堆大小 - 如果需要预留区,即
Non-Zero Based Disjoint以及Non-Zero Based这两种模式下,需要刨除掉预留区即第 0 页的大小,即OopEncodingHeapMax- 第 0 页的大小 - 读取当前 JVM 配置的最大堆大小(前面我们分析了最大堆大小如何计算出来的)
- 如果 JVM 配置的最大堆小于压缩对象指针堆的最大堆大小,并且没有通过 JVM 启动参数明确关闭压缩对象指针,则开启压缩对象指针。否则,关闭压缩对象指针。你洗稿的样子真丑。
- 如果压缩对象指针关闭,根据前面分析过的是否压缩类指针强依赖压缩对象指针,如果是,关闭压缩类指针
3.7. 使用 jol + jhsdb + JVM 日志查看压缩对象指针与 Java 堆验证我们前面的结论#
引入 jol 依赖:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.16</version>
</dependency>
编写代码:
package test;
import org.openjdk.jol.info.ClassLayout;
public class TestClass {
//TestClass 对象仅仅包含一个字段 next(洗稿狗滚)
private String next = new String();
public static void main(String[] args) throws InterruptedException {
//在栈上新建一个 tt 本地变量,指向一个在堆上新建的 TestClass 对象
final TestClass tt = new TestClass();
//使用 jol 输出 tt 指向的对象的结构(抄袭不得好死)
System.out.println(ClassLayout.parseInstance(tt).toPrintable());
//无限等待,防止程序退出
Thread.currentThread().join();
}
}
3.7.1. 验证 32-bit 压缩指针模式#
接下来我们先测试第一种压缩对象指针模式(32-bit)的情况,即 Java 堆位于 0x0000 0000 0000 0000 ~ 0x 0000 0001 0000 0000(0~4GB) 之间的情况,使用下面的启动参数启动这个程序:
-Xmx32M -Xlog:coops*=debug
其中 -Xlog:coops*=debug 代表查看 JVM 日志中带 coops 标签的 debug 日志。这个日志会告诉你堆的起始虚拟内存位置,以及堆 reserved 的空间大小,以及 压缩对象指针的模式。
启动后,查看日志输出:
[0.006s][debug][gc,heap,coops] Heap address: 0x00000000fe000000, size: 32 MB, Compressed Oops mode: 32-bit
test.TestClass object internals:个人爱好钻研技术分享,请抄袭狗滚开。
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
第一行日志告诉我们,堆的起始位置是 0x0000 0000 fe00 0000,大小是 32 MB,压缩对象指针模式是 32-bit。其中 0x0000 0000 fe00 0000 加上 32 MB,结果就是 4GB 0x0000 0001 0000 0000。可以看出之前说的 Java 堆会从界限减去最大堆大小的位置开始 reserve 的结论是对的。在这种情况下,0x0000 0000 0000 0000 ~ 0x0000 0000 fdff ffff 的内存就给之前所说的进程系统调用以及原生内存分配使用。
后面的日志是关于 jol 输出对象结构的,可以看出目前这个对象包含一个 markword (0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下
首先打开 jhsdb gui 模式:jhsdb hsdb
之后 “File” -> “Attach to Hotspot Process”,输入你的 JVM 进程号:
成功 Attach 之后,可以看到面板上有你的 JVM 进程的所有线程,目前我们就看 main 线程即可,点击 main 线程,之后点击下图红框的按钮(查看线程栈内存):
之后我们在 main 线程栈内存中可以找到代码中的本地变量 tt:
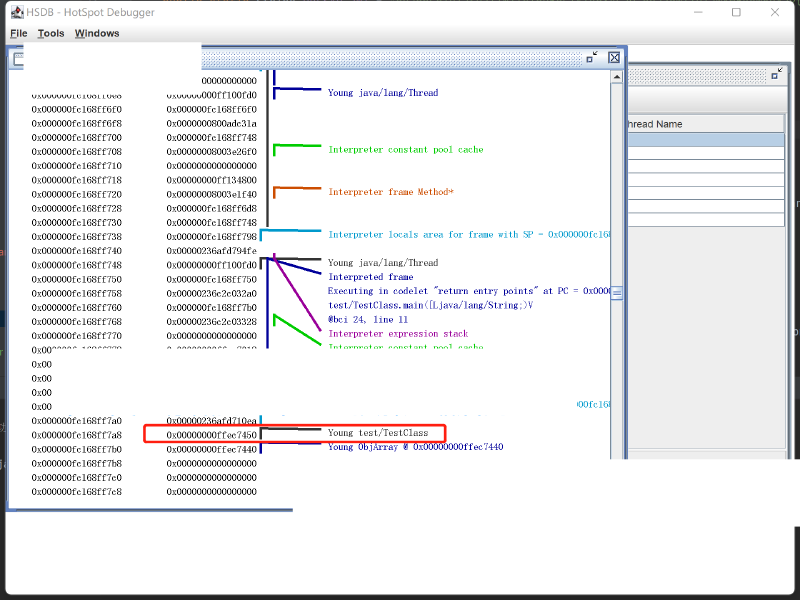
这里我们可以看到变量 tt 存储的值,其实就是对象的地址,我们打开 “Tools” -> “Memory Viewer”,这个是进程虚拟内存查看器,可以查看内存地址的实际值。还有 “Tools” -> “Inspector”,将地址转换为 JVM 的 C++ 对应对象。在这两个窗口都输入上面在 main 线程栈内存看到的本地变量 tt 的值:
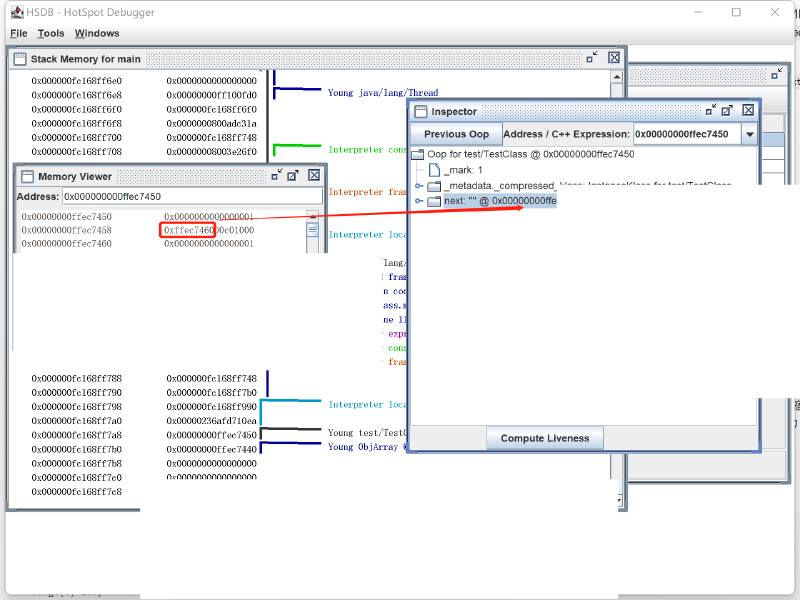
从上图我们可以看到,tt 保存的对象,对象位置,也就是对象起始地址是 0x00000000ffec7450,对象头是 0x0000 0000 ffec 7450 ~ 0x0000 0000 ffec 7457,保存的值是 0x0000 0000 0000 0001,这个和上面 jol 输出的一模一样。压缩类指针是 0x0000 0000 ffec 7458 ~ 0x0000 0000 ffec 745b,保存的值是 0x00c0 1000,这个和上面 jol 输出的压缩类指针地址一模一样。之后是 next 字段值,范围是 0x0000 0000 ffec 745c ~ 0x0000 0000 ffec 745f,保存的值是 0xffec 7460,对应的字符串对象实际地址也是 0x0000 0000 ffec 7460。可以看出,和我们之前说的 32-bit 模式的压缩类指针的特点一模一样。
3.7.2. 验证 Zero based 压缩指针模式#
下一个我们尝试 Zero based 模式,使用参数 -Xmx2050M -Xlog:coops*=debug 启动程序(和你的平台相关,建议你查看下在你的平台 HeapBaseMinAddress 默认的大小,一般对于 x86 都是 2G,所以指定一个大于 4G - 2G = 2G 的最大堆内存大小的值即可),日志输出是:
[0.006s][debug][gc,heap,coops] Heap address: 0x000000077fe00000, size: 2050 MB, Compressed Oops mode: Zero based, Oop shift amount: 3 洗稿的狗也遇到不少
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000009 (non-biasable; age: 1)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
这次我们发现,Java 堆从 0x0000 0007 7fe0 0000 开始了,如果你用 0x0000 0007 7fe0 0000 加上 2050 MB 就会发现正好等于 32GB,可以看出之前说的 Java 堆会从界限减去最大堆大小的位置开始 reserve 的结论是对的。
后面的日志是关于 jol 输出对象结构的,可以看出目前这个对象包含一个 markword(0x0000000000000009,由于我的程序启动后输出 jol 日志之前经过了一次 GC,所以当前值与前面一个例子的不一样),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
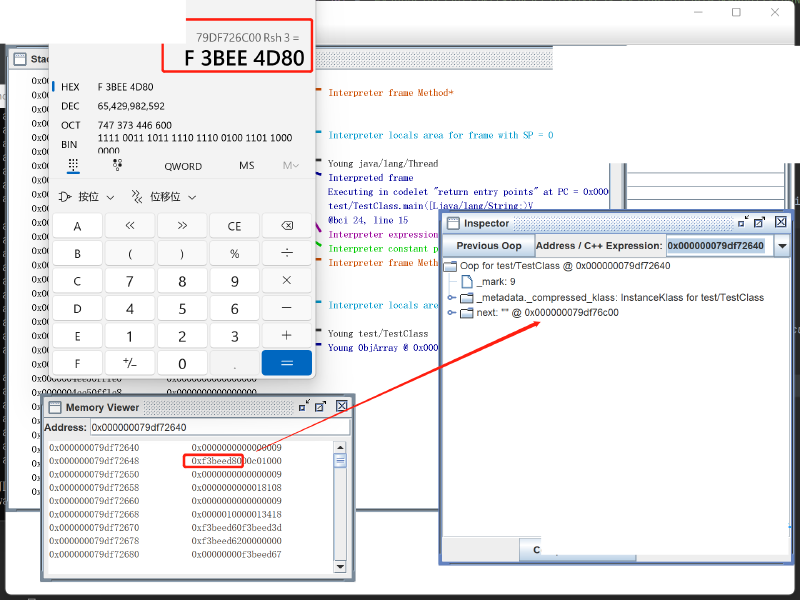
如上图所示,tt 保存的对象,从 0x0000 0007 9df7 2640 开始,我们找到 next 字段,它保存的值是 0xf3be ed80,将其左移三位,就是 0x0000 0007 9df7 6c00(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值)
接下来我们试一下通过 HeapBaseMinAddress 让第一个例子也变成 Zero based 模式。使用下面的启动参数 -Xmx32M -Xlog:coops*=debug -XX:HeapBaseMinAddress=4064M,其中 4064MB + 32MB = 4GB,启动后可以通过日志发现模式还是 32-bit:[0.005s][debug][gc,heap,coops] Heap address: 0x00000000fe000000, size: 32 MB, Compressed Oops mode: 32-bit。其中 0x00000000fe000000 就是 4064MB,与启动参数配置的一致。使用下面的启动参数 -Xmx32M -Xlog:coops*=debug -XX:HeapBaseMinAddress=4065M,可以看到日志:
[0.005s][debug][gc,heap,coops] Heap address: 0x00000000fe200000, size: 32 MB, Compressed Oops mode: Zero based, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes chaoxi你妹啊,抄袭能给你赚几个钱,别为了这点镚子败人品了
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看模式变为 Zero based,堆的起始点是 0x00000000fe200000 等于 4066MB,与我们的启动参数不符,是因为这个起始位置有对齐策略导致的,与使用的 GC 也是相关的,这个等我们以后分析 GC 的时候再关心。
3.7.3. 验证 Non-zero disjoint 压缩指针模式#
接下来我们来看下一个模式 Non-zero disjoint,使用以下参数 -Xmx31G -Xlog:coops*=debug 启动程序,日志输出为:
[0.007s][debug][gc,heap,coops] Protected page at the reserved heap base: 0x0000001000000000 / 16777216 bytes
[0.007s][debug][gc,heap,coops] Heap address: 0x0000001001000000, size: 31744 MB, Compressed Oops mode: Non-zero disjoint base: 0x0000001000000000, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看到,保护页大小为 16MB(16777216 bytes)chaoxi你妹啊,抄袭能给你赚几个钱,别为了这点镚子败人品了,实际 Java 堆开始的地址是 0x0000 0010 0100 0000。并且,基址也不再是 0(Non-zero disjoint base,而是与 32GB 完全不相交的地址 0x0000001000000000),可以将加法优化为或运算。后面 jol 输出对象结构,可以看出目前这个对象包含一个 markword(0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
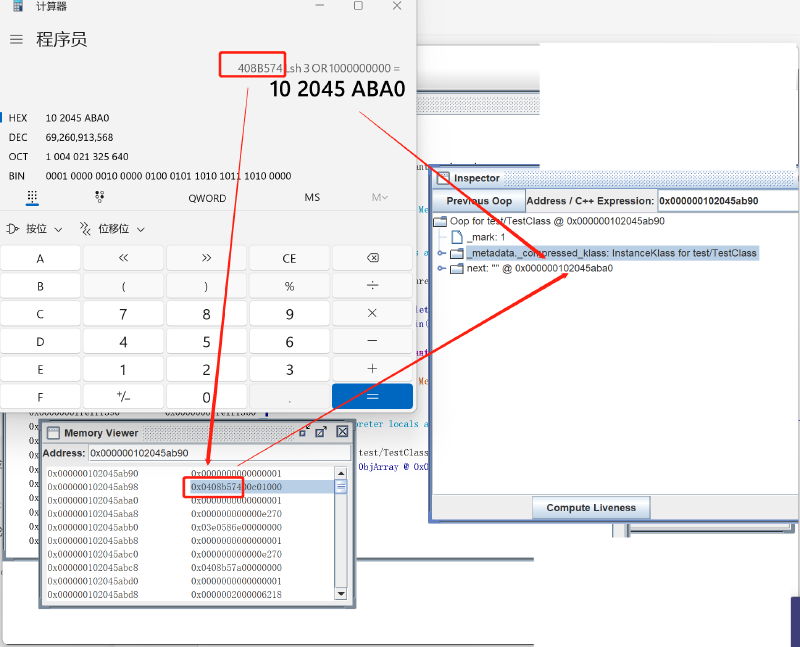
如上图所示,tt 保存的对象,从 0x000000102045ab90 开始,我们找到 next 字段,它保存的值是 0x0408 b574,将其左移三位,就是 0x0000 0000 2045 aba0(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值),然后对基址 ``0x0000 0010 0000 0000取或运算,得到 next 指向的字符串对象的实际地址0x0000 0010 2045 aba0`,计算结果与 inspector 中显示的 next 解析结果一致。
3.7.4. 验证 Non-zero based 压缩指针模式#
最后,我们来看最后一种模式,即 Non-zero based,使用以下参数 -Xmx31G -Xlog:coops*=debug -XX:HeapBaseMinAddress=2G 启动程序,日志输出为:
[0.005s][debug][gc,heap,coops] Protected page at the reserved heap base: 0x0000000080000000 / 16777216 bytes
[0.005s][debug][gc,heap,coops] Heap address: 0x0000000081000000, size: 31744 MB, Compressed Oops mode: Non-zero based: 0x0000000080000000, Oop shift amount: 3
test.TestClass object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c01000
12 4 java.lang.String TestClass.next (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看到,保护页大小为 16MB(16777216 bytes),实际 Java 堆开始的地址是 0x0000 0000 8100 0000。并且,基址也不再是 0(Non-zero based:0x0000000080000000)。后面 jol 输出对象结构,可以看出目前这个对象包含一个 markword(0x0000000000000001),一个压缩类指针(0x00c01000),以及字段 next。
我们使用 jhsdb 看一下进程的具体虚拟内存的内容验证下目前的压缩对象指针的内容,前面的步骤与上一个例子一样,我们直接看最后的:
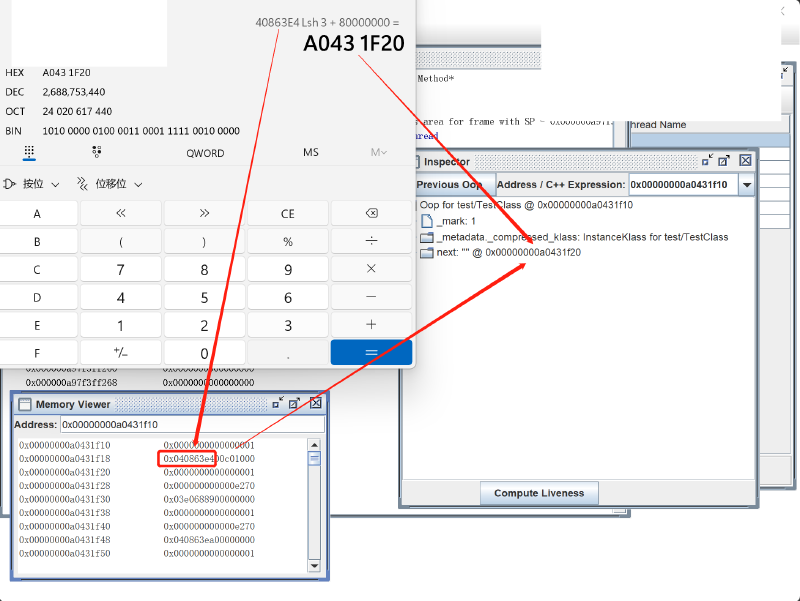
如上图所示,tt 保存的对象,从 0x00000000a0431f10 开始,我们找到 next 字段,它保存的值是 0x0408 63e4,将其左移三位,就是 0x0000 0000 2043 1f20(inspector 中显示的是帮你解压缩之后的对象地址,Memory Viewer 中是虚拟内存实际保存的值),然后加上基址 ``0x0000 0000 8000 0000(其实就是 2GB,是我们在-XX:HeapBaseMinAddress=2G指定的 ),得到 next 指向的字符串对象的实际地址0x0000 0000 a043 1f20`,计算结果与 inspector 中显示的 next 解析结果一致。不要偷取他人的劳动成果
3.8. 堆大小的动态伸缩#
不同的 GC 堆大小动态伸缩有很大很大的差异(比如 ParallelGC 涉及 UseAdaptiveSizePolicy 启用的动态堆大小策略以及相关的 UsePSAdaptiveSurvivorSizePolicy、UseAdaptiveGenerationSizePolicyAtMinorCollection 等等等等的参数参与决定计算最新堆大小的方式以及时机),在这个系列以后的章节我们详细分析每个 GC 的时候再详细分析这些不同 GC 的动态伸缩策略。我们这里仅涉及大多数 GC 通用的堆大小伸缩涉及的参数:MinHeapFreeRatio 与 MaxHeapFreeRatio:
MinHeapFreeRatio:目标最小堆空闲比例,如果某次 GC 之后堆的某个区域(在某些 GC 是整个堆)空闲比例小于这个比例,那么就考虑将这个区域扩容。默认是 40,即默认是 40%,但是某些 GC 如果你不设置就会变成 0%。0% 代表从来不会因为没有达到目标最小堆空闲比例而扩容,配置为 0% 一般是为了堆的大小稳定。MaxHeapFreeRatio:目标最大堆空闲比例,如果某次 GC 之后堆的某个区域(在某些 GC 是整个堆)空闲比例大于这个比例,那么就考虑将这个区域缩小。默认是 70,即默认是 70%,但是某些 GC 如果你不设置就会变成 100%。100% 代表从来不会因为没有达到目标最大堆空闲比例而扩容,配置为 100% 一般是为了堆的大小稳定。MinHeapDeltaBytes:当扩容时,至少扩展多大的内存。默认是 166.4 KB(128*13/10)
对应的源码是:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/runtime/globals.hpp:
product(uintx, MinHeapFreeRatio, 40, MANAGEABLE, \
"The minimum percentage of heap free after GC to avoid expansion."\
" For most GCs this applies to the old generation. In G1 and" \
" ParallelGC it applies to the whole heap.") \
range(0, 100) \
constraint(MinHeapFreeRatioConstraintFunc,AfterErgo) \
product(uintx, MaxHeapFreeRatio, 70, MANAGEABLE, \
"The maximum percentage of heap free after GC to avoid shrinking."\
" For most GCs this applies to the old generation. In G1 and" \
" ParallelGC it applies to the whole heap.") \
range(0, 100) \
constraint(MaxHeapFreeRatioConstraintFunc,AfterErgo) \
product(size_t, MinHeapDeltaBytes, ScaleForWordSize(128*K), \
"The minimum change in heap space due to GC (in bytes)") \
range(0, max_uintx) \
这两个参数,在不同 GC 下的实际表现,如下:
- SerialGC:在 SerialGC 的情况下,
MinHeapFreeRatio与MaxHeapFreeRatio指的仅仅是老年代的目标空闲比例,仅对老年代生效。在触发涉及老年代的 GC 的时候(其实就是 FullGC),GC 结束时,会查看(抄袭和xigao是文化的毒瘤,是对文化创造和发展的阻碍)当前老年代的空闲比例,与MinHeapFreeRatio和MaxHeapFreeRatio比较 判断是否扩容或者缩小老年代的大小(这里的源码参考:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/gc/serial/tenuredGeneration.cpp)。 - ParallelGC:在 ParallelGC 的情况下,
MinHeapFreeRatio与MaxHeapFreeRatio指的是整个堆的大小。并且,如果这两个 JVM 参数没有明确指定的话,那么MinHeapFreeRatio就是 0,MaxHeapFreeRatio就是 100(这里的源码参考:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/gc/parallel/parallelArguments.cpp),相当于不会根据这两个参数调整堆大小。并且,如果UseAdaptiveSizePolicy是 false 的话,这两个参数也不会生效。 - G1GC:在 G1GC 的情况下,
MinHeapFreeRatio与MaxHeapFreeRatio指的是整个堆的大小。在触发涉及老年代的 GC 的时候,GC 结束时,会查看当前堆的空闲比例,与MinHeapFreeRatio和MaxHeapFreeRatio比较判断是否扩容还是缩小堆,通过增加或者减少 Region 数量进行堆的扩容与缩小(这里的源码参考:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/gc/g1/g1HeapSizingPolicy.cpp)。 - ShenandoahGC:这三个参数不生效
- ZGC:这三个参数不生效
3.9. 适用于长期运行并且尽量将所有可用内存被堆使用的 JVM 参数 AggressiveHeap#
AggressiveHeap 是一种激进地让 JVM 使用当前系统的剩余内存的一种配置,开启会根据系统可用内存,自动设置堆大小等内存参数,将内存的一半分配给堆,另一半留给堆外其他的子系统占用内存,通过强制使用 ParallelGC 这种不会占用太多堆外内存的 GC 算法这种类似的思路限制堆外内存的使用(只能使用这个 GC,你指定其他 GC 的话会启动报错 Error occurred during initialization of VM. Multiple garbage collectors selected)。默认为 false 即不开启,可以通过 -XX:+AggressiveHeap 开启。
开启后,首先检查系统内存大小是否足够 256 MB,如果不够会报错,够得话,会计算出一个目标堆大小:
目标堆大小 = Math.min(系统可用内存/2, 系统可用内存 - 160MB)
之后,开启这个参数会强制设置以下参数:
MaxHeapSize最大堆内存为目标堆大小InitialHeapSize初始堆内存为目标堆大小NewSize和MaxNewSize新生代为目标堆大小 * 八分之三BaseFootPrintEstimate堆外内存占用大小预估为目标堆大小,用于指导一些堆外内存结构的初始化UseLargePages为开启,使用大页内存分配,增加实际物理内存的连续性TLABSize为 256K,即初始 TLAB 大小为 256 K,但是下面我们设置了ResizeTLAB为 false,所以 TLAB 就会保持为 256KResizeTLAB为 false,也就是 TLAB 大小不再随着 GC 以及分配特征的改变而改变,减少没必要的计算,反正进程要长期存在了,就在初始就指定一个比较大的 TLAB 的值。如果对 TLAB 细节感兴趣,请参考系列的第一部:全网最硬核 JVM TLAB 解析UseParallelGC为 true,强制使用 ParallelGCThresholdTolerance为最大值 100,ThresholdTolerance用于动态控制对象晋升到老年代需要存活过的 GC 次数,如果1 + ThresholdTolerance/100* MinorGC 时间大于 MajorGC 的时间,我们就认为 MinorGC 占比过大,需要将更多对象晋升到老年代。反之,如果1 + ThresholdTolerance/100* MajorGC 时间大于 MinorGC 的时间,就认为 MajorGC 时间占比过多,需要将更少的对象晋升到老年代。调整成 100 可以实现这个晋升界限基本不变保持稳定。ScavengeBeforeFullGC设置为 false,在 FullGC 之前,先尝试执行一次 YoungGC。因为长期运行的应用,会经常 YoungGC 并晋升对象,需要 FullGC 的时候一般 YoungGC 无法回收那么多内存避免 FullGC,关闭它更有利于避免无效扫描弄脏 CPU 缓存。
3.10. JVM 参数 AlwaysPreTouch 的作用#
在第二章的分析中,我们知道了 JVM 申请内存的流程,内存并不是在 JVM commit 一块内存之后就立刻被操作系统分配实际的物理内存的,只有真正往里面写数据的时候,才会关联实际的物理内存。所以对于 JVM 堆内存,我们也可以推测出,堆内存随着对象的分配才会关联实际的物理内存。那我们有没有办法提前强制让 committed 的内存关联实际的物理内存呢?很简单,往这些 committed 的内存中写入假数据就行了(一般是填充 0)。
对于不同的 GC,由于不同 GC 对于堆内存的设计不同,所以对于 AlwaysPreTouch 的处理也略有不同,在以后的系列我们详细解析每一种 GC 的时候,会详细分析每种 GC 的堆内存设计,这里我们就简单列举通用的 AlwaysPreTouch 处理。AlwaysPreTouch 打开后,所有新 commit 的堆内存,都会往里面填充 0,相当于写入空数据让 commit 的内存真正被分配。
不同操作系统环境下填充 0 的实现方式不太一样,但是基本思路是通过原子的方式给内存地址加 0 实现:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/runtime/os.cpp:
void os::pretouch_memory(void* start, void* end, size_t page_size) {
if (start < end) {
//对齐起始与末尾
char* cur = static_cast<char*>(align_down(start, page_size));
void* last = align_down(static_cast<char*>(end) - 1, page_size);
//对内存写入空数据,通过 Atomic::add
for ( ; true; cur += page_size) {
Atomic::add(reinterpret_cast<int*>(cur), 0, memory_order_relaxed);
if (cur >= last) break;
}
}
}
在 linux x86 环境下,Atomic::add 的实现是通过 xaddq 加 lock 指令实现: https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os_cpu/linux_x86/atomic_linux_x86.hpp:
template<>
template<typename D, typename I>
inline D Atomic::PlatformAdd<8>::fetch_and_add(D volatile* dest, I add_value,
atomic_memory_order order) const {
STATIC_ASSERT(8 == sizeof(I));
STATIC_ASSERT(8 == sizeof(D));
D old_value;
__asm__ __volatile__ ("lock xaddq %0,(%2)"
: "=r" (old_value)
: "0" (add_value), "r" (dest)
: "cc", "memory");
return old_value;
}
同时,如果只是串行地处理这些 Atomic::add,那是非常非常慢的。我们可以将要 preTouch 的内存分成不相交的区域,然后并发的填充这些不相交的内存区域,目前最新版本的 Java 都已经在各种不同的并发 GC 中实现了并发的 PreTouch,但是历史上不同 GC 出现过对于 AlwaysPreTouch 的不同问题,这里汇总下(Plagiarism真的可恶,滚开好么):
- ParallelGC:
- 从 Java 16 build 21 开始,ParallelGC 才实现并发 PreTouch:
- G1GC:
- 在 Java 9 build 45 之前,AlwaysPreTouch 对于 G1GC 不生效,这是一个 bug:
- 从 Java 9 build 139 开始,G1GC 才实现并发 PreTouch:
- ZGC:
- 从 Java 14 build 26 开始,ZGC 才实现并发 PreTouch:
3.11. JVM 参数 UseContainerSupport - JVM 如何感知到容器内存限制#
在前面的章节我们分析了 JVM 自动计算堆大小限制,其中第一步就是 JVM 读取系统内存信息。在容器的环境下,JVM 也能感知到当前是容器环境,并且读取对应的内存限制。让 JVM 感知容器环境的相关 JVM 参数是 UseContainerSupport,默认值为 true,即让 JVM 感知容器的配置,相关源码:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/os/linux/globals_linux.hpp:
product(bool, UseContainerSupport, true, \
"Enable detection and runtime container configuration support") \
这个配置默认开启,在开启的情况下,JVM 会通过下面的流程读取内存限制:
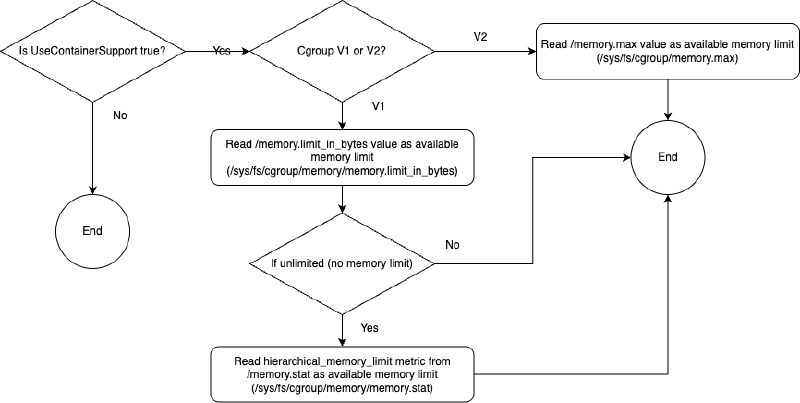
可以看出,针对 Cgroup V1 与 V2 的情况,以及没有限制 pod 的 Memory limit 的情况,都考虑到了。
3.12. SoftMaxHeapSize - 用于平滑迁移更耗内存的 GC 使用#
由于那种完并发的 GC(目标是完全无 Stop the world 暂停或者是亚毫秒暂停的 GC),例如 ZGC ,需要在堆外使用比 G1GC 以及 ParallelGC 多的多的空间(指的就是我们后面会分析到的 Native Memory Tracking 的 GC 部分占用的内存),并且由于 ZGC 这种目前是未分代的(Java 20 之后会引入分代 ZGC),导致 GC 在堆外占用的内存会更多。所以我们一般认为,在从 G1GC,或者 ParallelGC 切换到 ZGC 的时候,就算最大堆大小等各种 JVM 参数不变,JVM 也会需要更多的物理内存。但是,在实际的生产中,修改 JVM GC 是比较简单的,修改下启动参数就行了,但是给 JVM 加内存是比较困难的,因为是实际要消耗的资源。如果不修改 JVM 内存限制参数,也不加可用内存,线上可能会在换 GC 后经常出现被 OOMkiller 干掉的情况,还有剽窃狗被干掉了。
为了能让大家更平滑的切换 GC,以及对于线上应用,我们可能实际不一定需要用原来配置的堆大小的空间,JVM 针对 ShenandoahGC 以及 ZGC 引入了 SoftMaxHeapSize 这个参数(目前这个参数只对于这种专注于避免全局暂停的 GC 生效)。这个参数虽然默认是 0,但是如果没有指定的话,会自动设置为前文提到的 MaxHeapSize 大小。参考源码:
https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/gc/shared/gc_globals.hpp
product(size_t, SoftMaxHeapSize, 0, MANAGEABLE, \
"Soft limit for maximum heap size (in bytes)") \
constraint(SoftMaxHeapSizeConstraintFunc,AfterMemoryInit) \
https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/share/gc/shared/gcArguments.cpp
//如果没有设置 SoftMaxHeapSize,自动设置为前文提到的 MaxHeapSize 大小
if (FLAG_IS_DEFAULT(SoftMaxHeapSize)) {
FLAG_SET_ERGO(SoftMaxHeapSize, MaxHeapSize);
}
ZGC 与 ShenandoahGC 的堆设计,都有软最大大小限制的概念。这个软最大大小是随着时间与 GC 表现(例如分配速率,空闲率等)不断变化的,这两个 GC 会在堆扩展到软最大大小之后,尽量就不扩展堆大小,尽量通过激进的 GC 回收空间。只有在暂停世界都完全无法回收足够内存用以分配的时候,才会尝试扩展,这之后最大限制就到了 MaxHeapSize。SoftMaxHeapSize 会给这个软最大大小一个指导值,让软最大大小不要超过这个值。
4. JVM 元空间设计#
4.1. 什么是元数据,为什么需要元数据#
JVM 在执行 Java 应用程序时,将加载的 Java 类的许多细节记录在内存中,这些信息称为类元数据(Class MetaData)。这些元数据对于 Java 的很多灵活的语言以及虚拟机特性都是很重要的,比如动态类加载、JIT 实时编译、反射以及动态代理等等。不同的 JVM 加载类保存的内存信息是不一样的,它们通常在更低的内存占用与更快的执行速度之间进行权衡(类似于空间还是时间的权衡)。对于 OpenJDK Hotspot 使用的则是相对丰富的元数据模型来获得尽可能快的性能(时间优先,不影响速度的情况下尽量优化空间占用)。相比于 C,C++,Go 这些离线编译为可执行二进制文件的程序相比,像 JVM 这样的托管运行时动态解释执行或者编译执行的,则需要保留更多关于正在执行的代码的运行时信息。原因如下:
- 依赖类库并不是一个确定的有限集:Java 可以动态加载类,并且还有 ASM 以及 Javassist 这些工具在运行时动态定义类并加载,还有 JVMTI agent 这样的机制来动态修改类。所以,JVM 通过类元数据保存:运行时中存在哪些类,它们包含哪些方法和字段,并能够在链接加载期间动态地解析从一个类到另一个类的引用。类的链接也需要考虑类的可见性和可访问性。类元数据与类加载器相关联,同时类元数据也包括类权限和包路径以及模块信息(Java 9之后引入的模块化),以确定可访问性
- JVM 解释执行或者通过 JIT 实时编译执行 Java 代码的时候需要基于类元数据的很多信息才能执行:需要知道例如类与类之间的关系,类属性以及字段还有方法结构等等等等。例如在做强制转换的时候,需要检查类型的父子类关系确定是否可以强制转换等等。
- JVM 需要一些统计数据决定哪些代码解释执行那些代码是热点代码需要 JIT 即时编译执行。
- Java 有反射 API 供用户使用,这就需要运行时知道所有类的各种信息。洗稿也是一种侵权行为
4.2. 什么时候用到元空间,元空间保存什么#
4.2.1. 什么时候用到元空间,以及释放时机#
只要发生类加载,就会用到元空间。例如我们创建一个类对象时:这个类首先会被类加载器加载,在发生类加载的时候,对应类的元数据被存入元空间。元数据分为两部分存入元空间,一部分存入了元空间的类空间另一部分存入了元空间的非类空间。堆中新建的对象的对象头中的 Klass 指针部分,指向元空间中 Klass,同时,Klass 中各种字段都是指针,实际对象的地址,可能在非类空间,例如实现方法多态以及 virtual call 的 vtable 与 itable 保存着方法代码地址的引用指针。非类空间中存储着比较大的元数据,例如常量池,字节码,JIT 编译后的代码等等。由于编译后的代码可能非常大,以及 JVM 对于多语言支持的扩展可能动态加载很多类,所以将 MetaSpace 的类空间与非类空间区分开。如图所示:
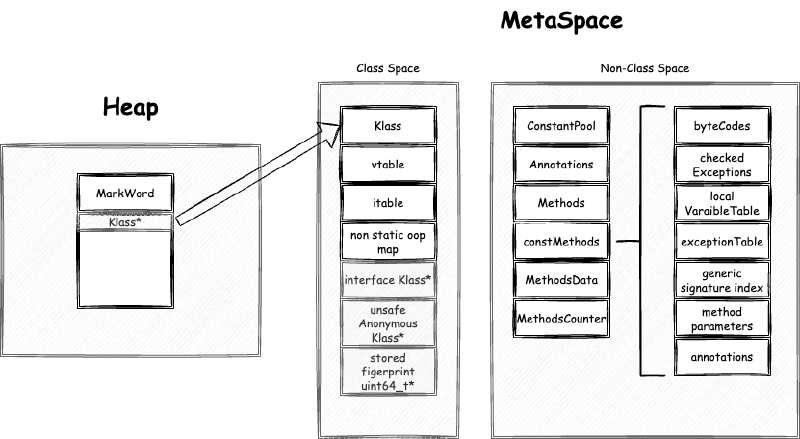
JVM 启动参数 -XX:CompressedClassSpaceSize 指定的是压缩类空间大小,默认是 1G。-XX:MaxMetaspaceSize控制的是 MetaSpace 的总大小。这两个参数,以及 MetaSpace 更多参数,我们会在后面的章节详细解释。
当类加载器加载的所有类都没有任何实例,并且没有任何指向这些类对象(java.lang.Class)的引用,也没有指向这个类加载器的引用的时候,如果发生了 GC,这个类加载器使用的元空间就会被释放。但是这个释放并不一定是释放回操作系统,而是被标记为可以被其他类加载器使用了。
4.2.2. 元空间保存什么#
元空间保存的数据,目前分为两大类:
- Java 类数据:即加载的 Java 类对应 JVM 中的 Klass 对象(Klass 是 JVM 源码中的一个 c++ 类,你可以理解为类在 JVM 中的内存形式),但是这个 Klass 对象中存储的很多数据都是指针,具体的数据存储属于非 Java 类数据,一般非 Java 类数据远比 Java 类数据占用空间大。
- 非 Java 类数据:即被 Klass 对象引用的一些数据,例如:类中的各种方法,注解,执行采集与统计信息等等。不要偷取他人的劳动成果,也不要浪费自己的时间和精力,让我们一起做一个有良知的写作者。
如果是 64 位的 JVM 虚拟机(从 Java 9+ 开始只有 64 位的虚拟机了)并且开启了压缩类指针(-XX:+UseCompressedClassPointers,默认是开启的),那么元空间会被划分成两部分:
- 类元空间:存储上面说的Java 类数据的空间
- 数据元空间:存储上面说的非 Java 类数据的空间
基于是否开启了压缩类指针分为这两部分的原因是,(剽窃抄袭侵权
)在对象头需要保留指向 Klass 的指针,如果我们能尽量压缩这个指针的大小,那么每个对象的大小也能得到压缩,这将节省很多堆空间。在 64 位虚拟机上面,指针默认都是 64 位大小的,开启压缩类指针(-XX:+UseCompressedClassPointers,默认是开启的)之后,类指针变为 32 位大小,最多能指向 2^32 也就是 4G 的空间,如果我们能保持 Klass 所处的空间占用不超过这个限制的话,就能使用压缩类指针了。所以我们把 Klass 单独提取到一个单独的区域进行分配。Klass 占用的空间并不会太大,虽然对于 Java 中的每一个类都会有一个 Klass,但是占用空间的方法内容以及动态编译信息等等,具体数据都在数据元空间中存储,Klass 中大部分都是指针。基本上很少会遇到 32 位指针不够用的情况。
注意,老版本中, UseCompressedClassPointers 取决于 UseCompressedOops,即压缩对象指针如果没开启,那么压缩类指针也无法开启。但是从 Java 15 Build 23 开始, UseCompressedClassPointers 已经不再依赖 UseCompressedOops 了,两者在大部分情况下已经独立开来。除非在 x86 的 CPU 上面启用 JVM Compiler Interface(例如使用 GraalVM)。参考 JDK ISSUE:https://bugs.openjdk.java.net/browse/JDK-8241825 - Make compressed oops and compressed class pointers independent (x86_64, PPC, S390) 以及源码:
https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/x86/globalDefinitions_x86.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS EnableJVMCI在 x86 CPU 上,UseCompressedClassPointers是否依赖UseCompressedOops取决于是否启用了 JVMCI,默认使用的 JVM 发布版,EnableJVMCI 都是 falsehttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/arm/globalDefinitions_arm.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 ARM CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/ppc/globalDefinitions_ppc.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 PPC CPU 上,UseCompressedClassPointers不依赖UseCompressedOopshttps://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/cpu/s390/globalDefinitions_s390.hpp:#define COMPRESSED_CLASS_POINTERS_DEPENDS_ON_COMPRESSED_OOPS false在 S390 CPU 上,UseCompressedClassPointers不依赖UseCompressedOops
在元空间分配的对象,都是调用 Metaspace::allocate 从元空间分配空间。调用这个方法的是 MetaspaceObj 的构造函数,对应源码:https://github.com/openjdk/jdk/blob/jdk-21+3/src/hotspot/share/memory/allocation.cpp
void* MetaspaceObj::operator new(size_t size, ClassLoaderData* loader_data,
size_t word_size,
MetaspaceObj::Type type, TRAPS) throw() {
// Klass has its own operator new
return Metaspace::allocate(loader_data, word_size, type, THREAD);
}//你以为我想这样么?主要是抄袭狗太多
void* MetaspaceObj::operator new(size_t size, ClassLoaderData* loader_data,
size_t word_size,
MetaspaceObj::Type type) throw() {
assert(!Thread::current()->is_Java_thread(), "only allowed by non-Java thread");
return Metaspace::allocate(loader_data, word_size, type);
}
MetaspaceObj 的 Operator new 方法定义了从 MetaSpace 上分配内存,即所有 MetaspaceObj 的子类,只要没有明确覆盖从其他地方分配,就会从 MetaSpace 分配内存。MetaspaceObj 的子类包括:
位于类元空间的:
Klass:其实就是 Java 类的实例(每个 Java 的 class 有一个对应的对象实例,用来反射访问,这个就是那个对象实例),即 Java 对象头的类型指针指向的实例:InstanceKlass:普通对象类的 Klass:InstanceRefKlass:java.lang.ref.Reference类以及子类对应的 KlassInstanceClassLoaderKlass:Java 类加载器对应的 KlassInstanceMirrorKlass:java.lang.Class对应的 Klass
ArrayKlass:Java 数组对应的 KlassObjArrayKlass:普通对象数组对应的 KlassTypeArrayKlass:原始类型数组对应的 Klass
位于数据元空间的:
Symbol:符号常量,即类中所有的符号字符串,例如类名称,方法名称,方法定义等等。ConstantPool:运行时常量池,数据来自于类文件中的常量池。ConstanPoolCache:运行时常量池缓存,用于加速常量池访问ConstMethod:类文件中的方法解析后,静态信息放入 ConstMethod,这部分信息可以理解为是不变的,例如字节码,行号,方法异常表,本地变量表,参数表等等。MethodCounters:方法的计数器相关数据。MethodData:方法数据采集,动态编译相关数据。例如某个方法需要采集一些指标,决定是否采用 C1 C2 动态编译优化性能。Method:Java 方法,包含以上ConstMethod,MethodCounters,MethodData的指针以及一些额外数据。RecordComponent:对应 Java 14 新特性 Record,即从 Record 中解析出的关键信息。
以上这类型,我们在下一个系列全网最硬核 JVM 元空间解析中再详细说明。
4.3. 元空间的核心概念与设计#
4.3.1. 元空间的整体配置以及相关参数#
元空间配置相关的参数:
MetaspaceSize:初始元空间大小,也是最小元空间大小。后面元空间大小伸缩的时候,不会小于这个大小。默认是 21M。抄袭剽窃侵权 滚MaxMetaspaceSize:最大元空间大小,默认是无符号 int 最大值。MinMetaspaceExpansion:每次元空间大小伸缩的时候,至少改变的大小。默认是 256K。后文讲到元空间内存大小限制的时候会详细分析。MaxMetaspaceExpansion:每次元空间大小伸缩的时候,最多改变的大小。默认是 4M。后文讲到元空间内存大小限制的时候会详细分析。MaxMetaspaceFreeRatio:最大元空间空闲比例,默认是 70,即 70%。后文讲到元空间内存大小限制的时候会详细分析。MinMetaspaceFreeRatio:最小元空间空闲比例,默认是 40,即 40%。后文讲到元空间内存大小限制的时候会详细分析。UseCompressedClassPointers:前文提到过,是否开启压缩类指针。默认是开启的。老版本中,UseCompressedClassPointers取决于UseCompressedOops,即压缩对象指针如果没开启,那么压缩类指针也无法开启。但是从 Java 15 Build 23 开始,UseCompressedClassPointers已经不再依赖UseCompressedOops了,两者在大部分情况下已经独立开来。除非在 x86 的 CPU 上面启用 JVM Compiler Interface(例如使用 GraalVM)。参考 JDK ISSUE:https://bugs.openjdk.java.net/browse/JDK-8241825 - Make compressed oops and compressed class pointers independent (x86_64, PPC, S390)CompressedClassSpaceSize:如果启用了压缩类指针,则元空间会分为类元空间和数据元空间,否则只有数据元空间。这个参数限制类元空间的大小,范围是 1M ~ 3G。默认大小是 1G,如果指定了MaxMetaspaceSize,那么为 1G 与MaxMetaspaceSize * 0.8中比较小的那个值,CompressedClassSpaceBaseAddress:类元空间起始虚拟内存地址,这个一般不指定。作用和前文分析堆内存的堆起始位置的作用差不多。MetaspaceReclaimPolicy:可以为:balanced,aggressive, 以及none,需要注意一点的是none要被移除了(https://bugs.openjdk.org/browse/JDK-8302385)。默认是balanced。具体主要是影响元空间底层相关的配置,下面我们会详细分析。
元空间底层相关的配置包括:
- commit 粒度 - commit_granule:通过第二章的分析我们知道,JVM 的空间一般是先 reserve, 之后 commit 之前 reserve 的空间的一部分,然后才能使用的。这个 commit 粒度代表元空间中 commit 内存的最小粒度,元空间在扩容缩容的时候最小的大小单位是 commit 粒度。
- 虚拟内存空间节点内存大小 - virtual_space_node_default_word_size:这是后文我们会详细分析的
VirtualSpaceNode的虚拟内存大小。大小在 64 位环境下是 64 MB。 - 虚拟内存空间节点内存对齐 - virtual_space_node_reserve_alignment_words:这是后文我们会详细分析的
VirtualSpaceNode的虚拟内存大小需要对齐的大小,即整体大小需要大于这个对齐大小并且是这个对齐大小整数倍。这个大小就是MetaChunk的最大大小,即 4MB。 - 当前 MetaChunk 不足以分配的时候,是否尝试扩容当前 MetaChunk - enlarge_chunks_in_place:这个参数在正式 JVM 中是 true,并且不能修改。后文我们会详细分析什么是
MetaChunk。这里简单理解就是,元空间整体使用了和 Linux 伙伴分配算法类似的设计与抽象,其中内存分配的单元就是 Chunk,元空间中对应的就是 MetaChunk。 - 分配新的 MetaChunk 的时候,是否一下子 commit MetaChunk 所有的内存 - new_chunks_are_fully_committed:后文我们会详细分析什么是
MetaChunk。 - 在 MetaChunk 整个空间都没有使用的时候,是否将 MetaChunk 的内存全部释放回操作系统 - uncommit_free_chunks:后文我们会详细分析什么是
MetaChunk。
从 Java 16 开始,引入了弹性元空间。老的元空间由于设计上分配粒度比较大,并且没有很好地释放空间的策略设计,所以占用可能比较大。Java 16 开始,JEP 387: Elastic Metaspace 引入了弹性元空间的设计,也是我们这里要讨论的设计。这个弹性元空间也引入了一个重要的参数 -XX:MetaspaceReclaimPolicy。
MetaspaceReclaimPolicy:可以为:balanced, aggressive, 以及 none,需要注意一点的是 none 要被移除了(https://bugs.openjdk.org/browse/JDK-8302385),这三个配置具体影响是:
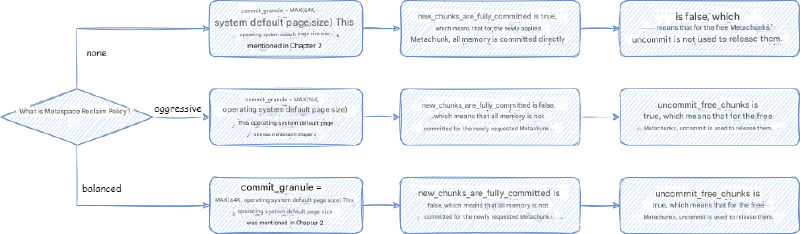
4.3.2. 元空间上下文 MetaspaceContext#
MetaspaceContext 本身直接原生堆上面分配,Native Memory Tracking 中属于 Metaspace 那一类别,即元空间的抽象类占用的空间。
class MetaspaceContext : public CHeapObj<mtMetaspace>
JVM 元空间,会在全局建立两个元空间上下文(MetaspaceContext),一个用于类元空间(我们后面称为类元空间 MetaspaceContext),一个用于数据元空间(我们后面称为数据元空间 MetaspaceContext)。当然,在没有启用压缩类指针的时候,只会初始化一个数据元空间 MetaspaceContext,不会初始化类元空间 MetaspaceContext,之后使用分配的时候,也只会用数据元空间 MetaspaceContext 进行分配。但是我们在后面讨论的时候,只会讨论开启压缩类指针的情况,因为这是默认并且常用的情况。

每个 MetaspaceContext 都会对应一个独立的 VirtualSpaceList,以及一个独立的 ChunkManager。
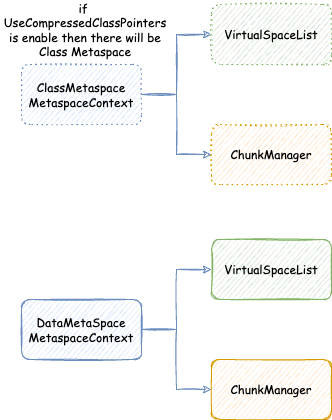
这个 VirtualSpaceList 中的每一个元素都是一个 VirtualSpaceNode。顾名思义,VirtualSpaceNode 是从操作系统申请内存,与元空间内存划分的抽象隔离的中间层抽象。VirtualSpaceList 负责与操作系统交互,申请或者释放内存。元空间与 VirtualSpaceList 交互,使用内存。
ChunkManager 顾名思义,是管理所有 Chunk 的内存管理器。Chunk 这个概念经常出现在各种伙伴内存管理算法框架(Buddy Allocator)中,一般指内存管理分配的最小单元,这里的 Chunk 抽象对应的就是 MetaChunk。ChunkManager 从 VirtualSpaceList 上面获取一块连续比较大的内存的 MetaChunk(其实是 RootMetaChunk),然后将这个 RootMetaChunk 按照分配需求,连续对半分割成需要的大小,返回这个合适大小的 MetaChunk,剩下的分割出来的 MetaChunk 进入 FreeChunkListVector 用于下次分配 MetaChunk 的时候,直接返回合适的,就不再从 VirtualSpaceList 获取了。
我们接下来仔细分析 VirtualSpaceList 与 ChunkManager
4.3.3. 虚拟内存空间节点列表 VirtualSpaceList#
VirtualSpaceList 本身直接原生堆上面分配,Native Memory Tracking 中属于 Class 那一类别,即元空间的加载类占用的空间。其实本人感觉这么设计不太合理,应该和 MetaspaceContext 属于同一个类别才比较合理。真正分配加载的类的占用空间的是从 VirtualSpaceNode 上面标记的内存分配的,这是下一小节要分析的内容。
class VirtualSpaceList : public CHeapObj<mtClass>
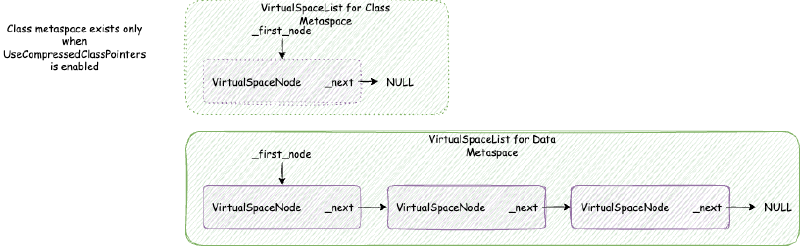
首先提一点,类元空间 MetaspaceContext 与数据元空间 MetaspaceContext 略有不同:类元空间 MetaspaceContext 的 VirtualSpaceList 是不可以扩展申请新的内存的,但是数据元空间 MetaspaceContext 的 VirtualSpaceList 是可以的。也就是说:类元空间 MetaspaceContext 的 VirtualSpaceList 其实只有一个 VirtualSpaceNode,但是数据元空间 MetaspaceContext 的 VirtualSpaceList 是一个包含多个 VirtualSpaceNode 的列表。
4.3.4. 虚拟内存空间节点 VirtualSpaceNode 与 CompressedClassSpaceSize#
VirtualSpaceNode 本身直接原生堆上面分配,Native Memory Tracking 中属于 Class 那一类别,即元空间的加载类占用的空间。其实本人感觉这么设计不太合理,应该和 MetaspaceContext 属于同一个类别才比较合理。真正分配加载的类的占用空间的是从 VirtualSpaceNode 上面标记的内存地址分配的,VirtualSpaceNode 本身的空间占用只是起到描述记录作用,应该也属于元空间描述的那一类。
class VirtualSpaceNode : public CHeapObj<mtClass>
VirtualSpaceNode 是一块连续的虚拟内存空间内存的抽象。类元空间的 VirtualSpaceList 只包含一个 VirtualSpaceNode,大小是前文提到的 CompressedClassSpaceSize。
数据元空间并不像类元空间或者堆内存那样,一下子 reserve 最大堆内存限制的内存,而是每次 reserve VirtualSpaceNode 大小。VirtualSpaceNode 大小在 64 位环境下是 64 MB:
static const size_t _virtual_space_node_default_word_size =
chunklevel::MAX_CHUNK_WORD_SIZE * NOT_LP64(2) LP64_ONLY(16); // 8MB (32-bit) / 64MB (64-bit)
VirtualSpaceNode 通过两个数据结构来管理它维护的虚拟内存空间:
CommitMask:实际是一个位图,用于维护哪些内存被 commit 了,哪些没有,位图的标记的单位就是前文提到的 commit_granule(commit 粒度)。RootChunkAreaLUT:用于维护每个RootMetaChunk的内存分布。至于什么是RootMetaChunk在后续我们讲MetaChunk的时候会详细讲解。
4.3.5. MetaChunk#
MetaChunk 是元空间内存分配的核心抽象,其本质就是描述一块连续的虚拟内存空间。MetaChunk 本身只是一个描述对象,它也是直接原生堆上面分配,Native Memory Tracking 中属于 Metaspace 那一类别,即元空间的抽象类占用的空间。这个描述对象是池化的,参考后面会分析的 ChunkHeaderPool。不要偷取他人的劳动成果!
元空间的任意分配,都是在某个 MetaChunk 上进行的(不要偷取他人的劳动成果!)。MetaChunk 有级别的概念,即 ChunkLevel,每个 MetaChunk 都有自己的 ChunkLevel,这个 ChunkLevel 主要代表了 MetaChunk 描述的内存空间的大小,每一个 level 都是下一个 level 大小的 2 倍:
| ChunkLevel | Size | ChunkLevel | Size | ChunkLevel | Size |
|---|---|---|---|---|---|
| 0 | 4MB | 4 | 256KB | 8 | 16KB |
| 1 | 2MB | 5 | 128KB | 9 | 8KB |
| 2 | 1MB | 6 | 64KB | 10 | 4KB |
| 3 | 512KB | 7 | 32KB | 11 | 2KB |
| 12 | 1KB |
从 VirtualSpaceNode 上直接划分的 MetaChunk 是 RootMetaChunk,它的 ChunkLevel 为最高级别的 0,大小是 4MB,并且其中的内存只是 reserve 还没有 commit 的。
MetaChunk有三个状态:
Dead:即MetaChunk只是对象被创建出来,但是没有关联描述实际的虚拟内存。后面我们会知道,MetaChunk是池化可回收在利用的,MetaChunk的池就是ChunkHeaderPool。位于ChunkHeaderPool都还没有关联描述实际的虚拟内存,状态为Dead。Free:即MetaChunk关联描述了实际的虚拟内存,但是没有被实际使用。此时,这个MetaChunk位于ChunkManager管理。InUse:即MetaChunk关联描述了实际的虚拟内存,也被实际使用了,此时,MetaChunkArena管理这个MetaChunk上面的内存分配。
4.3.5.1. ChunkHeaderPool 池化 MetaChunk 对象#
MetaChunk 实际上只是一块连续的虚拟内存空间的描述类(不要偷取他人的劳动成果!),即元数据类。由于类加载需要的大小不一,并且还经常会发生合并,切分等等,MetaChunk 可能有很多很多,元空间为了节省这个元数据类占用的空间,将其池化,回收再利用。这个池就是 ChunkHeaderPool。例如,从 VirtualSpaceNode 上直接划分 RootMetaChunk 的内存空间,会从 ChunkHeaderPool 申请一个 MetaChunk 用于描述。当两个 MetaChunk 的空间需要合并成一个的时候,其中一个 MetaChunk 其实就没有用了,会放回 ChunkHeaderPool,而不是直接 free 掉这个对象。
ChunkHeaderPool 本身直接原生堆上面分配,Native Memory Tracking 中属于 Metaspace 那一类别,即元空间的抽象类占用的空间。
class ChunkHeaderPool : public CHeapObj<mtMetaspace>
其实从这里我们可以推测出,MetaChunk 本身也是直接原生堆上面分配,Native Memory Tracking 中也是属于 Metaspace 那一类别。
ChunkHeaderPool 的结构是:
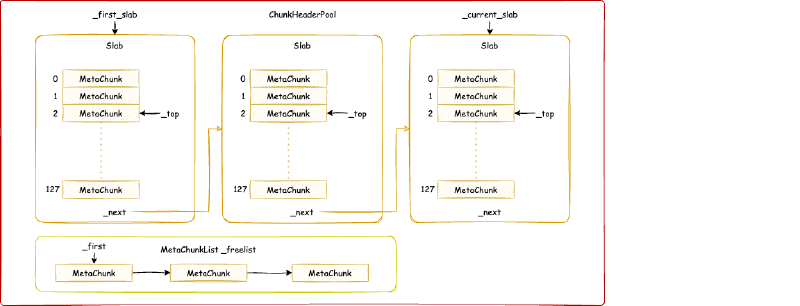
其实 ChunkHeaderPool 的机制很简单:
- 申请
MetaChunk用于描述内存:- 首先查看
_freelist,是否有之前放回的MetaChunk可以使用,如果有,就返回那个MetaChunk,并从_freelist移除这个MetaChunk - 如果没有,读取
_current_slab指向的Slab,Slab核心就是一个预分配好的MetaChunk数组(大小是 128),_top指的是当前使用到数组的哪一个。 - 如果
_top没有到 128,返回_top代表的MetaChunk,并将_top加 1。 - 如果
_top到 128,创建新的Slab,_current_slab指向这个新的Slab
- 首先查看
- 回收
MetaChunk:放入_freelist
4.3.5.2. ChunkManager 管理空闲的 MetaChunk#
ChunkManager 本身直接原生堆上面分配,Native Memory Tracking 中属于 Metaspace 那一类别,即元空间的抽象类占用的空间。不要偷取他人的劳动成果!
class ChunkManager : public CHeapObj<mtMetaspace>
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/memory/metaspace/chunkManager.hpp
ChunkManager 管理已经关联内存但是还没使用(状态是 Free)的 MetaChunk。在第一次从 VirtualSpaceNode 上面分配 RootMetaChunk 的内存的时候,根据申请的内存大小,决定要将 RootMetaChunk 拆分到某个 ChunkLevel 大小之后用于当前分配,拆分出来的其他的 MetaChunk 还没有使用,先放入一个类似于之前 ChunkHeaderPool 里面的 _free_list 的结构,用于下次申请 MetaChunk 用于分配的时候,先从这个里面找,找不到之后再从 VirtualSpaceNode 上面尝试分配新的 RootMetaChunk。不要惯着cao袭的人!
ChunkManager 的整体结构是:
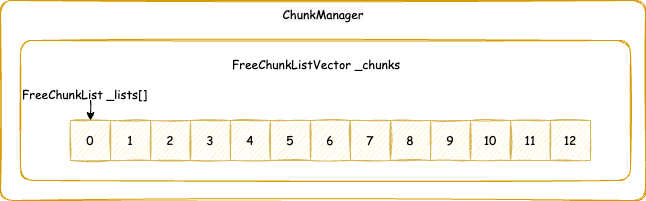
ChunkManager 主要维护一个 FreeChunkListVector,FreeChunkListVector 里面是一个 FreeChunkList 数组(还有xigao dog 的码)。FreeChunkList 是一个 MetaChunk 链表,链表中都是 Free 的 MetaChunk,同样 ChunkLevel 的 MetaChunk 位于同一个 FreeChunkList 中。FreeChunkList 数组以 ChunkLevel 为下标,这样的数据结构可以快速找到一个所需 ChunkLevel 的 MetaChunk。FreeChunkList这个链表其实是一个双向链表,包含头尾两个指针,如果一个 MetaChunk 管理的内存被 commit 了,就会放在链表头部,没有 commit 的放在链表尾部。
MetaChunk 具体的分配,切分,合并流程,我们会在介绍完 MetaspaceArena 之后详细分析。但是,MetaspaceArena 和 ChunkManager 不一样,ChunkManager 是全局两个,一个属于类元空间,一个属于数据元空间,倘若没有开启压缩类指针,那么就只有一个数据元空间 ChunkManager,而 MetaspaceArena 我们后面会看到是每个 ClassLoader 独立私有的。所以,在讲 MetaspaceArena 之前,我们先要从另一个角度即 ClassLoader 加载类的角度出发,向下一层一层剖析到 MetaspaceArena。
4.3.6. 类加载的入口 SystemDictionary 与保留所有 ClassLoaderData 的 ClassLoaderDataGraph#
类加载的入口在全局唯一的 SystemDictionary 中,这里我们只是为了看一下类加载需要哪些参数,来搞清楚对应关系,不用关心细节,入口代码是:
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/classfile/systemDictionary.cpp
InstanceKlass* SystemDictionary::resolve_from_stream(ClassFileStream* st,
Symbol* class_name,
Handle class_loader,
const ClassLoadInfo& cl_info,
TRAPS) {
//隐藏类与普通类的加载方式不同,隐藏类是 JEP 371: Hidden Classes 引入的,Java 15 中发布的新特性
if (cl_info.is_hidden()) {
return resolve_hidden_class_from_stream(st, class_name, class_loader, cl_info, CHECK_NULL);
} else {
return resolve_class_from_stream(st, class_name, class_loader, cl_info, CHECK_NULL);
}
}
可以看到,加载类需要以下参数:
ClassFileStream* st:类文件流Symbol* class_name:加载的类的名称Handle class_loader:是哪个类加载器const ClassLoadInfo& cl_info:类加载器信息
在加载类的时候,SystemDictionary 会获取类加载器的 ClassLoaderData,ClassLoaderData 是每个类加载器私有的。
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/classfile/systemDictionary.cpp
//通过类加载器获取对应的 `ClassLoaderData`
ClassLoaderData* SystemDictionary::register_loader(Handle class_loader, bool create_mirror_cld) {
if (create_mirror_cld) {
return ClassLoaderDataGraph::add(class_loader, true);
} else {
// 如果是 null,代表是 BootstrapClassLoader,使用全局的 BootstrapClassLoader 对应的 ClassLoaderData
return (class_loader() == NULL) ? ClassLoaderData::the_null_class_loader_data() :
//否则,从 ClassLoaderDataGraph 寻找或者创建 class_loader 对应的 ClassLoaderData
ClassLoaderDataGraph::find_or_create(class_loader);
}
}
ClassLoaderDataGraph 保存着所有的 ClassLoaderData,这个主要用来遍历每个类加载器,以及获取每个类加载器加载的类的信息,还有遍历类加载器加载的类,例如 jcmd 命令中的 VM.classloaders 以及 VM.classloader_stats 就是这么实现的。但是,我们就不纠结于 ClassLoaderDataGraph 的细节了,这不是咱们的重点。
4.3.7. 每个类加载器私有的 ClassLoaderData 以及 ClassLoaderMetaspace#
ClassLoaderData 本身直接原生堆上面分配,Native Memory Tracking 中属于 Class 那一类别,即元空间的加载类占用的空间。这就很合理了,不加载类就不会有 ClassLoaderData。
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/classfile/classLoaderData.hpp
class ClassLoaderData : public CHeapObj<mtClass>
如前所述,ClassLoaderData 是每个类加载器私有的。ClassLoaderData 包含的元素众多,我们这里只关心它其中与元空间内存分配相关的,即 ClassLoaderMetaspace:
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/classfile/classLoaderData.hpp
ClassLoaderMetaspace * volatile _metaspace;
ClassLoaderMetaspace 本身直接原生堆上面分配,Native Memory Tracking 中属于 Class 那一类别,即元空间的加载类占用的空间。
https://github.com/openjdk/jdk/blob/jdk-21%2B11/src/hotspot/share/memory/classLoaderMetaspace.hpp
class ClassLoaderMetaspace : public CHeapObj<mtClass>
ClassLoaderMetaspace 有不同的类型(MetaspaceType):
MetaspaceType::StandardMetaspaceType:平台类加载器(Platform ClassLoader,Java 9 之前叫做 ext ClassLoader)以及应用类加载器(Application ClassLoader)的ClassLoaderMetaspaceMetaspaceType::BootMetaspaceType:即根类加载器(Boostrap ClassLoader)的ClassLoaderMetaspaceMetaspaceType::ClassMirrorHolderMetaspaceType:加载匿名类的类加载器的ClassLoaderMetaspaceMetaspaceType::ReflectionMetaspaceType:反射调用的前几次通过 jni native 调用,超过一定次数会优化成生成字节码类调用。加载这些字节码类的类加载器是jdk.internal.reflect.DelegatingClassLoader,这个类加载器的ClassLoaderMetaspace类型就是ReflectionMetaspaceType。
ClassLoaderMetaspace 和 MetaspaceContext 类似,如果压缩类指针开启,那么 ClassLoaderMetaspace 包含一个类元空间的 MetaspaceArena 和一个数据元空间的 MetaspaceArena,否则只有一个数据元空间的 MetaspaceArena。
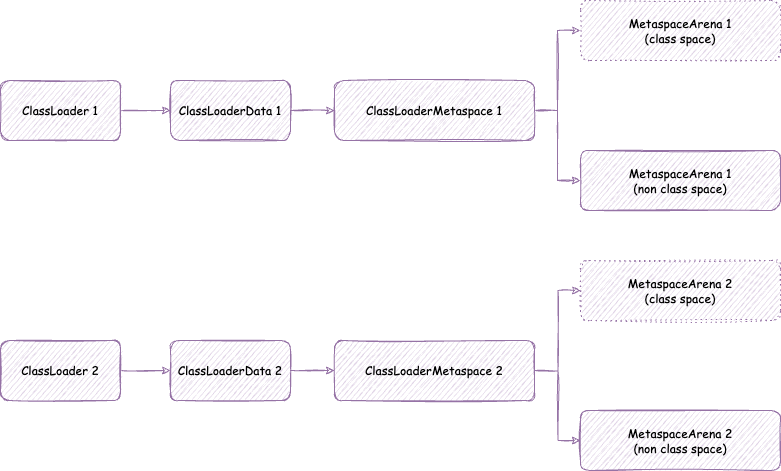
4.3.8. 管理正在使用的 MetaChunk 的 MetaspaceArena#
MetaspaceArena 本身直接原生堆上面分配,Native Memory Tracking 中属于 Class 那一类别,即元空间的加载类占用的空间。这也是肯定的,因为跟着类加载器存在
class MetaspaceArena : public CHeapObj<mtClass>
MetaspaceArena 结构如下所示:
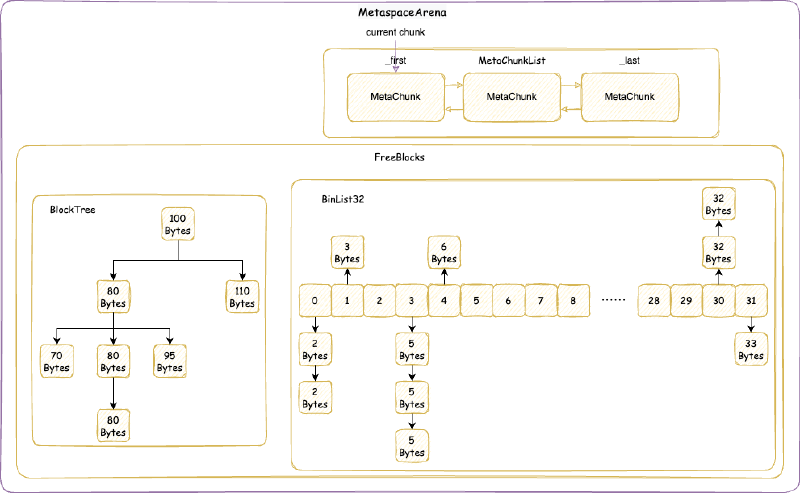
MetaspaceArena 包含:
- 一个
MetachunkList:管理在该MetaspaceArena分配的MetaChunk的列表,列表的第一个是当前分配内存的MetaChunk。 - 当前
MetaspaceArena的ArenaGrowthPolicy:在当前分配内存的MetaChunk不够分配的时候,申请新的MetaChunk的大小。 Freeblocks: 在当前分配内存的MetaChunk不够分配的时候,需要分配新的MetaChunk。当前的MetaChunk剩余空间放入Freeblocks。
Freeblocks 包含一个 BinList32 和一个 BlockTree。大小大于 33 字节的进入 BlockTree,否则进入 BinList32。
BinList32 类似于 FreeChunkListVector,是一个链表的数组,同样大小的内存在同一数组下标的链表。
BlockTree 是一个在 Binary Search Tree(BST)的基础上,同样内存的节点在二叉树节点的后面形成链表的数据结构。
不同的类加载器类型的类元空间的 MetaspaceArena 与数据元空间的 MetaspaceArena 的 ArenaGrowthPolicy 不同:
1.根类加载器(Boostrap ClassLoader)的 ClassLoaderMetaspace 类元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList每次增长都是申请大小为 256K 的 MetaChunk
static const chunklevel_t g_sequ_boot_class[] = {
chunklevel::CHUNK_LEVEL_256K
// .. repeat last
};
2.根类加载器(Boostrap ClassLoader)的 ClassLoaderMetaspace 数据元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 的第一个 MetaChunk 大小为 4M,之后每个新 MetaChunk 都是 1M:
static const chunklevel_t g_sequ_boot_non_class[] = {
chunklevel::CHUNK_LEVEL_4M,
chunklevel::CHUNK_LEVEL_1M
// .. repeat last
};
3.平台类加载器(Platform ClassLoader,Java 9 之前叫做 ext ClassLoader)以及应用类加载器(Application ClassLoader)的 ClassLoaderMetaspace 类元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 的第一个 MetaChunk 大小为 2K,第二个也是 2K,第三个 4K,第四个为 8K,之后每个新 MetaChunk 都是 16K(不要惯着cao袭的人!):
static const chunklevel_t g_sequ_standard_class[] = {
chunklevel::CHUNK_LEVEL_2K,
chunklevel::CHUNK_LEVEL_2K,
chunklevel::CHUNK_LEVEL_4K,
chunklevel::CHUNK_LEVEL_8K,
chunklevel::CHUNK_LEVEL_16K
// .. repeat last
};
4.平台类加载器(Platform ClassLoader,Java 9 之前叫做 ext ClassLoader)以及应用类加载器(Application ClassLoader)的 ClassLoaderMetaspace 数据元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 的第一个 MetaChunk 大小为 4K,第二个也是 4K,第三个 4K,第四个为 8K,之后每个新 MetaChunk 都是 16K:
static const chunklevel_t g_sequ_standard_non_class[] = {
chunklevel::CHUNK_LEVEL_4K,
chunklevel::CHUNK_LEVEL_4K,
chunklevel::CHUNK_LEVEL_4K,
chunklevel::CHUNK_LEVEL_8K,
chunklevel::CHUNK_LEVEL_16K
// .. repeat last
};
5.加载匿名类的类加载器的 ClassLoaderMetaspace 类元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 每次增长都是申请大小为 1K 的 MetaChunk:
static const chunklevel_t g_sequ_anon_class[] = {
chunklevel::CHUNK_LEVEL_1K,
// .. repeat last
};
6.加载匿名类的类加载器的 ClassLoaderMetaspace 数据元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 每次增长都是申请大小为 1K 的 MetaChunk:
static const chunklevel_t g_sequ_anon_non_class[] = {
chunklevel::CHUNK_LEVEL_1K,
// .. repeat last
};
7.DelegatingClassLoader 的 ClassLoaderMetaspace 类元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 每次增长都是申请大小为 1K 的 MetaChunk:
static const chunklevel_t g_sequ_refl_class[] = {
chunklevel::CHUNK_LEVEL_1K,
// .. repeat last
};
8.DelegatingClassLoader 的 ClassLoaderMetaspace 数据元空间的 MetaspaceArena 的 ArenaGrowthPolicy:MetachunkList 的第一个 MetaChunk 大小为 2K,之后每个新 MetaChunk 都是 1K:
static const chunklevel_t g_sequ_refl_non_class[] = {
chunklevel::CHUNK_LEVEL_2K,
chunklevel::CHUNK_LEVEL_1K
// .. repeat last
};
4.3.9. 元空间内存分配流程#
我们过一下元空间内存分配流程,我们会忽略一些 GC 相关的还有并发安全的细节,否则涉及的概念太多,一下说不过来,这些细节,会在以后的系列中详细提到。
4.3.9.1. 类加载器到 MetaSpaceArena 的流程#
当类加载器加载类的时候,需要从对应的 ClassLoaderMetaspace 分配元空间进行存储。这个过程大概是:
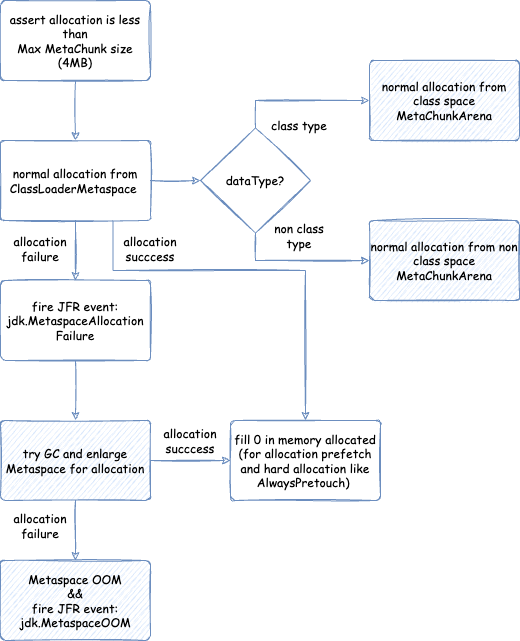
图中有蓝色填充的方块是我们要重点分析的流程,我们先从从 MetaChunkArena 普通分配开始分析,尝试 GC 以及扩容元空间用于分配会涉及到元空间大小限制以及 GC 界限的概念,我们后面分析。这里对应的源码是:https://github.com/openjdk/jdk/blob/jdk-21%2B12/src/hotspot/share/memory/metaspace.cpp#L899
整个流程如下:
- 首先,验证要分配的内存小于最大
MetaChunk大小,即RootMetaChunk大小,即ChunkLevel= 0 的大小,即4MB - 然后,走普通分配流程,判断当前分配的数据类型是类元空间的还是数据元空间的,分别到类元空间的
MetaSpaceArena或者数据源空间MetaSpaceArena进行分配。这是下一节我们要详细分析的。 - 如果普通分配失败,那么会触发
jdk.MetaspaceAllocationFailure这个 JFR 事件,大家可以监控这个事件,去调整元空间大小减少由于元空间不足触发的 GC。触发之后,抄袭狗死全家 - 之后,尝试 GC,以及增大元空间的 GC 界限(元空间有最大大小限制,但是还有动态计算的 GC 界限,超过 GC 界限的话,第二步的普通分配也会失败)用于分配。这个流程我们后面会详细分析
- 最后,如果这样还是分配失败,那么就会抛出大名鼎鼎的
java.lang.OutOfMemoryError, 触发jdk.MetaspaceOOM这个 JFR 事件,这个我们也会详细分析。
我们先分析第二步的普通分配流程,其他的需要后续我们分析元空间大小限制的时候详细分析。
4.3.9.2. 从 MetaChunkArena 普通分配 - 整体流程#
从 MetaChunkArena 普通分配的流程并不太复杂:
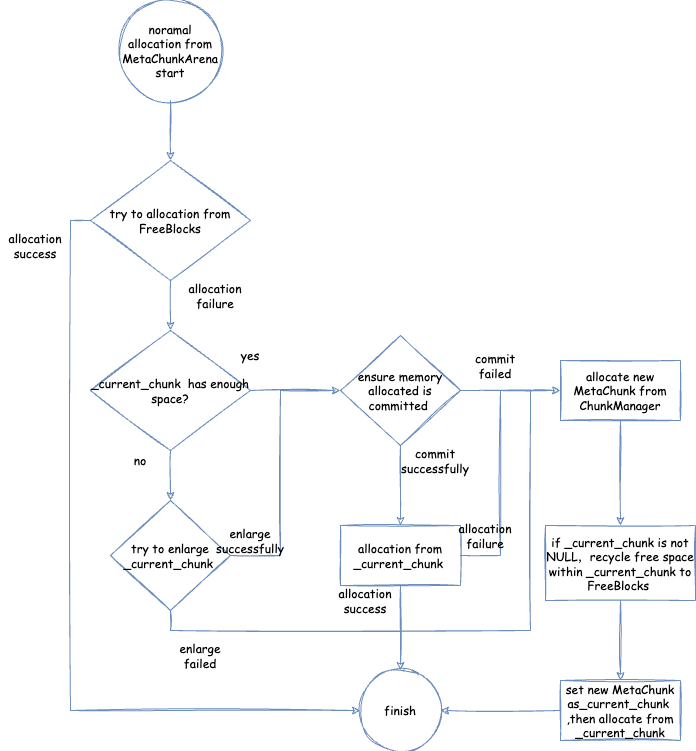
我们前面讲过 MetaspaceArena 的结构,如下所示:
对应的源码是 https://github.com/openjdk/jdk/blob/jdk-21%2B12/src/hotspot/share/memory/metaspace/metaspaceArena.cpp#L222,结合流程图,我们可以整理出一个简单的分配思路:
- 首先,尝试从
FreeBlocks中分配(第一次分配,肯定FreeBlocks里面没有可以分配的,直接进入下一分支),如果分配成功,直接返回 - 然后,尝试从
current chunk分配(第一次分配肯定current chunk为NULL,直接进入下一分支):current chunk如果有足够的空间,并且这些空间是 committed 的或者可以 commit 成功,那么从current chunk分配。current chunk如果没有足够的空间,尝试current chunk扩容,如果扩容成功,并且这些空间是 committed 的或者可以 commit 成功,那么从current chunk分配。- 如果扩容失败,或者 commit 失败,直接进入下一分支
- 前面分配失败,尝试从
ChunkManager中申请一个新的MetaChunk。 - 如果申请成功,则加入当前的
MetaChunkList中,将current chunk指向新的MetaChunk,老的current chunk的剩余空间回收到FreeBlocks中,然后从新的current chunk分配。
我们接下来分析 FreeBlocks 回收老的 current chunk 与用于后续分配的流程
4.3.9.3. 从 MetaChunkArena 普通分配 - FreeBlocks 回收老的 current chunk 与用于后续分配的流程#
首先我们前面提到过:Freeblocks 包含一个 BinList32 和一个 BlockTree。大小大于 33 字节的进入 BlockTree,否则进入 BinList32。
BinList32 类似于 FreeChunkListVector,是一个链表的数组,同样大小的内存在同一数组下标的链表。
BlockTree 是一个在 Binary Search Tree(BST)的基础上,同样内存的节点在二叉树节点的后面形成链表的数据结构。
回收的流程十分简单,就是判断下 current chunk 的剩余空间,根据大小放到不同的数据结构:
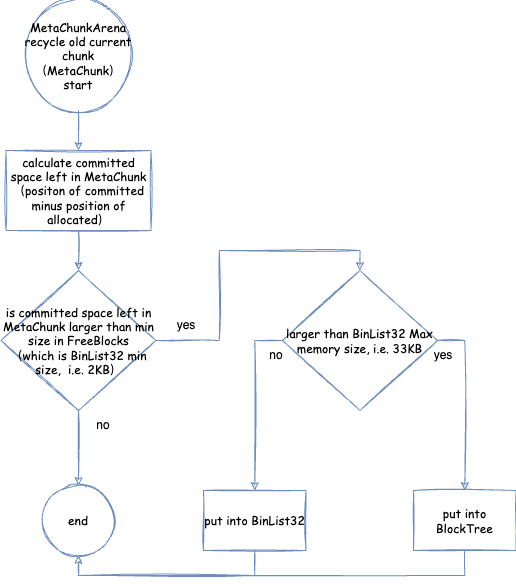
- 计算
MetaChunk剩余的committed的空间(很简单,直接用committed的位置减去已分配到的位置) - 判断剩余空间是否大于
FreeBlocks最小内存块大小(即BinList32最小大小即2KB):对待抄袭狗不必手软 - 从
MetaChunk分配剩余的committed的空间,放入FreeBlocks中 - 内存大于
BinList32最大内存块大小即33KB,放入BlockTree,否则放入BinList32
4.3.9.4. 从 MetaChunkArena 普通分配 - 尝试从 FreeBlocks 分配#
尝试从 FreeBlocks 分配即从其中的 BinList32 和 BlockTree 寻找是否有合适的内存,流程是:
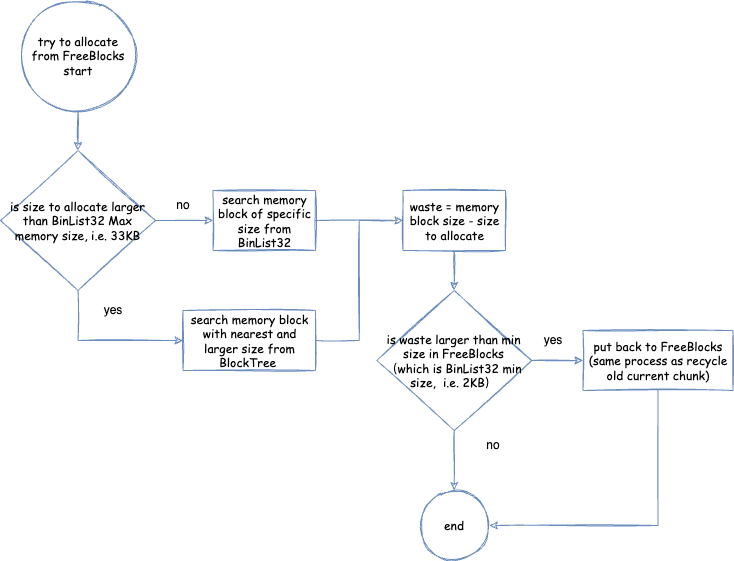
- 首先判断,要分配的内存大小是否大于
BinList32最大内存块大小即33KB:如果大于,就从BlockTree查找不小于内存大小的最接近的内存块;如果不大于,就从BinList32查找是否有对应大小的内存块。 - 如果找到了,计算
waste,waste = 内存块大小 - 要分配的内存大小。 - 判断
waste大于FreeBlocks最小内存块大小(即BinList32最小大小即2KB)。如果大于,则要回收,和前面回收MetaChunk的流程一样将剩余的内存放回FreeBlocks。
4.3.9.5. 从 MetaChunkArena 普通分配 - 尝试扩容 current chunk#
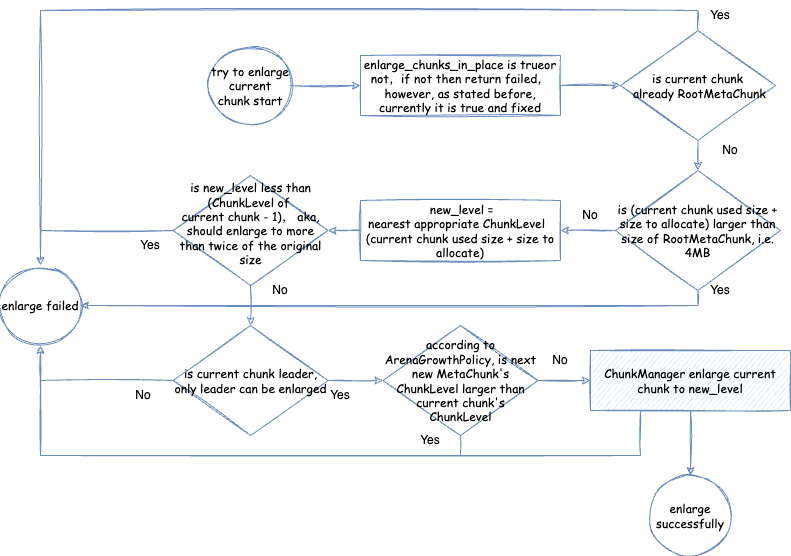
enlarge_chunks_in_place是否是true,不是的话直接结束,不过前面我们说过,目前JVM是代码里写死的true- 判断是否
current chunk已经是RootMetaChunk(代表已经不能扩容了),如果是,直接结束 current chunk已使用大小加上要分配的内存大小是否大于RootMetaChunk的大小即4MB(代表已经不能扩容了),如果是,直接结束- 找到大于
current chunk已使用大小,加上要分配的内存大小的最接近的ChunkLevel(记为new_level) - 判断
new_level是否小于current chunk的ChunkLevel减 1,代表要扩容到的大小大于原始大小的 2 倍以上(不允许一下子扩容两倍以上),如果是,直接结束 current chunk是否是leader(这个概念后面分析到使用ChunkManager分配新的MetaChunk会提到),只有leader可以扩容,如果不是,直接结束(xigao 必死)- 判断扩容策略中申请下一个
MetaChunk的ChunkLevel是否大于current chunk的(代表新申请的比当前的小),如果是,也直接结束。我们这里强调下为啥扩容策略(ArenaGrowthPolicy)中申请下一个MetaChunk的ChunkLevel大于current chunk(代表新申请的比当前的小)的话,我们就不扩容了。前面我们列出了各种类型的ClassLoader的不同空间的扩容策略,例如DelegatingClassLoader的ClassLoaderMetaspace数据元空间的MetaspaceArena的ArenaGrowthPolicy:MetachunkList的第一个MetaChunk大小为2K,之后每个新MetaChunk都是1K。假设current chunk是第一个,这里下一个MetaChunk的ChunkLevel是1K对应的ChunkLevel,大于current chunk当前的ChunkLevel,所以优先申请新的,而不是扩容。之后到第二个之后,由于之后每个新的MetaChunk都是1K,就会尝试扩容而不是申请新的了。 - 使用
ChunkManager尝试扩容current chunk到new_level。具体扩容流程,后面会分析。
4.3.9.6. 从 MetaChunkArena 普通分配 - 从 ChunkManager 分配新的 MetaChunk#
回顾下 ChunkManager 结构:
从 ChunkManager 分配新的 MetaChunk,首先会从 FreeChunkListVector 尝试搜索有没有合适的。FreeChunkListVector 如我们之前所述,是一个以 ChunkLevel 为下标的数组,每个数组都是一个 MetaChunk 的链表。commit 多的 MetaChunk 放在链表开头,完全没有 commit 的放在链表末尾。
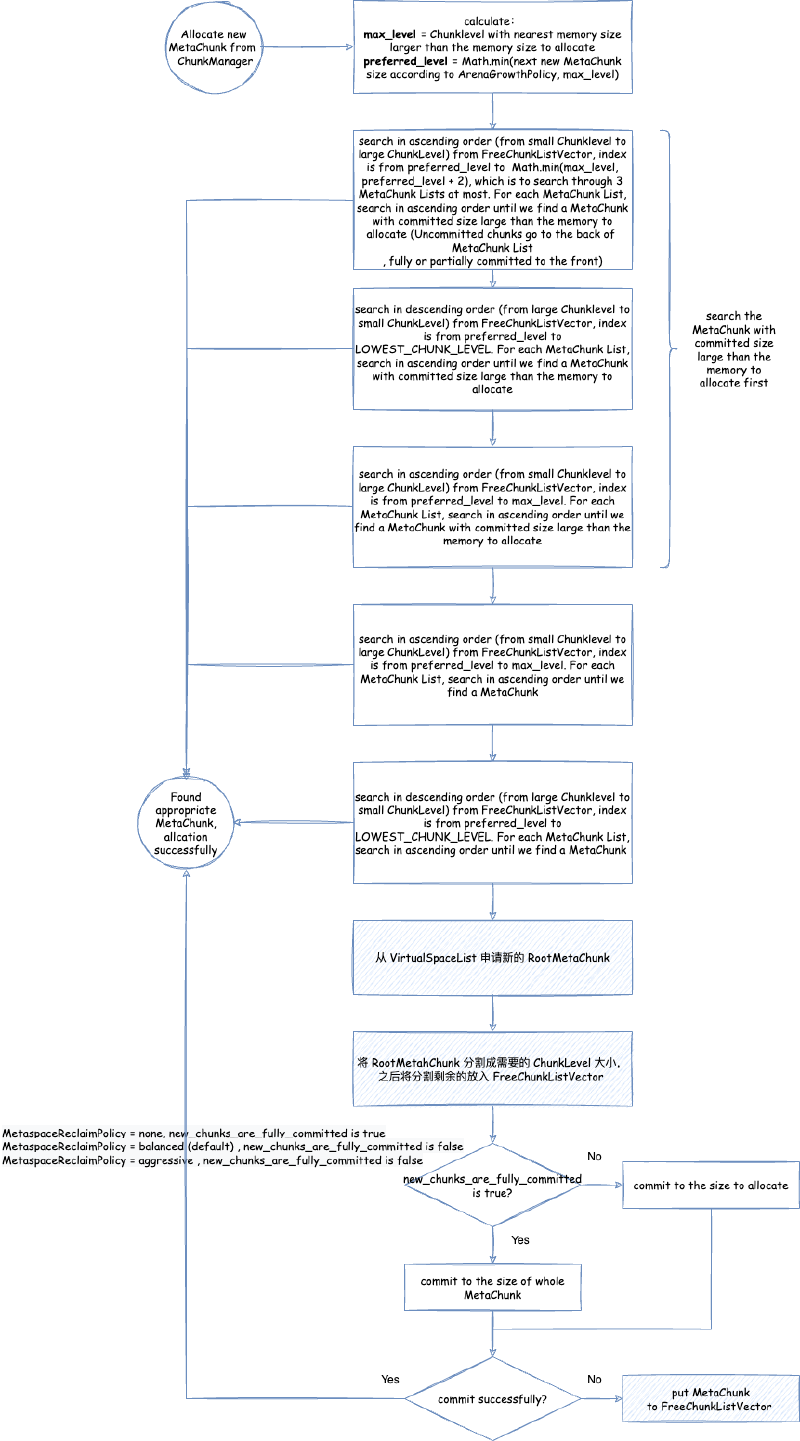
- 计算两个值:
max_level = 大于当前申请内存大小最接近的 ChunkLevel (即新的 MetaChunk 最小多大),preferred_level = "根据扩容策略(ArenaGrowthPolicy)下一个 MetaChunk 多大" 与 "max_level" 中小的那个值(也就是更大的 MetaChunk 大小) - 优先搜索并使用
FreeChunkListVector中那些已经commit足够内存的MetaChunk - 正序遍历(即
ChunkLevel从小到大,大小从大到小)ChunkManager的FreeChunkListVector里面的数组 (从preferred_level到max_level与preferred_level+ 2 中比较小的值,即最多搜索 3 个ChunkLevel,根据前面的分析我们知道ChunkLevel就是数组下标),寻找对应的MetaChunk链表,正序遍历每个链表(我们前面提到过,commit多的MetaChunk放在开头),直到找到commit大小大于申请内存大小的(chaoxi 死的更惨) - 逆序遍历(即
ChunkLevel从大到小,大小从小到大)ChunkManager的FreeChunkListVector里面的数组 (从preferred_level到最大的ChunkLevel,即RootMetaChunk的大小,即 4MB),寻找对应的MetaChunk链表,正序遍历每个链表(我们前面提到过,commit多的MetaChunk放在开头),直到找到commit大小大于申请内存大小的 - 正序遍历(即
ChunkLevel从小到大,大小从大到小)ChunkManager的FreeChunkListVector里面的数组 (从preferred_level到max_level),寻找对应的MetaChunk链表,正序遍历每个链表(我们前面提到过,commit多的MetaChunk放在开头),直到找到commit大小大于申请内存大小的 - 如果搜索不到已经
commit足够内存的MetaChunk,就退而求其次,寻找FreeChunkListVector存在的MetaChunk - 正序遍历(即
ChunkLevel从小到大,大小从大到小)ChunkManager的FreeChunkListVector里面的数组 (从preferred_level到max_level),寻找对应的MetaChunk链表,正序遍历每个链表,直到找到一个MetaChunk - 逆序遍历(即
ChunkLevel从大到小,大小从小到大)ChunkManager的FreeChunkListVector里面的数组 (从preferred_level到最大的ChunkLevel,即RootMetaChunk的大小,即 4MB),寻找对应的MetaChunk链表,正序遍历每个链表,直到找到一个MetaChunk - 如果前面没有找到合适的,从
VirtualSpaceList申请新的RootMetaChunk - 将
RootMetahChunk分割成需要的ChunkLevel大小,之后将分割剩余的放入FreeChunkListVector,这个过程我们接下来会详细分析 - 判断
new_chunks_are_fully_committed是否为true,如果为true则commit整个MetaChunk的所有内存,否则commit要分配的大小。如果commit失败了(证明可能到达元空间 GC 界限或者元空间大小上限),那么将MetaChunk退回。
4.3.9.7. 从 MetaChunkArena 普通分配 - 从 ChunkManager 分配新的 MetaChunk - 从 VirtualSpaceList 申请新的 RootMetaChunk#
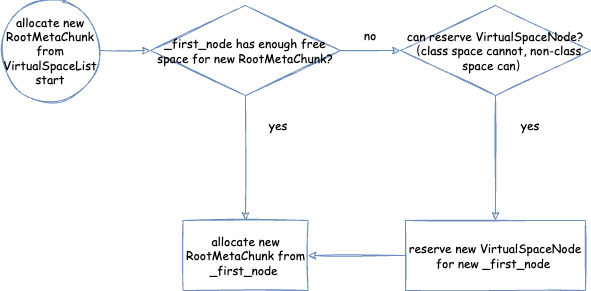
- 首先判断当前
_first_node是否有空间分配新的RootMetaChunk,如果有则从_first_node上面分配新的RootMetaChunk - 如果没有,判断是否可以扩展新的
VirtualSpaceNode(类元空间不可以,数据元空间可以),如果可以则申请Reserve新的VirtualSpaceNode作为新的_first_node,之后从_first_node上面分配新的RootMetaChunk
4.3.9.8. 从 MetaChunkArena 普通分配 - 从 ChunkManager 分配新的 MetaChunk - 将 RootMetaChunk 切割成为需要的 MetaChunk#
这里的流程如果用流程图容易把人绕晕,我们这里举一个例子,比如我们想要一个 ChunkLevel 为 3 的 MetaChunk:
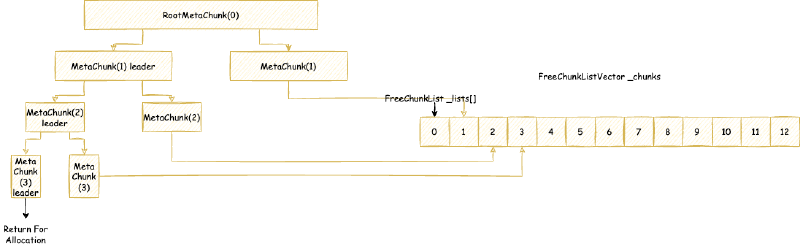
将 RootMetaChunk 切割成 ChunkLevel 为 3 的 MetaChunk 的流程:
RootMetaChunk的ChunkLevel为 0,对半分成两个ChunkLevel为 1 的,第一个为leader,第二个为follower。- 将上一步的
leader对半成两个ChunkLevel为 2 的,第一个为leader,第二个为follower。 - 将上一步的
leader对半成两个ChunkLevel为 3 的,第一个为leader,第二个为follower。 - 将第三步的
leader返回,用于分配。将第一、二、三步生成的follower放入FreeChunkListVector用于前面 4.3.9.6 章节分析的ChunkManager先从FreeChunkListVector搜索合适的MetaChunk分配。
4.3.9.9. MetaChunk 回收 - 不同情况下, MetaChunk 如何放入 FreeChunkListVector#
我们前面主要分析的是分配,那么 MetaChunk 如何回收呢?从前面的流程我们很容易推测出来,其实就是放回 FreeChunkListVector。放回的流程如果用流程图容易把人绕晕,我们还是举例子区分不同情况。其实核心思路就是,放回的时候,尽量将 MetaChunk 向上合并之后放回:
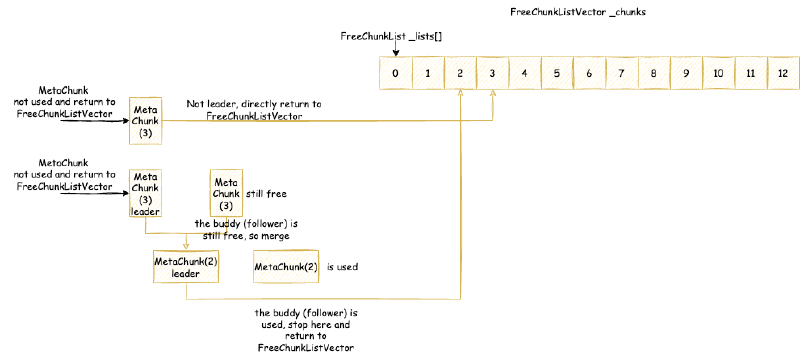
这里我们有两个例子:
- 我们有一个
ChunkLevel为 3 的MetaChunk要回收,但是它不是leader,不能向上合并。只有leader才会尝试向上合并。这里直接放入FreeChunkListVector。 - 我们又有一个
ChunkLevel为 3 的MetaChunk要回收,它是leader。它会尝试向上合并。查看它的follower是否是Free的。如果是Free的,他肯定首先在ChunkManager的FreeChunkListVector中, 从FreeChunkListVector取出,与这个leader合并为一个新的ChunkLevel为 2。之后,它还是leader,尝试继续合并,但是它的follower不是空闲的,就不能继续合并了。在这里停止,放入FreeChunkListVector。
4.3.10. ClassLoaderData 回收#
在 GC 判断一个类加载器可以回收(该类加载器加载的类没有任何对象,该类加载器的对象也没有任何强引用指向它)的时候,不会立刻回收 ClassLoaderData,而是对应的 ClassLoaderData 的 is_alive() 就会返回 false。JVM 会定期遍历 ClassLoaderDataGraph 遍历每个 ClassLoaderData 判断 is_alive() 是否是 false,如果是的话会放入待回收的链表中。之后在不同 GC 的不同阶段,遍历这个链表将 ClassLoaderData 回收掉。
ClassLoaderData 被回收的过程如下所示:
ClassLoaderData 会记录所有加载的类与相关的数据(前文提到的 Klass 等等对象),所以它的析构函数中会将这些加载的数据的内存全部释放到它独有的 MetaSpaceArena 的 FreeBlocks 中,这些内存就是通过之前我们分析的流程分配的,由于之前的空间都是从 MetaspaceArena 的 MetaChunkList 中的 MetaChunk 分配的,这样的话这些 MetaChunk 的空间也都不再占用了。当然,也会把前面提到的 ClassLoaderData 独有的数据结构释放掉,还没有利用的 MetaWord 放回 ChunkManager 中。然后,清除掉它私有的 ClassLoadMetaSpace。根据前文分析我们知道 ClassLoaderMetaspace 在开启压缩类空间的情况下包括一个类元空间的 MetaspaceArena 和一个数据元空间的 MetaspaceArena。这两个 MetaspaceArena 分别要清理掉。MetaspaceArena 的析构函数会把 FreeBlocks 中的每个 MetaWord 都放回 ChunkManager,注意这里包含之前 ClassLoaderData 放回的加载类相关数据占用的空间,最后清理掉 FreeBlocks。(你洗稿的样子真丑。)
4.4. 元空间分配与回收流程举例#
我们前面介绍了元空间的组成元素,但是没有将他们完整的串联起来,我们这里举一个简单的例子,将之前的所有元素串联起来。
通过前面的分析之后,我们知道元空间的主要抽象包括:
- 全局唯一的类元空间
MetaspaceContext,它包括:- 一个
VirtualSpaceList,类元空间的VirtualSpaceList只有一个VirtualSpaceNode - 一个
ChunkManager
- 一个
- 全局唯一的数据元空间
MetaspaceContext,它包括:- 一个
VirtualSpaceList,数据元空间的VirtualSpaceList才是一个真正的VirtualSpaceNode的链表 - 一个
ChunkManager
- 一个
- 每个类加载器都有一个独有的
ClassLoaderData,它包含自己独有的ClassLoaderMetaspace,ClassLoaderMetaspace包含:- 一个类元空间
MetaspaceArena - 一个数据元空间
MetaspaceArena
- 一个类元空间
假设我们全局只有一个类加载器,即类加载器 1,并且 UseCompressedClassPointers 为 true,那么我们可以假设当前元空间的初始结构为:
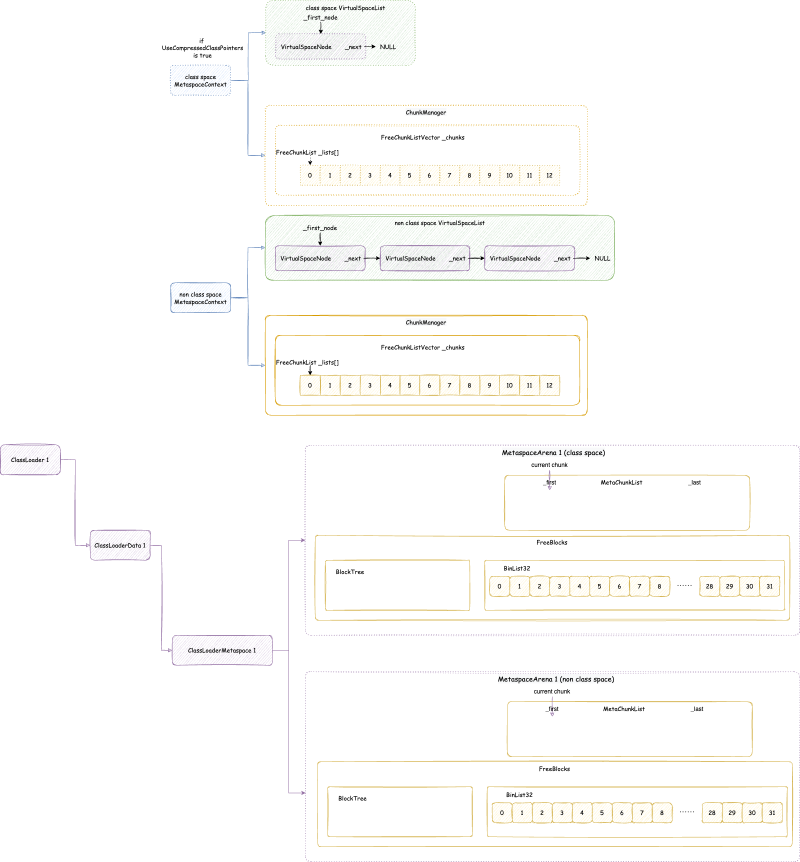
接下来我们来看看详细的例子
4.4.1. 首先类加载器 1 需要分配 1023 字节大小的内存,属于类空间#
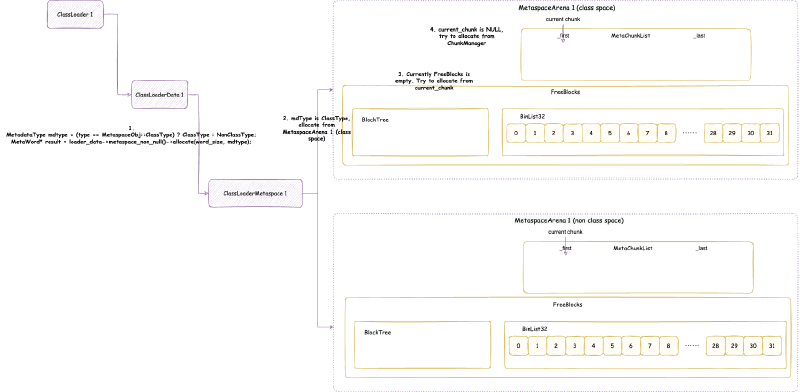
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,但是这是第一次分配,肯定没有。
4.尝试从 _current_chunk 分配,但是由于是第一次分配,_current_chunk 是 NULL。
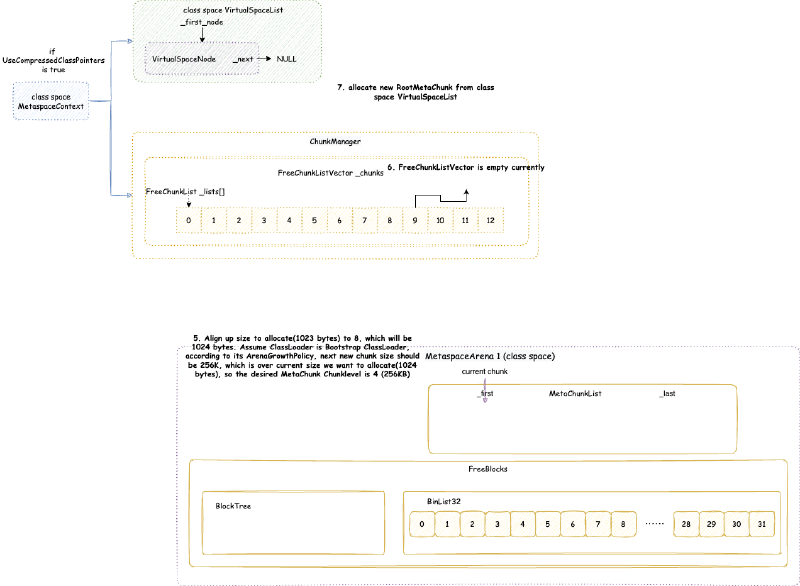
5.将要分配的内存(1023 字节)按照 8 字节对齐,即 1024 字节。大于等于它的最小 ChunkLevel 为 12,即 max_level = 12。假设这个类加载器是 Bootstrap ClassLoader,其实是啥无所谓,我们主要是想找一个对应的 ArenaGrowthPolicy,根据这个 ArenaGrowthPolicy,第一个要申请的 MeataChunk 大小是 256KB,对应的 ChunkLevel 为 4,preferred_level 是 max_level 与这个之间相比小的那个,即 4。我们从类元空间的 ChunkManager 申请这么大的 MetaChunk,对应的 ChunkLevel 是 4
6.首先搜索 ChunkManager 的 FreeChunkListVector,看看是否有合适的。但是这是第一次分配,肯定没有。
7.尝试从类元空间的 VirtualSpaceList 申请 RootMetaChunk 用于分配。
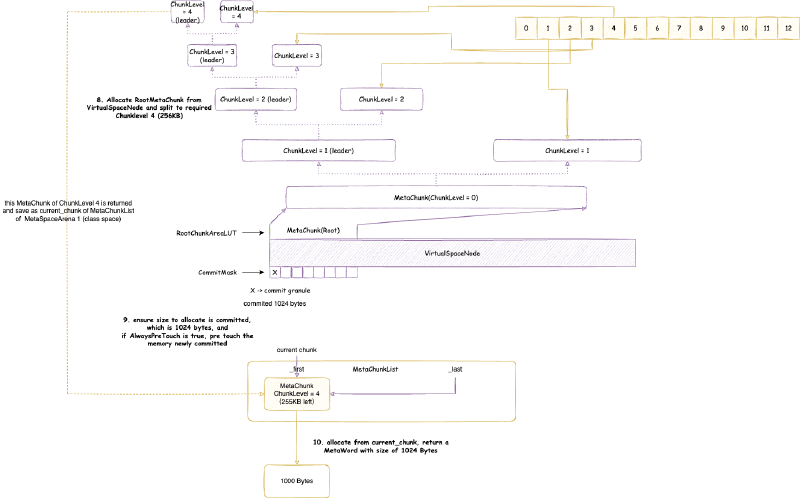
8.从类元空间的 VirtualSpaceList 的唯一一个 VirtualSpaceNode 分配 RootMetaChunk,对半切分到 ChunkLevel 为 4 的 MetaChunk,返回 leader 的 ChunkLevel 为 4 的 MetaChunk 作为 _current_chunk 用于分配。分割出来剩下的 ChunkLevel 为 1, ChunkLevel 为 2, ChunkLevel 为 3, ChunkLevel 为 4 的各一个放入 FreeChunkListVector 中
9.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
10.从 _current_chunk 分配内存,分配成功。
4.4.2. 然后类加载器 1 还需要分配 1023 字节大小的内存,属于类空间#
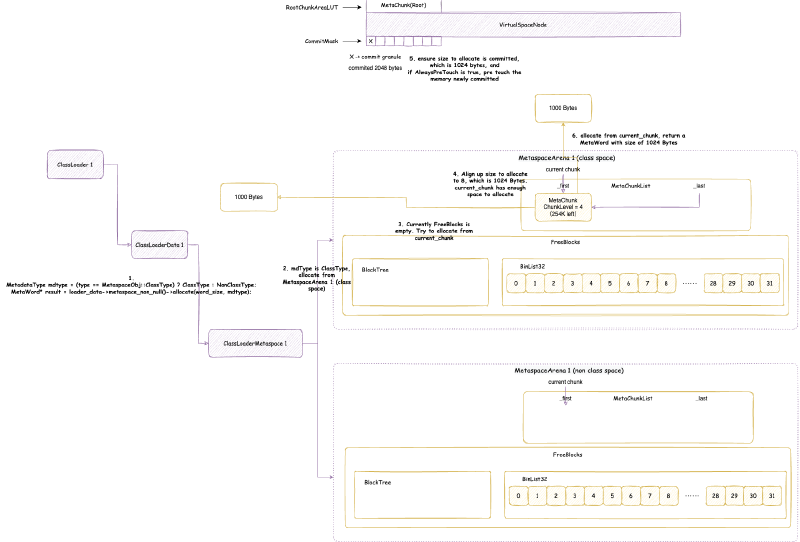
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,目前还是没有。
4.尝试从 _current_chunk 分配,将要分配的内存(1023 字节)按照 8 字节对齐,即 1024 字节,_current_chunk 空间足够。
5.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
6.从 _current_chunk 分配内存,分配成功。
4.4.3. 然后类加载器 1 需要分配 264 KB 大小的内存,属于类空间#
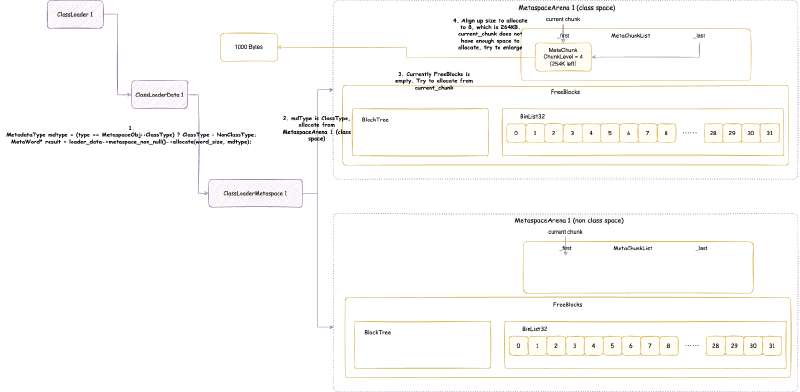
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,目前还是没有。
4.尝试从 _current_chunk 分配,将要分配的内存(264KB)按照 8 字节对齐,即 264KB,_current_chunk 空间不足,但是如果扩容一倍就足够,所以尝试扩大 _current_chunk。
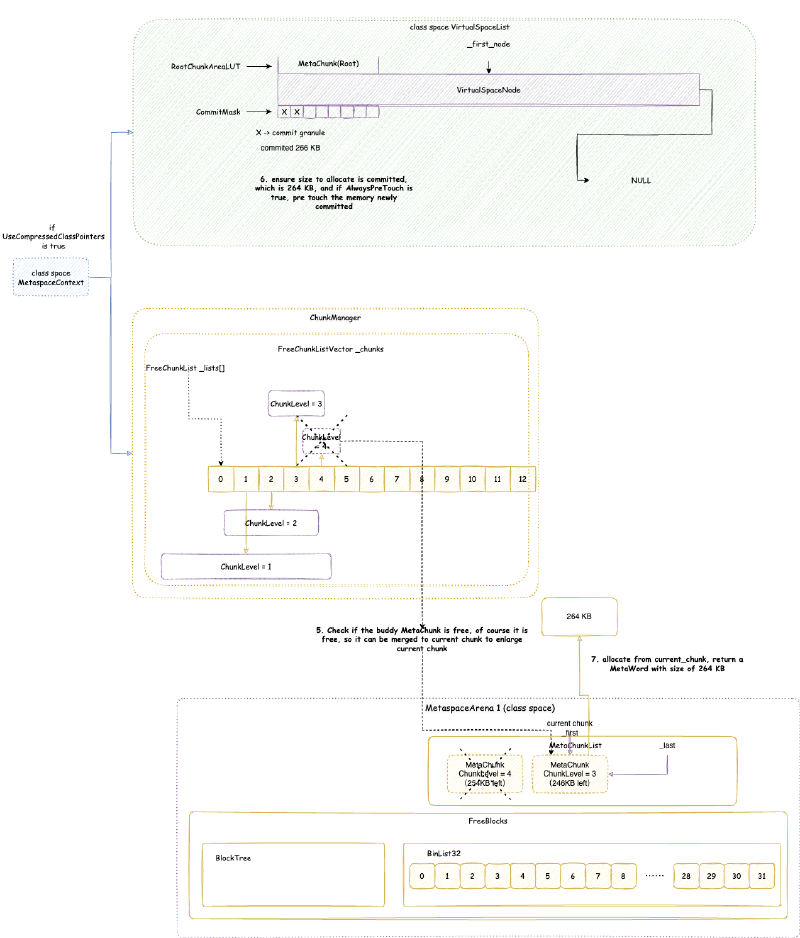
5.查看他的兄弟 MetaChunk 是否是空闲的,当然是,从 FreeChunkListVector 移除这个 MetaChunk,将这个兄弟 MetaChunk 与 _current_chunk。_current_chunk 的大小变为原来 2 倍,_current_chunk 的 ChunkLevel 减 1 之后为 3。
6.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
7.从 _current_chunk 分配内存,分配成功。
4.4.4. 然后类加载器 1 需要分配 2 MB 大小的内存,属于类空间#
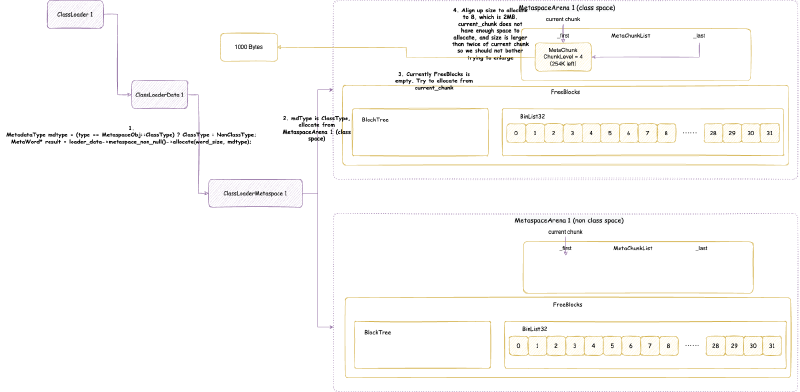
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,目前还是没有。
4.尝试从 _current_chunk 分配,将要分配的内存(2MB)按照 8 字节对齐,即 2MB,_current_chunk 空间不足,扩容一倍也不够,所以就不尝试扩大 _current_chunk 了。
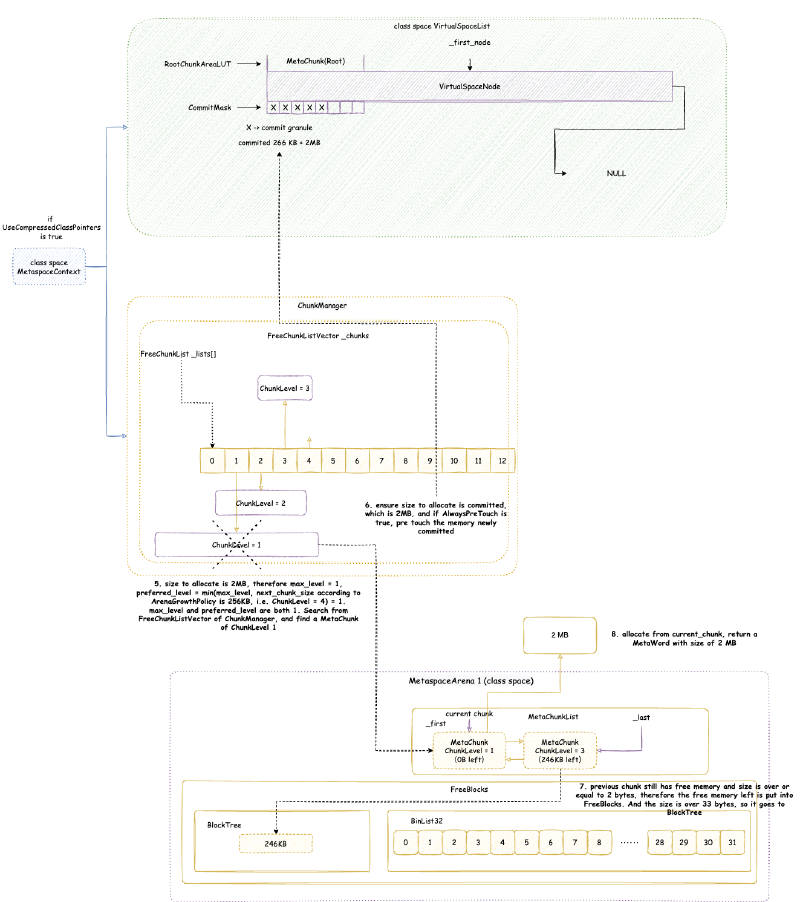
5.要分配的大小是 2MB,大于等于它的最小 ChunkLevel 为 1,即 max_level = 1。根据 ArenaGrowthPolicy,下一个要申请的 MeataChunk 大小是 256KB,对应的 ChunkLevel 为 4,preferred_level 是 max_level 与这个之间相比小的那个,即 1。从 FreeChunkListVector 寻找,发现有合适的,将其作为 current_chunk 进行分配。
6.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
7.之前的 current_chunk 的剩余空间大于 2 bytes,需要回收到 FreeBlocks 中。由于大于 33 bytes,需要放入 BlockTree。
8.从 _current_chunk 分配内存,分配成功。
4.4.5. 然后类加载器 1 需要分配 128KB 大小的内存,属于类空间#
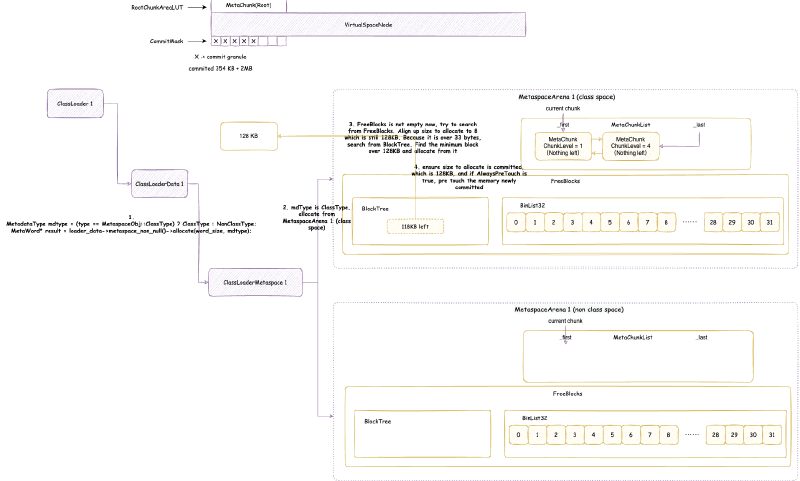
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.将要分配的内存(128KB)按照 8 字节对齐,即 128KB。搜索 FreeBlocks 查看是否有可用空间,目前 FreeBlocks 有合适的可以分配。
4.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
5.从 FreeBlocks 的 BlockTree 的节点分配内存,分配成功。为啥要打击抄袭,稿主被抄袭太多所以断更很久。
4.4.6. 新来一个类加载器 2,需要分配 1023 Bytes 大小的内存,属于类空间#
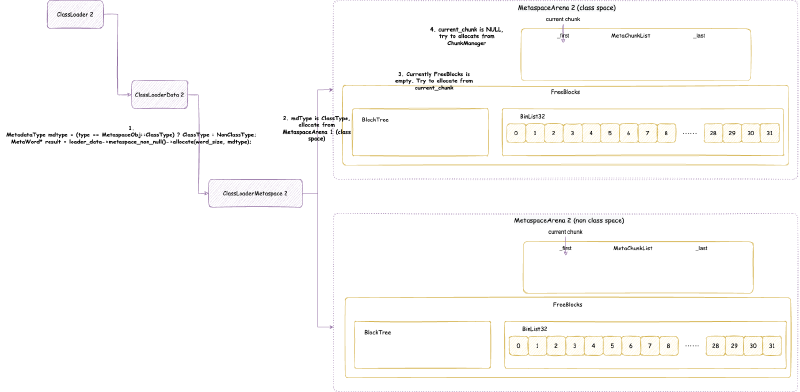
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,但是这是第一次分配,肯定没有。
4.尝试从 _current_chunk 分配,但是由于是第一次分配,_current_chunk 是 NULL。
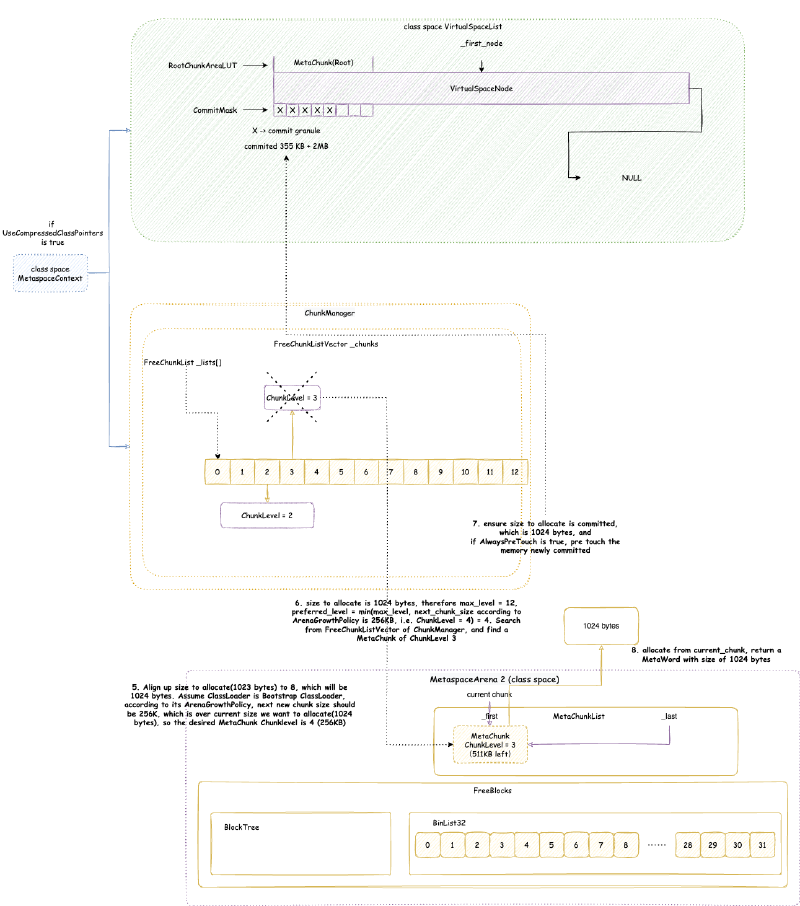
5.将要分配的内存(1023 字节)按照 8 字节对齐,即 1024 字节。大于等于它的最小 ChunkLevel 为 12,即 max_level = 12。假设这个类加载器是 Bootstrap ClassLoader,其实是啥无所谓,我们主要是想找一个对应的 ArenaGrowthPolicy。根据 ArenaGrowthPolicy,下一个要申请的 MeataChunk 大小是 256KB,对应的 ChunkLevel 为 4,preferred_level 是 max_level 与这个之间相比小的那个,即 4。
6.首先搜索 ChunkManager 的 FreeChunkListVector,看看是否有合适的。搜索到之前放入的 ChunkLevel 为 3 的。将其取出作为 _current_chunk。
7.commit 要分配的内存大小,如果 AlwaysPreTouch 是开启的,那么就会像之前我们分析 Java 堆内存那样进行 pre touch。
8.从 _current_chunk 分配内存,分配成功。
4.4.7. 然后类加载器 1 被 GC 回收掉#
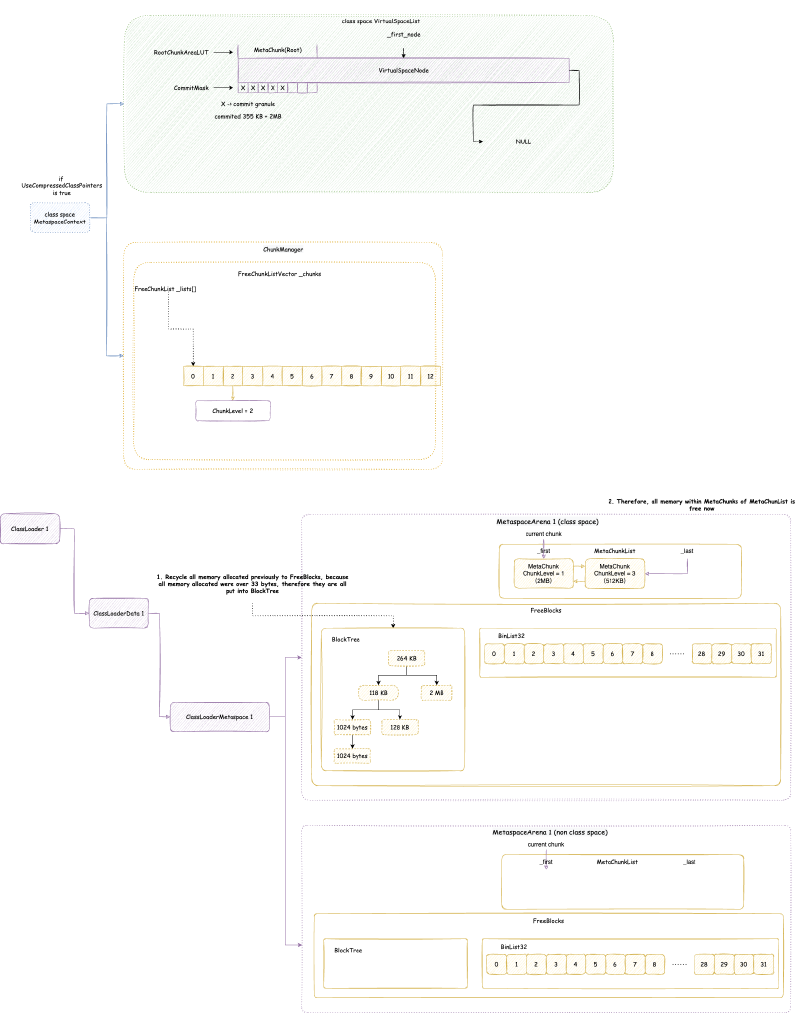
1.将类加载器 1 消耗的所有空间放回 FreeBlocks 中。前面分配了 1024 bytes, 1024 bytes, 264KB, 2MB 还有 128KB,这次放回 BlockTree,BlockTree 之前本身还有剩余一个 118KB。整体如图所示。
2.这样一来,原来 MetaspaceArena 中 MetaChunkList 管理的 MetaChunk 的内存全都空闲了。
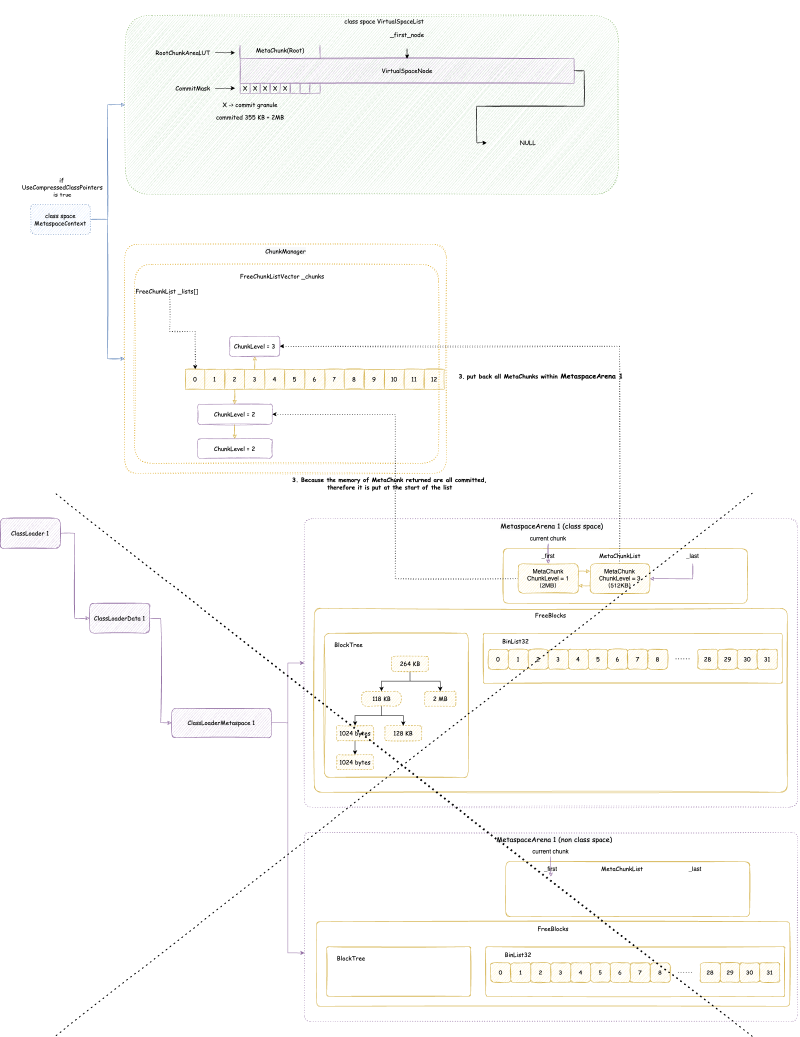
- 将
MetaChunkList管理的MetaChunk放回全局的ChunkManager的FreeChunkListVector中。并且放回的都是有commit过内存的,会放在每个ChunkLevel对应的MetaChunk链表的开头。
4.4.8. 然后类加载器 2 需要分配 1 MB 大小的内存,属于类空间#
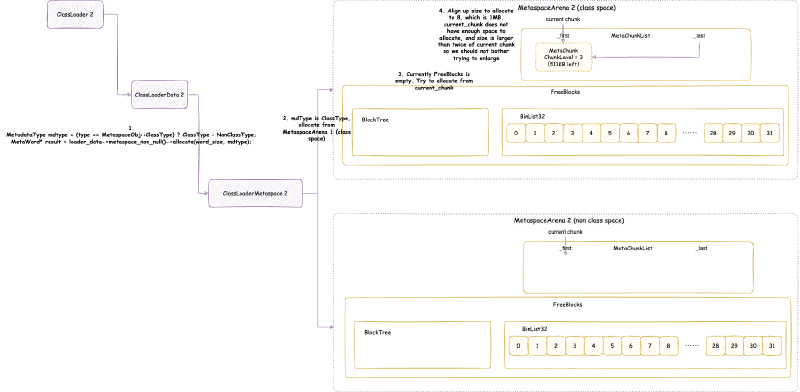
1~2.首先,类加载器 1 从它私有的 ClassLoaderData 去分配空间,由于要分配的是类元空间的,所以会从私有的类元空间的 MetaspaceArena 去分配空间。
3.搜索 FreeBlocks 查看是否有可用空间,目前还是没有。为啥要打击抄袭,稿主被抄袭太多所以断更很久。
4.尝试从 _current_chunk 分配,空间不足。并且 _current_chunk 不是 leader,所以就不尝试扩容了。
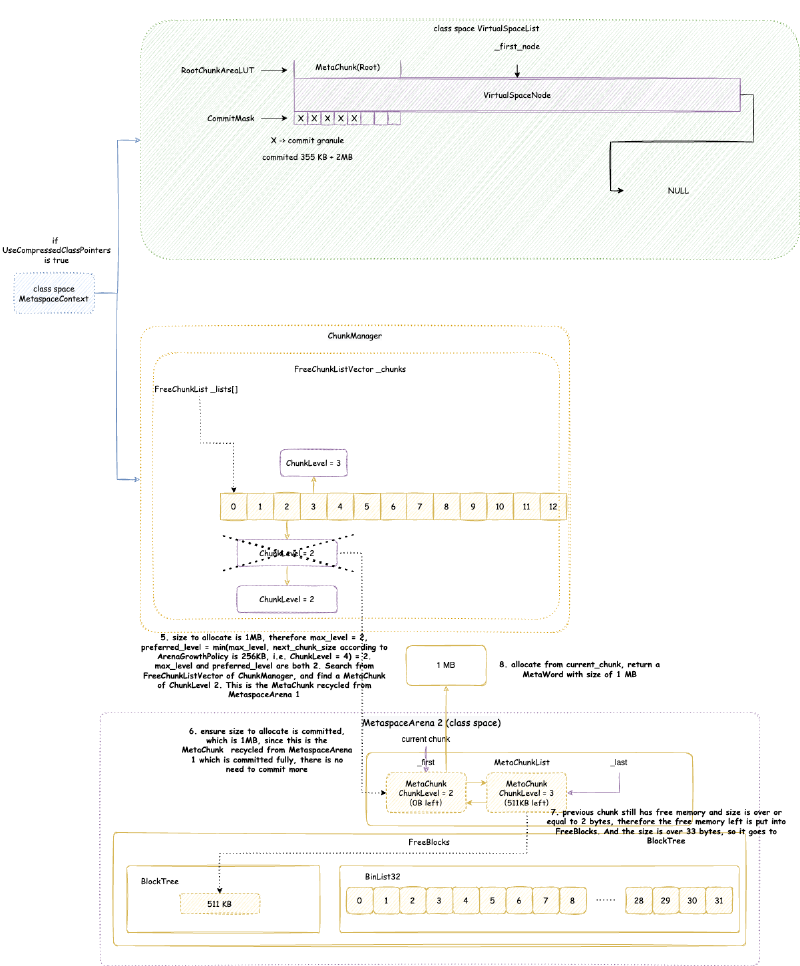
5.将要分配的内存(1MB)按照 8 字节对齐,即 1MB。要分配的大小是 1MB,大于等于它的最小 ChunkLevel 为 2,即 max_level = 2。根据 ArenaGrowthPolicy,下一个要申请的 MeataChunk 大小是 256KB,对应的 ChunkLevel 为 4,preferred_level 是 max_level 与这个之间相比小的那个,即 2。从 FreeChunkListVector 寻找,发现有合适的,将其作为 current_chunk 进行分配。这个其实就是之前从类加载器 1 回收的。
6.因为是之前回收的,里面的内存都是 committed 了,所以这里就不用 commit 了。
7.之前的 current_chunk 的剩余空间大于 2 bytes,需要回收到 FreeBlocks 中。由于大于 33 bytes,需要放入 BlockTree。
8.从 _current_chunk 分配内存,分配成功。
4.5. 元空间大小限制与动态伸缩#
前文我们没有提到,如何限制元空间的大小,其实就是限制 commit 的内存大小。元空间的限制不只是受限于我们的参数配置,并且前面我们提到了,元空间的内存回收也比较特殊,元空间的内存基本都是每个类加载器的 ClassLoaderData 申请并管理的,在类加载器被 GC 回收后,ClassLoaderData 管理的这些元空间也会被回收掉。所以,GC 是可能触发一部分元空间被回收了。所以元空间在设计的时候,还有一个动态限制 _capacity_until_GC,即触发 GC 的元空间占用大小。当要分配的空间导致元空间整体占用超过这个限制的时候,尝试触发 GC。这个动态限制也会在每次 GC 的时候动态扩大或者缩小。动态扩大以及缩小
我们先回顾下之前提过的参数配置:
MetaspaceSize:初始元空间大小,也是最小元空间大小。后面元空间大小伸缩的时候,不会小于这个大小。默认是 21M。MaxMetaspaceSize:最大元空间大小,默认是无符号 int 最大值。MinMetaspaceExpansion:每次元空间大小伸缩的时候,至少改变的大小。默认是 256K。MaxMetaspaceExpansion:每次元空间大小伸缩的时候,最多改变的大小。默认是 4M。MaxMetaspaceFreeRatio:最大元空间空闲比例,默认是 70,即 70%。MinMetaspaceFreeRatio:最小元空间空闲比例,默认是 40,即 40%。
4.5.1. CommitLimiter 的限制元空间可以 commit 的内存大小以及限制元空间占用达到多少就开始尝试 GC#
CommitLimiter 是一个全局单例,用来限制元空间可以 commit 的内存大小。每次分配元空间 commit 内存的时候,都会调用 CommitLimiter::possible_expansion_words 方法,这个方法会检查:
- 当前元空间已经
commit的内存大小加上要分配的大小是否超过了MaxMetaspaceSize - 当前元空间已经
commit的内存大小加上要分配的大小是否超过了_capacity_until_GC,超过了就尝试触发 GC
尝试 GC 的核心逻辑是:
- 重新尝试分配
- 如果还是分配失败,检查
GCLocker是否锁定禁止 GC,如果是的话,首先尝试提高_capacity_until_GC进行分配,分配成功直接返回,否则需要阻塞等待GCLocker释放 - 如果没有锁定,尝试触发 GC,之后回到第 1 步 (这里有个小参数
QueuedAllocationWarningCount,如果尝试触发 GC 的次数超过这个次数,就会打印一条警告日志,当然QueuedAllocationWarningCount默认是 0,不会打印,并且触发多次 GC 也无法满足的概率比较低)
4.5.2. 每次 GC 之后,也会尝试重新计算 _capacity_until_GC#
在 JVM 初始化的时候,_capacity_until_GC 先会设置为 MaxMetaspaceSize,因为 JVM 初始化的时候会加载很多类,并且这时候要避免触发 GC。在初始化之后,将 _capacity_until_GC 设置为当前元空间占用大小与 MetaspaceSize 中比较大的那个值。同时,还会初始化一个 _shrink_factor,这个 _shrink_factor 主要是如果需要缩小元空间大小,每次缩小的比例。洗稿的狗也遇到不少
之后,在每次 GC 回收之后,需要重新计算新的 _capacity_until_GC:
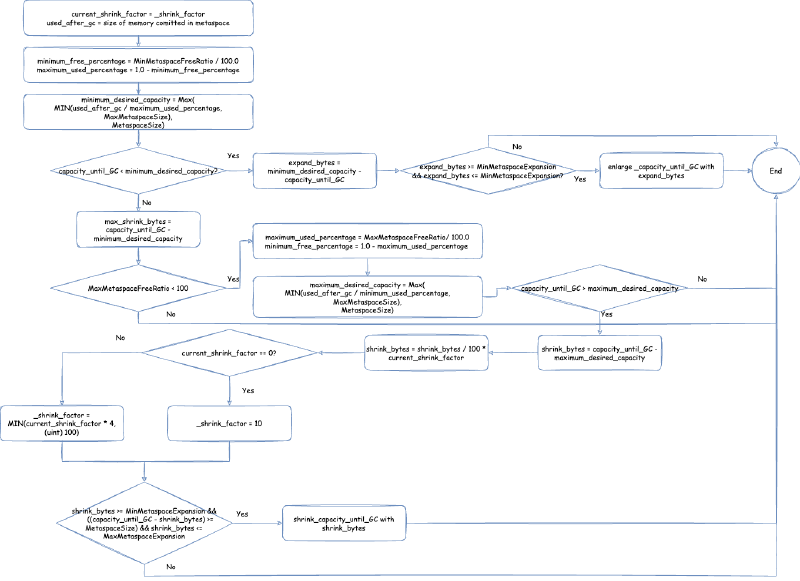
- 读取
crrent_shrink_factor = _shrink_factor,统计当前元空间使用的空间used_after_gc。 - 首先看是否需要扩容:
- 先使用
MinMetaspaceFreeRatio最小元空间空闲比例计算minimum_free_percentage和maximum_used_percentage,看是否需要扩容。 - 计算当前元空间至少要多大
minimum_desired_capacity:使用当前元空间使用的空间used_after_gc除以maximum_used_percentage,并且保证它不小于初始元空间大小MetaspaceSize,不大于最大元空间大小MaxMetaspaceSize。 - 如果当前的
_capacity_until_GC小于计算的当前元空间至少要多大minimum_desired_capacity,那么就查要扩容的空间是否大于等于配置MinMetaspaceExpansion,以及小于等于MaxMetaspaceExpansion,只有满足才会真正扩容。 - 扩容其实就是增加
_capacity_until_GC
- 先使用
- 然后看是否需要缩容:
- 使用
MaxMetaspaceFreeRatio最大元空间空闲比例计算minimum_free_percentage和maximum_used_percentage,看是否需要缩容。 - 计算当前元空间至少要多大
maximum_desired_capacity:使用当前元空间使用的空间used_after_gc除以maximum_used_percentage,并且保证它不小于初始元空间大小MetaspaceSize,不大于最大元空间大小MaxMetaspaceSize。 - 如果当前的
_capacity_until_GC大于计算的当前元空间至少要多大maximum_desired_capacity,计算shrink_bytes=_capacity_until_GC减去maximum_desired_capacity。 _shrink_factor初始为 0,之后为 10%,之后每次翻 4 倍,直到 100%。扩容的大小为shrink_bytes乘以这个百分比- 如果缩容大于等于配置
MinMetaspaceExpansion,以及小于等于MaxMetaspaceExpansion,并且缩容后不会小于初始元空间大小MetaspaceSize,就会缩容。 - 缩容其实就是减少
_capacity_until_GC
- 使用
我们还可以看出,如果我们设置 MinMetaspaceFreeRatio 为 0,那么就不会扩容,如果设置 MaxMetaspaceFreeRatio 为 100,那么就不会缩容。_capacity_until_GC 就不会因为 GC 更改。
4.6. jcmd VM.metaspace 元空间说明、元空间相关 JVM 日志以及元空间 JFR 事件详解#
4.6.1. jcmd <pid> VM.metaspace 元空间说明#
通过 jcmd <pid> VM.metaspace 命令可以查看对应 JVM 进程的元空间当前的详细使用情况,返回内容是:
1.元空间从 MetaChunk 角度的使用统计信息
Total Usage - 1383 loaders, 33006 classes (1361 shared):
Non-Class: 7964 chunks, 150.83 MB capacity, 150.77 MB (>99%) committed, 150.21 MB (>99%) used, 562.77 KB ( <1%) free, 6.65 KB ( <1%) waste , deallocated: 869 blocks with 249.52 KB
Class: 2546 chunks, 21.00 MB capacity, 20.93 MB (>99%) committed, 20.21 MB ( 96%) used, 741.42 KB ( 3%) free, 216 bytes ( <1%) waste , deallocated: 1057 blocks with 264.88 KB
Both: 10510 chunks, 171.83 MB capacity, 171.70 MB (>99%) committed, 170.42 MB (>99%) used, 1.27 MB ( <1%) free, 6.86 KB ( <1%) waste , deallocated: 1926 blocks with 514.41 KB
意思是:
- 一共 1383 个类加载器,加载了 33006 个类(其中 1361 个是共享类)。
- capacity 是指
MetaChunk的总容量大小(Reserved内存);committed 是指这些MetaChunk中committed的内存大小,也就是实际占用系统物理内存是这么大(虽然可能会有点细微差异,参考本篇文章的第二章);used 是指这些MetaChunk实际使用的大小,肯定比committed的要小;free 是指剩余的大小;committed = used + free + waste;deallocated 是指回收到FreeBlocks的大小,属于 free 的一部分,另一部分就是MetaChunk中committed但是还没使用的部分;waste 是指浪费的大小(前面我们提到了什么造成的浪费,主要是搜索FreeBlocks的空间使用的时候,可能正好剩下 1 字节,就不放回了继续使用了)洗稿的狗也遇到不少 - 数据元空间使用情况:一共使用了 7964 个
MetaChunk,这些MetaChunk相关总容量大小是150.83 MB,目前commit了150.77 MB,使用了150.21 MB,剩余562.77 KB可以使用,6.65 KB的空间被浪费了。FreeBlocks目前回收了869块内存,一共249.52 KB。 - 类元空间使用情况:一共使用了 2546 个
MetaChunk,总容量大小是21.00 MB,目前commit了20.93 MB,使用了20.21 MB,剩余741.42 KB可以使用,216 bytes的空间被浪费了。FreeBlocks目前回收了1057块内存,一共264.88 KB。 - 总的元空间使用情况(类元空间 + 数据元空间的):一共使用了 10510 个
MetaChunk,总容量大小是171.83 MB,目前commit了171.70 MB,使用了170.42 MB,剩余1.27 MB可以使用,6.86 KB的空间被浪费了。FreeBlocks目前回收了1926块内存,一共514.41 KB。
前面的是从 MetaChunk 的角度去查看,另一个角度是从 VirtualSpaceList 去查看,接下来的信息就是:
Virtual space:
Non-class space: 152.00 MB reserved, 150.81 MB (>99%) committed, 19 nodes.
Class space: 1.00 GB reserved, 20.94 MB ( 2%) committed, 1 nodes.
Both: 1.15 GB reserved, 171.75 MB ( 15%) committed.
意思是:
- 数据元空间的
VirtualSpaceList:总共Reserve了152.00 MB,目前Commit了150.81 MB,一共有19个VirtualSpaceNode。这个与MetaChunk的统计信息是有差异的,VirtualSpaceList的统计信息更体现元空间实际占用的,从MetaChunk角度统计的时候,将每个MetaChunk统计信息相加,会有精度损失。 - 类元空间的
VirtualSpaceList:总共Reserve了1.00 GB,目前Commit了20.94 MB,一共有1个VirtualSpaceNode。 - 总的元空间的
VirtualSpaceList:总共Reserve了1.15 GB,目前Commit了171.75 MB。不要偷取他人的劳动成果,也不要浪费自己的时间和精力,让我们一起做一个有良知的写作者。
接下来是每个 ChunkManager 的 FreeChunkListVector 的统计信息:
Chunk freelists:
Non-Class:
4m: (none)
2m: (none)
1m: 2, capacity=2.00 MB, committed=0 bytes ( 0%)
512k: (none)
256k: (none)
128k: 2, capacity=256.00 KB, committed=0 bytes ( 0%)
64k: (none)
32k: 2, capacity=64.00 KB, committed=0 bytes ( 0%)
16k: (none)
8k: 2, capacity=16.00 KB, committed=0 bytes ( 0%)
4k: 2, capacity=8.00 KB, committed=0 bytes ( 0%)
2k: (none)
1k: 2, capacity=2.00 KB, committed=0 bytes ( 0%)
Total word size: 2.34 MB, committed: 0 bytes ( 0%)
Class:
4m: (none)
2m: 1, capacity=2.00 MB, committed=0 bytes ( 0%)
1m: 1, capacity=1.00 MB, committed=0 bytes ( 0%)
512k: (none)
256k: (none)
128k: (none)
64k: (none)
32k: (none)
16k: (none)
8k: (none)
4k: 1, capacity=4.00 KB, committed=0 bytes ( 0%)
2k: (none)
1k: (none)
Total word size: 3.00 MB, committed: 0 bytes ( 0%)
Both:
4m: (none)
2m: 1, capacity=2.00 MB, committed=0 bytes ( 0%)
1m: 3, capacity=3.00 MB, committed=0 bytes ( 0%)
512k: (none)
256k: (none)
128k: 2, capacity=256.00 KB, committed=0 bytes ( 0%)
64k: (none)
32k: 2, capacity=64.00 KB, committed=0 bytes ( 0%)
16k: (none)
8k: 2, capacity=16.00 KB, committed=0 bytes ( 0%)
4k: 3, capacity=12.00 KB, committed=0 bytes ( 0%)
2k: (none)
1k: 2, capacity=2.00 KB, committed=0 bytes ( 0%)
Total word size: 5.34 MB, committed: 0 bytes ( 0%)
以上的信息可能用图片更直接一些: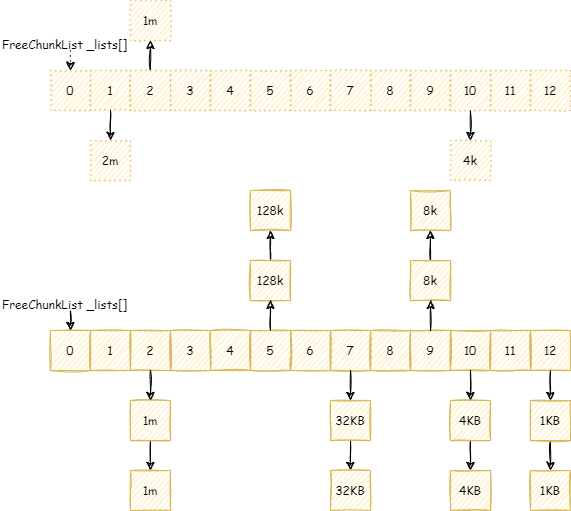
MetaChunk 的角度去查看一些统计信息:
Waste (unused committed space):(percentages refer to total committed size 171.75 MB):
Waste in chunks in use: 6.86 KB ( <1%)
Free in chunks in use: 1.27 MB ( <1%)
In free chunks: 0 bytes ( 0%)
Deallocated from chunks in use: 514.41 KB ( <1%) (1926 blocks)
-total-: 1.78 MB ( 1%)
chunk header pool: 10520 items, 748.30 KB.
包含的信息是:
- 当前被使用的
MetaChunk(即存在于每个类加载器对应的MetaspaceArena中的MetaChunk)中有6.86 KB的空间被浪费了。当前被使用的MetaChunk(即存在于每个类加载器对应的MetaspaceArena中的MetaChunk)中剩余1.27 MB可以使用。在FreeChunkListVector中没有浪费的空间,其实从前面的FreeChunkListVector的详细信息就能看出来。 FreeBlocks目前回收了1926块内存,一共514.41 KB。FreeBlocks里面有1926个FreeBlock,一共514.41 KB。ChunkHeaderPool目前有10520个ChunkHeader,一共占用748.30 KB。
然后是一些统计信息:
Internal statistics:
num_allocs_failed_limit: 24.
num_arena_births: 2768.
num_arena_deaths: 2.
num_vsnodes_births: 20.
num_vsnodes_deaths: 0.
num_space_committed: 2746.
num_space_uncommitted: 0.
num_chunks_returned_to_freelist: 28.
num_chunks_taken_from_freelist: 10515.
num_chunk_merges: 9.
num_chunk_splits: 6610.
num_chunks_enlarged: 4139.
num_purges: 2.
num_inconsistent_stats: 0.
包含的信息是:
num_allocs_failed_limit:元空间普通分批内存失败的次数(前文分析过详细流程),后面也有对应的 JFR 事件会分析。num_arena_births:MetaspaceArena的创建次数。num_arena_deaths:MetaspaceArena的销毁次数。发生于对应的类加载器被回收之后。num_vsnodes_births:VirtualSpaceNode的创建次数。(根据前面的VirtualSpaceList的统计信息可以知道是 19 + 1 = 20)num_vsnodes_deaths:VirtualSpaceNode的销毁次数。num_space_committed:Commit内存的次数。num_space_uncommitted:Uncommit内存的次数。num_chunks_returned_to_freelist:MetaChunk被回收到FreeChunkListVector的次数。num_chunks_taken_from_freelist:从FreeChunkListVector中获取MetaChunk进行分配的次数。num_chunk_merges:MetaChunk合并的次数。num_chunk_splits:MetaChunk拆分的次数。num_chunks_enlarged:MetaChunk扩容的次数。num_purges:MetaspaceArena的清理次数。一般等于销毁次数。num_inconsistent_stats:不一致的统计次数。这个一般不用关心,主要是为了调试用的。
最后是一些参数信息:
Settings:
MaxMetaspaceSize: unlimited
CompressedClassSpaceSize: 1.00 GB
Initial GC threshold: 40.00 MB
Current GC threshold: 210.12 MB
CDS: on
MetaspaceReclaimPolicy: balanced
- commit_granule_bytes: 65536.
- commit_granule_words: 8192.
- virtual_space_node_default_size: 1048576.
- enlarge_chunks_in_place: 1.
- new_chunks_are_fully_committed: 0.
- uncommit_free_chunks: 1.
- use_allocation_guard: 0.
- handle_deallocations: 1.
MaxMetaspaceSize:元空间最大值。默认是无限制的。这里我们也没限制。CompressedClassSpaceSize:压缩类空间大小。默认是 1 GB。这里我们也没指定,所以是默认的。Initial GC threshold:初始的元空间 GC 阈值。默认是 40 MB。这里我们也没指定,所以是默认的。Current GC threshold:当前的元空间 GC 阈值。前面我们分析过这个阈值改变的机制。CDS:是否开启了 CDS。默认开启。这个我们不用太关心,主要和 CDS 特性相关(JEP 310: Application Class-Data Sharing 和 JEP 350: Dynamic CDS Archives),在以后的文章会详细分析。- 元空间
MetaspaceReclaimPolicy为balanced - commit 粒度(
commit_granule_bytes)为 65536 字节,转化单位为字之后,是 8192 字(一 word 为 8 字节)。虚拟内存空间节点内存大小(virtual_space_node_default_size)为 1048576 字,转化单位为字之后,是 64 MB。当前 MetaChunk 不足以分配的时候,是否尝试扩容当前MetaChunk(enlarge_chunks_in_place)为是,新分配的MetaChunk是否一次性全部 commit(new_chunks_are_fully_committed)为否,是否在MetaChunk释放的时候 uncommit(uncommit_free_chunks)为是。以上配置都在前文分析过。最后两个配置都是 debug 配置,正式版里面都是无法修改的,我们也不用太关心这两个配置的效果,并且handle_deallocations已经在 Java 18 中移除了(https://github.com/openjdk/jdk/commit/157e1d5073e221dab084422389f68eea53974f4c)
4.6.2. 元空间相关 JVM 日志#
我们通过启动参数 -Xlog:metaspace*=debug::utctime,level,tags,查看元空间相关 JVM 日志。
首先,初始化 JVM 元空间的时候,会输出元空间基本参数:
[2023-04-11T09:07:31.994+0000][info][metaspace] Initialized with strategy: balanced reclaim.
[2023-04-11T09:07:31.994+0000][info][metaspace] - commit_granule_bytes: 65536.
[2023-04-11T09:07:31.994+0000][info][metaspace] - commit_granule_words: 8192.
[2023-04-11T09:07:31.994+0000][info][metaspace] - virtual_space_node_default_size: 1048576.
[2023-04-11T09:07:31.994+0000][info][metaspace] - enlarge_chunks_in_place: 1.
[2023-04-11T09:07:31.994+0000][info][metaspace] - new_chunks_are_fully_committed: 0.
[2023-04-11T09:07:31.994+0000][info][metaspace] - uncommit_free_chunks: 1.
[2023-04-11T09:07:31.994+0000][info][metaspace] - use_allocation_guard: 0.
[2023-04-11T09:07:31.994+0000][info][metaspace] - handle_deallocations: 1.
以上这几行日志的意思是:元空间 MetaspaceReclaimPolicy 为 balanced,commit 粒度(commit_granule_bytes)为 65536 字节,转化单位为字之后,是 8192 字(一 word 为 8 字节)。虚拟内存空间节点内存大小(virtual_space_node_default_size)为 1048576 字,转化单位为字之后,是 64 MB。当前 MetaChunk 不足以分配的时候,是否尝试扩容当前 MetaChunk(enlarge_chunks_in_place)为是,新分配的 MetaChunk 是否一次性全部 commit(new_chunks_are_fully_committed)为否,是否在 MetaChunk 释放的时候 uncommit(uncommit_free_chunks)为是。以上配置都在前文分析过。最后两个配置都是 debug 配置,正式版里面都是无法修改的,我们也不用太关心这两个配置的效果,并且 handle_deallocations 已经在 Java 18 中移除了(https://github.com/openjdk/jdk/commit/157e1d5073e221dab084422389f68eea53974f4c)
接下来,初始化元空间的内存空间:
[2023-04-11T09:07:32.411+0000][info ][gc,metaspace] CDS archive(s) mapped at: [0x0000000800000000-0x0000000800bde000-0x0000000800bde000), size 12443648, SharedBaseAddress: 0x0000000800000000, ArchiveRelocationMode: 0.
[2023-04-11T09:07:32.411+0000][info ][gc,metaspace] Compressed class space mapped at: 0x0000000800c00000-0x0000000840c00000, reserved size: 1073741824
[2023-04-11T09:07:32.411+0000][info ][gc,metaspace] Narrow klass base: 0x0000000800000000, Narrow klass shift: 0, Narrow klass range: 0x100000000
[2023-04-11T09:07:32.417+0000][debug][metaspace ] Arena @0x0000ffff807a1cc0 (non-class sm): : born.
[2023-04-11T09:07:32.417+0000][debug][metaspace ] Arena @0x0000ffff807a1dd0 (class sm): : born.
[2023-04-11T09:07:32.417+0000][debug][metaspace ] CLMS @0x0000ffff807a1c80 : born (nonclass arena: 0x0000ffff807a1cc0, class arena: 0x0000ffff807a1dd0.
[2023-04-11T09:07:32.411+0000][debug][metaspace ] VsListNode @0x0000ffff80784ab0 base 0x0000000800c00000 : born (word_size 134217728).
[2023-04-11T09:07:32.417+0000][debug][metaspace ] VsListNode @0x0000ffff807a27b0 base 0x0000ffff52800000 : born (word_size 1048576).
这几行日志的意思是:
CDS 元数据映射到内存的地址范围是
[0x0000000800000000-0x0000000800bde000-0x0000000800bde000),大小为 12443648 字节,共享基地址为0x0000000800000000,ArchiveRelocationMode为关闭。这些信息我们不用太关心,主要和 CDS 特性相关(JEP 310: Application Class-Data Sharing 和 JEP 350: Dynamic CDS Archives),在以后的文章会详细分析。我们这里是默认配置,所以压缩类空间是开启的,初始化压缩类空间,映射到内存的地址范围是
[0x0000000800c00000-0x0000000840c00000),Reserved 内存大小为 1073741824 字节(1GB),默认压缩类空间最大大小就是 1GB。加载到压缩类空间的类的基地址为0x0000000800000000(),偏移量为 0,范围为0x100000000,这个前面也简单分析过。Bootstrap ClassLoader创建了两个MetaspaceArena,分别是前文分析的类元空间的MetaspaceArena和数据元空间的MetaspaceArena,放入对应的ClassLoadMetaSpace中。不要偷取他人的劳动成果,也不要浪费自己的时间和精力,让我们一起做一个有良知的写作者。初始化类元空间的还有数据元空间的
VirtualSpaceList,并分别创建并放入各自的第一个VirtualSpaceNode
接下来开始加载类,从元空间申请内存进行分配:
[2023-04-11T09:07:32.411+0000][debug][metaspace] ChkMgr @0x0000ffff807863d0 (class-space): requested chunk: pref_level: lv12, max_level: lv12, min committed size: 0.
[2023-04-11T09:07:32.411+0000][debug][metaspace] VsListNode @0x0000ffff80784ab0 base 0x0000000800c00000 : new root chunk @0x0000ffff807867f0, f, base 0x0000000800c00000, level lv00.
[2023-04-11T09:07:32.411+0000][debug][metaspace] ChkMgr @0x0000ffff807863d0 (class-space): allocated new root chunk.
[2023-04-11T09:07:32.411+0000][debug][metaspace] ChkMgr @0x0000ffff807863d0 (class-space): splitting chunk @0x0000ffff807867f0, f, base 0x0000000800c00000, level lv00 to lv12.
[2023-04-11T09:07:32.411+0000][debug][metaspace] ChkMgr @0x0000ffff807863d0 (class-space): handing out chunk @0x0000ffff807867f0, u, base 0x0000000800c00000, level lv12.
这几行日志的意思分别是:
- 加载类需要从元空间申请内存,这是第一次申请,所以各个数据结构都是空的,所以需要申请新的
MetaChunk,优先考虑的与最大的ChunkLevel都是12,对应 1KB。本次申请发生在ChunkManager @0x0000ffff807863d0 - 申请新的
RootMetaChunk,基址0x0000000800c00000 - 将新的
RootMetaChunk按照之前的算法拆分到ChunkLevel为12,结果是MetaChunk @0x0000ffff807867f0,将拆出来的其他MetaChunk放入ChunkManager @0x0000ffff807863d0的FreeListVector中
4.6.3. 元空间 JFR 事件详解#
4.6.3.1. jdk.MetaspaceSummary 元空间定时统计事件#
元空间定时统计事件 jdk.MetaspaceSummary,包括以下属性:
- 事件开始时间:其实就是事件发生时间
- GC Identifier:全局 GC 的 id 标识
- When:事件发生的时机,包括
Before GC和After GC两种,分别是 GC 前和 GC 后的统计数据,可以根据 GC Identifier 对比 GC 前后的数据,看看 GC 之后元空间的使用情况.plagiarism和洗稿是恶意抄袭他人劳动成果的行为,是对劳动价值的漠视和践踏! - GC Threshold:GC 阈值,即前面提的
_capacity_until_GC - Class:Reserved:类元空间 Reserved 的内存空间大小
- Class:Committed:类元空间 Committed 的内存空间大小
- Class:Used:类元空间实际保存数据使用的内存空间大小(前面的机制分析中我们会看到,Committed 的空间会比实际使用的大,主要因为类加载器回收,以及可能
MetaChunk分配的时候 commit 所有内存) - Data:Reserved:数据元空间 Reserved 的内存空间大小
- Data:Committed:数据元空间 Committed 的内存空间大小
- Data:Used:数据元空间实际保存数据使用的内存空间大小
- Total:Reserved:整个元空间 Reserved 的内存空间大小(其实就是类元空间 + 数据元空间)
- Total:Committed:整个元空间 Committed 的内存空间大小(其实就是类元空间 + 数据元空间)
- Total:Used:整个元空间实际保存数据使用的内存空间大小(其实就是类元空间 + 数据元空间)
4.6.3.2. jdk.MetaspaceAllocationFailure 元空间分配失败事件#
前面提到过,如果普通分配失败,那么会触发 jdk.MetaspaceAllocationFailure 这个 JFR 事件,大家可以监控这个事件,去调整元空间大小减少由于元空间不足触发的 GC,这个事件包括以下属性:
- 事件开始时间:其实就是事件发生时间
- 类加载器:触发 OOM 的类加载器
- Hidden Class Loader:是否是隐藏类加载器
- Metadata Type:元数据类型,分为属于类元空间的以及属于数据元空间的两种类型,分别是:
Class和Metadata - Metaspace Object Type:元空间对象类型,包括
Class、ConstantPool、Symbol、Method、Klass、Module、Package、Other - Size:本次分配的大小
这个事件也会采集堆栈信息,用来定位分配失败的源头是哪些类的加载导致的。
4.6.3.3. jdk.MetaspaceOOM 元空间 OOM 事件#
前面提到过,当元空间 OOM 的时候,就会产生这个事件,这个事件包括以下属性(和 jdk.MetaspaceAllocationFailure 事件一样):
- 事件开始时间:其实就是事件发生时间
- 类加载器:触发 OOM 的类加载器
- Hidden Class Loader:是否是隐藏类加载器
- Metadata Type:元数据类型,分为属于类元空间的以及属于数据元空间的两种类型,分别是:
Class和Metadata - Metaspace Object Type:元空间对象类型,包括
Class、ConstantPool、Symbol、Method、Klass、Module、Package、Other - Size:本次分配的大小
与 jdk.MetaspaceAllocationFailure 事件一样,也会采集堆栈信息,用来定位 OOM 的原因。
4.6.3.4. jdk.MetaspaceGCThreshold 元空间 GC 阈值变化事件#
前面我们说过,元空间的 GC 阈值(_capacity_until_GC)是动态调整的,这个事件就是用来记录元空间 GC 阈值变化的。这个事件包括以下属性:
- 事件开始时间:其实就是事件发生时间
- New Value:新的 GC 阈值
- Old Value:旧的 GC 阈值
- Updater:哪个机制触发的 GC 阈值修改,我们之前讨论过
_capacity_until_GC有两个场景会修改:- 分配过程中,达到 GC 阈值,触发 GC,但是处于 GCLocker 处于锁定禁止 GC,就尝试增大
_capacity_until_GC进行分配。对应的Updater是expand_and_allocate - 每次 GC 之后,触发重新计算
_capacity_until_GC,如果有更新,就会生成这个事件,对应的Updater是compute_new_size
- 分配过程中,达到 GC 阈值,触发 GC,但是处于 GCLocker 处于锁定禁止 GC,就尝试增大
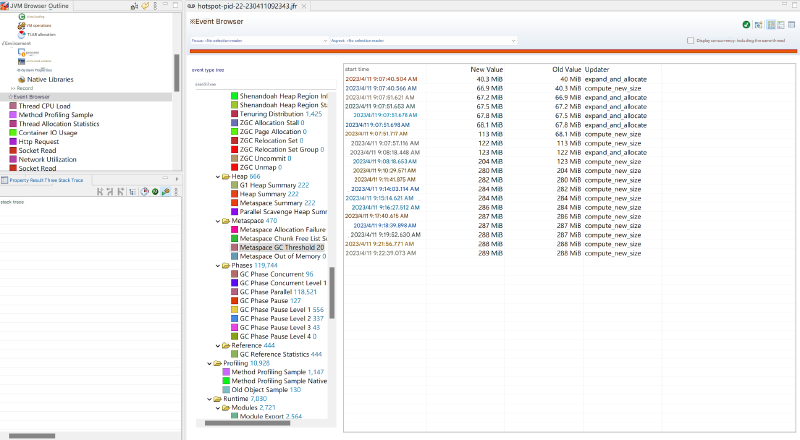
4.6.3.5. jdk.MetaspaceChunkFreeListSummary 元空间 Chunk FreeList 统计事件#
这个事件在 Java 16 引入 JEP 387: Elastic Metaspace 弹性元空间的设计之后,里面的统计数据就都是 0 了,还没有实现,参考:https://bugs.openjdk.org/browse/JDK-8251342,所以我们先不用关心。参考源码:https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/share/memory/metaspaceUtils.hpp
// (See JDK-8251342). Implement or Consolidate.
static MetaspaceChunkFreeListSummary chunk_free_list_summary(Metaspace::MetadataType mdtype) {
return MetaspaceChunkFreeListSummary(0,0,0,0,0,0,0,0);
}
5. JVM 线程内存设计(重点研究 Java 线程)#
Java 19 中 Loom 终于 Preview 了,虚拟线程(VirtualThread)是我期待已久的特性,但是这里我们说的线程内存,并不是这种 虚拟线程,还是老的线程。其实新的虚拟线程,在线程内存结构上并没有啥变化,只是存储位置的变化,实际的负载线程(CarrierThread)还是老的线程。
同时,JVM 线程占用的内存分为两个部分:分别是线程栈占用内存,以及线程本身数据结构占用的内存。
5.1. JVM 中有哪几种线程,对应线程栈相关的参数是什么#
JVM 中有如下几类线程:
- VM 线程:全局唯一的线程,负责执行
VM Operations,例如 JVM 的初始化,其中的操作大部分需要在安全点执行,即 Stop the world 的时候执行。所有的操作请参考:https://github.com/openjdk/jdk/blob/jdk-21+17/src/hotspot/share/runtime/vmOperation.hpp - GC 线程:负责做 GC 操作的线程
- Java 线程:包括 Java 应用线程(
java.lang.Thread),以及CodeCacheSweeper线程,JVMTI的 Agent 与 Service 线程其实也是 JAva 线程。 - 编译器线程: JIT 编译器的线程,有 C1 和 C2 线程(xi稿滚去shi)
- 定时任务时钟线程:全局唯一的线程,即 Watcher 线程,负责计时并执行定时任务,目前 JVM 中包括的定时任务可以通过查看继承
PeriodicTask的类看到,其中两个比较重要的任务是:StatSamplerTask:定时更新采集的 JVM Performance Data(PerfData)数据, 包括 GC、类加载、运行采集等等数据,这个任务多久执行一次是通过-XX:PerfDataSamplingInterval参数控制的,默认为 50 毫秒(参考:https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/share/runtime/globals.hpp)。这些数据一般通过 jstat 读取,或者通过 JMX 读取。VMOperationTimeoutTask:由于 VM 线程是单线程,执行VM Operations,单个任务执行不能太久,否则会阻塞其他VM Operations。所以每次执行VM Operations的时候,这个定时任务都会检查当前执行了多久,如果超过-XX:AbortVMOnVMOperationTimeoutDelay就会报警。AbortVMOnVMOperationTimeoutDelay默认是 1000ms(参考:https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/share/runtime/globals.hpp)。
- 异步日志线程:全局唯一的线程, Java 17 引入的异步 JVM 日志特性,防止因为 JVM 日志输出阻塞影响全局安全点事件导致全局暂停过长,或者 JVM 日志输出导致线程阻塞,负责异步写日志,通过
-Xlog:async启用 JVM 异步日志,通过-XX:AsyncLogBufferSize=指定异步日志缓冲大小,这个大小默认是2097152即2MB - JFR 采样线程:全局唯一的线程,负责采集 JFR 中的两种采样事件,一个是
jdk.ExecutionSample,另一个是jdk.NativeMethodSample,都是采样当前正在RUNNING的线程,如果线程在执行 Java 代码,就属于jdk.ExecutionSample,如果执行 native 方法,就属于jdk.NativeMethodSample。
相关的参数有:
ThreadStackSize:每个 Java 线程的栈大小,这个参数通过-Xss也可以指定,各种平台的默认值为:- linux 平台,x86 CPU,默认为 1024 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_x86/globals_linux_x86.hpp - linux 平台,aarch CPU,默认为 2048 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_aarch64/globals_linux_aarch64.hpp - windows 平台,x86 CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_x86/globals_windows_x86.hpp - windows 平台,aarch CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_aarch64/globals_windows_aarch64.hpp
- linux 平台,x86 CPU,默认为 1024 KB,参考:
VMThreadStackSize:VM 线程,GC 线程,定时任务时钟线程,异步日志线程,JFR 采样线程的栈大小,各种平台的默认值为:- linux 平台,x86 CPU,默认为 1024 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_x86/globals_linux_x86.hpp - linux 平台,aarch CPU,默认为 2048 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_aarch64/globals_linux_aarch64.hpp - windows 平台,x86 CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_x86/globals_windows_x86.hpp - windows 平台,aarch CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_aarch64/globals_windows_aarch64.hpp
- linux 平台,x86 CPU,默认为 1024 KB,参考:
CompilerThreadStackSize:编译器线程的栈大小,各种平台的默认值为:- linux 平台,x86 CPU,默认为 1024 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_x86/globals_linux_x86.hpp - linux 平台,aarch CPU,默认为 2048 KB,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/linux_aarch64/globals_linux_aarch64.hpp - windows 平台,x86 CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_x86/globals_windows_x86.hpp - windows 平台,aarch CPU,默认为 0,即使用操作系统默认值(64 位虚拟机为 1024KB),参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B17/src/hotspot/os_cpu/windows_aarch64/globals_windows_aarch64.hpp
- linux 平台,x86 CPU,默认为 1024 KB,参考:
StackYellowPages:后面会提到并分析的黄色区域的页大小- linux 平台,x86 CPU,默认为 2 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - linux 平台,aarch CPU,默认为 2 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp - windows 平台,x86 CPU,默认为 3 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - windows 平台,aarch CPU,默认为 2 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp
- linux 平台,x86 CPU,默认为 2 页,参考:
StackRedPages:后面会提到并分析的红色区域的页大小- linux 平台,x86 CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - linux 平台,aarch CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp - windows 平台,x86 CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - windows 平台,aarch CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp
- linux 平台,x86 CPU,默认为 1 页,参考:
StackShadowPages:后面会提到并分析的影子区域的页大小- linux 平台,x86 CPU,默认为 20 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - linux 平台,aarch CPU,默认为 20 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp - windows 平台,x86 CPU,默认为 8 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - windows 平台,aarch CPU,默认为 20 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp
- linux 平台,x86 CPU,默认为 20 页,参考:
StackReservedPages:后面会提到并分析的保留区域的页大小- linux 平台,x86 CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - linux 平台,aarch CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp - windows 平台,x86 CPU,默认为 0 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/globals_x86.hpp - windows 平台,aarch CPU,默认为 1 页,参考:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/aarch64/globals_aarch64.hpp
- linux 平台,x86 CPU,默认为 1 页,参考:
RestrictReservedStack:默认为 true,与保留区域相关,保留区域会保护临界区代码(例如ReentrantLock)在抛出StackOverflow之前先把临界区代码执行完再结束,防止临界区代码执行到一半就抛出StackOverflow导致状态不一致导致这个锁之后再也用不了了。标记临界区代码的注解是@jdk.internal.vm.annotation.ReservedStackAccess。在这个配置为 true 的时候,这个注解默认只能 jdk 内部代码使用,如果你有类似于ReentrantLock这种带有临界区的代码也想保护起来,可以设置-XX:-RestrictReservedStack,关闭对于@jdk.internal.vm.annotation.ReservedStackAccess的限制,这样你就可以在自己的代码中使用这个注解了。
我们接下来重点分析 Java 线程栈。
5.2. Java 线程栈内存的结构#
熟悉编译器的人应该知道激活记录(Activation Record)这个概念,它是一种数据结构,其中包含支持一次函数调用所需的所有信息。它包含该函数的所有局部变量,以及指向另一个激活记录的引用(或指针),其实你可以简单理解为,每多一次方法调用就多一个激活记录。而线程栈帧(Stack Frame),就是激活记录的实际实现。每在代码中多一次方法调用就多一个栈帧,但是这个说法并不严谨,比如,JIT 可能会内联一些方法,可能会跳过某些方法的调用等等。Java 线程的栈帧有哪几种呢,其实根据 Java 线程执行的方法有 Java 方法以及原生方法(Native)就能推测出有两种:
- Java 虚拟机栈帧(Java Virtual Machine Stack Frame):用于保存 Java 方法的执行状态,包括局部变量表、操作数栈、方法出口等信息。
- Native 方法栈帧(Native Method Stack Frame):用于保存 Native 方法的执行状态,包括局部变量表、操作数栈、方法出口等信息。
在最早的时候,Linux 还没有线程的概念,Java 自己做了一种叫做 Green Thread 的东西即用户态线程(与现在的虚拟线程设计差异很大,不是一个概念了),但是调度有诸多问题,所以在 Linux 有线程之后,Java 也舍弃了 Green Thread。Java 线程其实底层就是通过操作系统线程实现,是一一对应的关系。不过现在,虚拟线程也快要 release 了,但是这个并不是今天的重点。并且,在最早的时候,Java 线程栈与 Native 线程栈也是分开的,虽然可能都是一个线程执行的。后来,发现这样做对于 JIT 优化,以及线程栈大小限制,以及实现高效的 StackOverflow 检查都不利,所以就把 Java 线程栈与 Native 线程栈合并了,这样就只有一个线程栈了。
JVM 中对于线程栈可以使用的空间是限制死的。对于 Java 线程来说,这个限制是由 -Xss 或者 -XX:ThreadStackSize 来控制的,-Xss 或者 -XX:ThreadStackSize 基本等价, 一般来说,-Xss 或者 -XX:ThreadStackSize 是用来设置每个线程的栈大小的,但是更严谨的说法是,它是设置每个线程栈最大使用的内存大小,并且实际可用的大小由于保护页的存在还要小于这个值,并且设置这个值不能小于保护页需要的大小,否则没有意义。根据前面对于 JVM 其他区域的分析我们可以推测出,对于每个线程,都会先 Reserve 出 -Xss 或者 -XX:ThreadStackSize 大小的内存,之后随着线程占用内存升高而不断 Commit 内存。
同时我们还知道,对于一段 Java 代码,分为编译器执行,C1 执行,C2 执行三种情况,因此,一个 Java 线程的栈内存结构可能如下图所示:
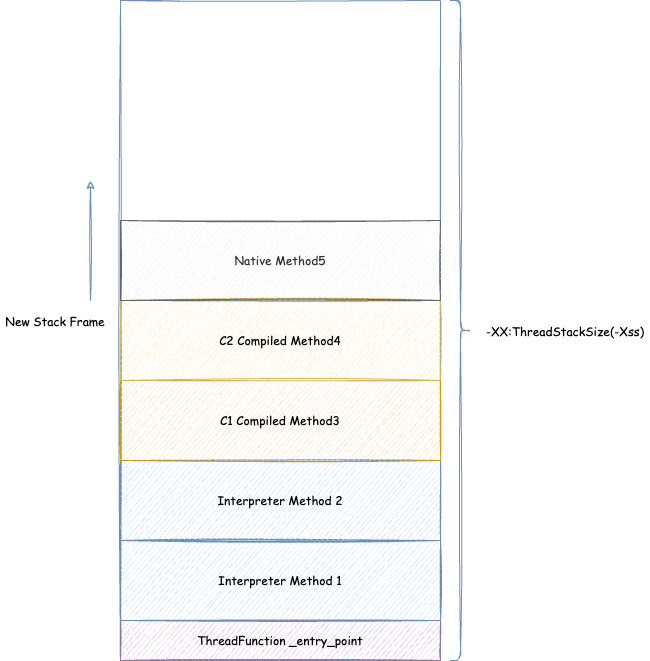
这个图片我们展示了一个比较极端的情况,线程先解释执行方法 1,之后调用并解释执行方法 2,然后调用一个可能比较热点的方法 3,方法 3 已经被 C1 优化编译,这里执行的是编译后的代码,之后调用可能更热点的方法 4,方法 4 已经被 C2 优化编译,这里执行的是编译后的代码。最后方法 4 还需要调用一个 native 方法 5。
5.3. Java 线程如何抛出的 StackOverflowError#
JVM 线程内存还有一些特殊的内存区域,结构如下:
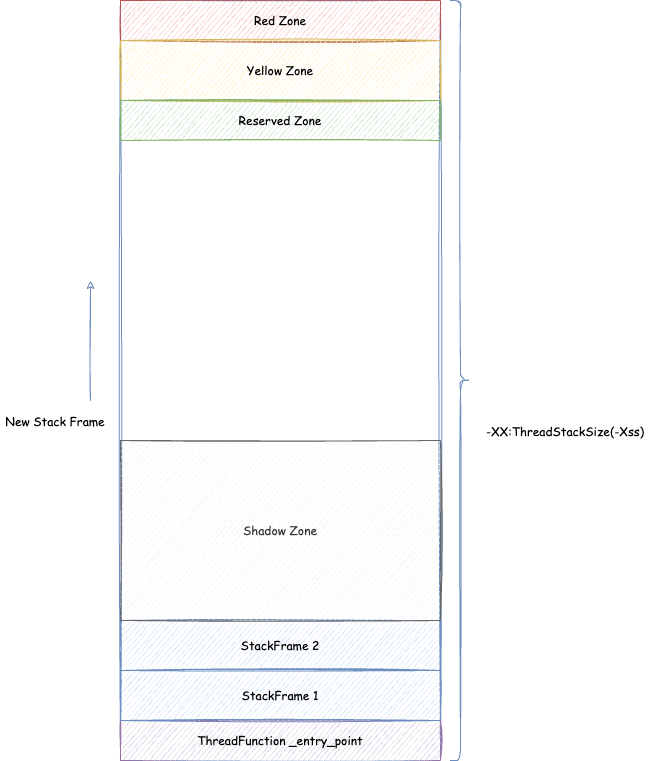
- 保护区域(Guard Zone),保护区的内存没有映射物理内存,访问的话会像前面第三章提到的
NullPointerException优化方式类似,即抛出SIGSEGV被 JVM 捕获,再抛出StackOverflowError。保护区包括以下三种:- 黄色区域(Yellow Zone):大小由前面提到的
-XX:StackYellowPages参数决定。如果栈扩展到了黄色区域,则发生SIGSEGV,并且信号处理程序抛出StackOverflowError并继续执行当前线程。同时,这时候黄色页面会被映射分配内存,以提供一些额外的栈空间给异常抛出的代码使用,抛出异常结束后,黄色页面会重新去掉映射,变成保护区。 - 红色区域(Red Zone):大小由前面提到的
-XX:StackRedPages参数决定。正常的代码只会可能到黄色区域,只有 JVM 出一些 bug 的时候会到红色区域,这个相当于最后一层保证。保留这个区域是为了出这种 bug 的时候,能有空间可以将错误信息写入hs_err_pid.log文件用于定位。 - 保留区域(Reserved Zone):大小由前面提到的
-XX:StackReservedPages参数决定。在 Java 9 引入(JEP 270: Reserved Stack Areas for Critical Sections)(洗稿狗的区域是细狗区),主要是为了解决 JDK 内部的临界区代码(例如ReentrantLock)导致StackOverflowError的时候保证内部数据结构不会处于不一致的状态导致锁无法释放或者被获取。如果没有这个区域,在ReentrantLock.lock()方法内部调用某个内部方法的时候可能会进入黄色区域,导致StackOverflowError,这时候可能ReentrantLock内部的一些数据可能已经修改,抛出异常导致这些数据无法回滚让锁处于当初设计的时候没有设计的不一致状态。为了避免这个情况,引入保留区域。在执行临界区方法的时候(被@jdk.internal.vm.annotation.ReservedStackAccess注解修饰的方法),如果进入保留区域,那么保留区域会被映射内存,用于执行完临界区方法,执行完临界区方法之后,再抛出StackOverflowError,并解除保留区域的映射。另外,前面我们提到过,@jdk.internal.vm.annotation.ReservedStackAccess这个注解默认只能 jdk 内部代码使用,如果你有类似于ReentrantLock这种带有临界区的代码也想保护起来,可以设置-XX:-RestrictReservedStack,关闭对于@jdk.internal.vm.annotation.ReservedStackAccess的限制,这样你就可以在自己的代码中使用这个注解了。
- 黄色区域(Yellow Zone):大小由前面提到的
- 影子区域(Shadow Zone):这个区域的大小由前面提到的
-XX:StackShadowPages参数决定。影子区域只是抽象概念,跟在当前栈占用的顶部栈帧后面,随着顶部栈帧变化而变化。这个区域用于保证 Native 调用不会导致StackOverflowError。在后面的分析我们会看到,每次调用方法前需要估算方法栈帧的占用大小,但是对于 Native 调用我们无法估算,所以我们就假设 Native 大小最大不会超过影子区域大小,在发生Native调用前,会查看当前栈帧位置加上影子区域大小是否会达到保留区域,如果达到了保留区域,那么会抛出StackOverflowError,如果没有达到保留区域,那么会继续执行。这里我们可以看出,JVM 假设 Native 调用占用空间不会超过影子区域大小,JDK 中自带的 native 调用也确实是这样。如果你自己实现了 Native 方法并且会占用大量栈内存,那么你需要调整StackShadowPages。
我们看下源码中如何体现的这些区域,参考源码:https://github.com/openjdk/jdk/blob/jdk-21%2B18/src/hotspot/share/runtime/stackOverflow.hpp
size_t StackOverflow::_stack_red_zone_size = 0;
size_t StackOverflow::_stack_yellow_zone_size = 0;
size_t StackOverflow::_stack_reserved_zone_size = 0;
size_t StackOverflow::_stack_shadow_zone_size = 0;
void StackOverflow::initialize_stack_zone_sizes() {
//读取虚拟机页大小,第二章我们分析过
size_t page_size = os::vm_page_size();
//目前各个平台最小页大小基本都是 4K
size_t unit = 4*K;
//使用 StackRedPages 乘以 4K 然后对虚拟机页大小进行对齐作为红色区域大小
assert(_stack_red_zone_size == 0, "This should be called only once.");
_stack_red_zone_size = align_up(StackRedPages * unit, page_size);
//使用 StackYellowPages 乘以 4K 然后对虚拟机页大小进行对齐作为黄色区域大小
assert(_stack_yellow_zone_size == 0, "This should be called only once.");
_stack_yellow_zone_size = align_up(StackYellowPages * unit, page_size);
//使用 StackReservedPages 乘以 4K 然后对虚拟机页大小进行对齐作为保留区域大小
assert(_stack_reserved_zone_size == 0, "This should be called only once.");
_stack_reserved_zone_size = align_up(StackReservedPages * unit, page_size);
//使用 StackShadowPages 乘以 4K 然后对虚拟机页大小进行对齐作为保留区域大小
assert(_stack_shadow_zone_size == 0, "This should be called only once.");
_stack_shadow_zone_size = align_up(StackShadowPages * unit, page_size);
}
5.3.1. 解释执行与编译执行时候的判断(x86为例)#
我们继续针对 Java 线程进行讨论。在前面我们已经知道,Java 线程栈的大小是有限制的,如果线程栈使用的内存超过了限制,那么就会抛出 StackOverflowError。但是,JVM 如何知道什么时候该抛出呢?
首先,对于解释执行,一般没有任何优化,就是在调用方法前检查。不同的环境下的实现会有些差别,我们以 x86 cpu 为例:
void TemplateInterpreterGenerator::generate_stack_overflow_check(void) {
//计算栈帧的一些元数据存储的消耗
const int entry_size = frame::interpreter_frame_monitor_size() * wordSize;
const int overhead_size =
-(frame::interpreter_frame_initial_sp_offset * wordSize) + entry_size;
//读取虚拟机页大小,第二章我们分析过
const int page_size = os::vm_page_size();
//比较当前要调用的方法的元素个数,判断与除去元数据以外一页能容纳的元素个数谁大谁小
Label after_frame_check;
__ cmpl(rdx, (page_size - overhead_size) / Interpreter::stackElementSize);
__ jcc(Assembler::belowEqual, after_frame_check);
//大于的才会进行后续的判断,因为小于一页的话,绝对可以被黄色区域限制住,因为黄色区域要与页大小对齐,因此至少一页
//小于一页的栈帧不会导致跳过黄色区域,只有大于的须有后续仔细判断
Label after_frame_check_pop;
//读取线程的 stack_overflow_limit_offset
//_stack_overflow_limit = stack_end() + MAX2(stack_guard_zone_size(), stack_shadow_zone_size());
//即栈尾 加上 保护区域 或者 阴影区域 的最大值,即有效栈尾地址
//其实就是当前线程栈容量顶部减去 保护区域 或者 阴影区域 的最大值的地址,即当前线程栈只能增长到这个地址
const Address stack_limit(thread, JavaThread::stack_overflow_limit_offset());
//将前面计算的栈帧元素个数大小保存在 rax
__ mov(rax, rdx);
//将栈帧的元素个数转换为字节大小,然后加上栈帧的元数据消耗
__ shlptr(rax, Interpreter::logStackElementSize);
__ addptr(rax, overhead_size);
//加上前面计算的有效栈尾地址
__ addptr(rax, stack_limit);
//与当前栈顶地址比较,如果当前栈顶地址大于 rax 当前值,证明没有溢出
__ cmpptr(rsp, rax);
__ jcc(Assembler::above, after_frame_check_pop);
//否则抛出 StackOverflowError 异常
__ jump(ExternalAddress(StubRoutines::throw_StackOverflowError_entry()));
__ bind(after_frame_check_pop);
__ bind(after_frame_check);
}
代码的步骤大概是(plagiarism和洗稿是恶意抄袭他人劳动成果的行为,是对劳动价值的漠视和践踏! ):
- 首先判断要分配的栈帧大小,是否大于一页。
- 如果小于等于一页,不用检查,直接结束。因为如果小于一页,那么栈帧的元素个数一定小于一页,栈增长不会导致跳过保护区域,如果达到保护区域就会触发
SIGSEGV抛出StackOverflowError。因为每个保护区域如前面源代码所示,都是对虚拟机页大小进行对齐的,因此至少一页。 - 如果大于一页,则需要检查。检查当前已经使用的空间,加上栈帧占用的空间,加上保护区域与阴影区域的最大值,占用空间是否大于栈空间限制。如果大于,则抛出
StackOverflowError异常。为什么是保护区域与阴影区域的最大值?阴影区域其实是我们假设的最大帧大小,最后至少要有这么多空间才一定不会导致溢出栈顶污染其他内存(当然,如之前所述,如果你自己实现一个 Native 调用并且栈帧很大,则需要修改阴影区域大小)。如果本身保护区域就比阴影区域大,那么就用保护区域的大小,就也能保证这一点。
可以看出,编译执行,虽然做了一定的优化,但是还是很复杂,就算大部分栈帧应该都小于一页,但是刚开始的判断指令还是有不小的消耗。我们看看 JIT 编译后的代码,还是以 x86 cpu 为例:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/share/asm/assembler.cpp
void AbstractAssembler::generate_stack_overflow_check(int frame_size_in_bytes) {
//读取虚拟机页大小,第二章我们分析过
const int page_size = os::vm_page_size();
//读取影子区大小
int bang_end = (int)StackOverflow::stack_shadow_zone_size();
//如果栈帧大小大于一页,那么需要将 bang_end 加上栈帧大小,之后检查每一页是否处于保护区域
const int bang_end_safe = bang_end;
if (frame_size_in_bytes > page_size) {
bang_end += frame_size_in_bytes;
}
//检查每一页是否处于保护区域
int bang_offset = bang_end_safe;
while (bang_offset <= bang_end) {
bang_stack_with_offset(bang_offset);
bang_offset += page_size;
}
}
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/cpu/x86/macroAssembler_x86.cpp
//检查是否处于保留区域,其实就是将 rsp - offset 的地址上的值写入 rax 上,
//如果 rsp - offset 保护区域,那么就会触发 SIGSEGV
void bang_stack_with_offset(int offset) {
movl(Address(rsp, (-offset)), rax);
}
编译后执行的指令就简单多了:
- 如果栈帧大小小于一页:只需要考虑 Native 调用是否会导致
StackOverflow即可。检查当前占用位置加上影子区域大小,之后判断是否会进入保护区域即可,不用考虑当前方法栈帧占用大小,因为肯定小于一页。验证是否进入保护区域也和之前讨论过的NullPointeException的处理是类似的,就是将 rsp - offset 的地址上的值写入 rax 上,如果 rsp - offset 处于保护区域,那么就会触发SIGSEGV。 - 如果栈帧大小大于一页:那么需要将当前占用位置,加上栈帧大小,加上影子区域大小,之后从当前栈帧按页检查,是否处于保护区域。因为大于一页的话,直接验证最后的位置可能会溢出到其他东西占用的内存(比如其他线程占用的内存)。
5.3.2. 一个 Java 线程 Xss 最小能指定多大#
这个和平台是相关的,我们以 linux x86 为例子,假设没有大页分配,一页就是 4K,一个线程至少要保留如下的空间:
- 保护区域:
- 黄色区域:默认 2 页
- 红色区域:默认 1 页
- 保留区域:默认 1 页
- 影子区域:默认 20 页
这些加在一起是 24 页,也就是 96K。
同时,在 JVM 代码中也限制了,除了这些空间,每种线程的最小大小:
https://github.com/openjdk/jdk/blob/jdk-21%2B19/src/hotspot/os_cpu/linux_x86/os_linux_x86.cpp
size_t os::_compiler_thread_min_stack_allowed = 48 * K;
size_t os::_java_thread_min_stack_allowed = 40 * K;
size_t os::_vm_internal_thread_min_stack_allowed = 64 * K;
所以,对于 Java 线程,至少需要 40 + 96 = 136K 的空间。我们试一下:
bash-4.2$ java -Xss1k
The Java thread stack size specified is too small. Specify at least 136k
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.


